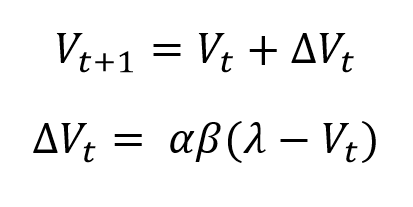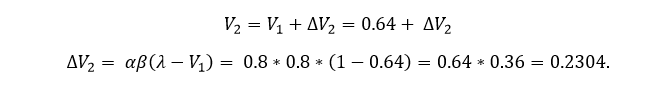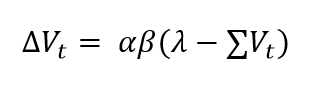¡Estamos de vuelta! Vamos a seguir con esta serie de posts analizando todas esas prácticas estadísticas que, queramos o no, acabamos haciendo mal. Hoy vamos a recuperar dos conceptos ya tratados, la falta de potencia estadística y el sesgo de publicación, para preguntarnos: ¿podrían estos dos factores, conspirando juntos, cargarse completamente la literatura publicada? ¿Deberíamos poner toda nuestra confianza y fe en los famosos meta-análisis (combinaciones de múltiples estudios)? Os lo cuento.
Simulando una literatura con baja potencia
El primero de los conceptos que tenemos que refrescar es el de potencia estadística. Lo hemos comentado ya en un par de post anteriores en la serie sobre estadística visual (aquí y aquí), pero os lo recuerdo: la potencia estadística es la probabilidad de que mi estudio encuentre un resultado significativo, sabiendo que el efecto que busco es real. Es decir, si por ejemplo asumo que las mascarillas de tela pueden reducir la tasa de infección por el SARS-COV19, un estudio con una potencia del 0.50 (50%) sólo podría detectar un resultado significativo la mitad de las veces. Por eso generalmente queremos potencias altas, lo que implica, entre otras cosas, trabajar con muestras grandes. El beneficio añadido de tener muestras grandes es que reducimos el impacto del error de muestreo (como vimos en este otro post), mejorando la precisión de nuestras estimaciones.
Además, la potencia debe ir en consonancia con el tamaño del efecto que estoy buscando, como ya expliqué. Si busco un efecto pequeño, necesito que el estudio tenga mucha potencia (muestras grandes, mediciones precisas), o de lo contrario no podré detectarlo, es decir, no tendré resultados significativos, a pesar de que el efecto sea real.
Lo lógico sería, entonces, que los investigadores diseñáramos experimentos de alta potencia, para asegurarnos de captar los efectos que buscamos aunque sean pequeños, y de paso mejorar nuestras estimaciones. Lo que pasa es que un estudio grande y potente es también costoso. Como resultado, en algunas áreas de la ciencia tenemos un déficit sistemático de potencia. Por poner un ejemplo, usar muestras de unas pocas docenas de participantes sigue siendo relativamente habitual en campos como la nutrición deportiva o la neuroimagen. Esto implica que la gran mayoría de los estudios que se hacen en estas áreas producen (en principio) resultados nulos, no significativos. Pero, ¿qué consecuencias tiene esto para ti, que estás documentándote y leyendo papers para preparar tu TFG o TFM? ¿Cómo puede la baja potencia contaminar la literatura e impedir que tus conclusiones sean correctas?
Ya sabéis que una de las técnicas que más me gustan para aprender de estadística es la simulación: utilizar programas informáticos para representar escenarios posibles, cambiar sus parámetros, y ver cómo esto les va afectando. De modo que voy a reciclar un código de R que vimos en un post anterior para imaginar qué pasaría si, en un área concreta de la investigación, hubiera un déficit de potencia sistemático como el que he descrito. Vamos al lío.
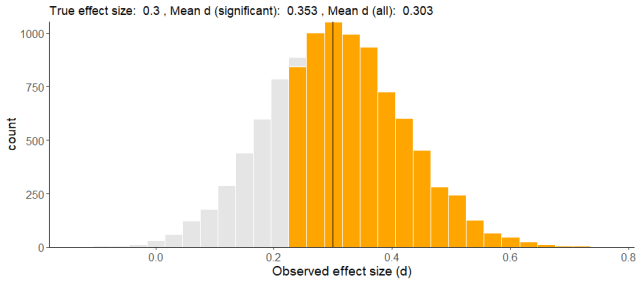
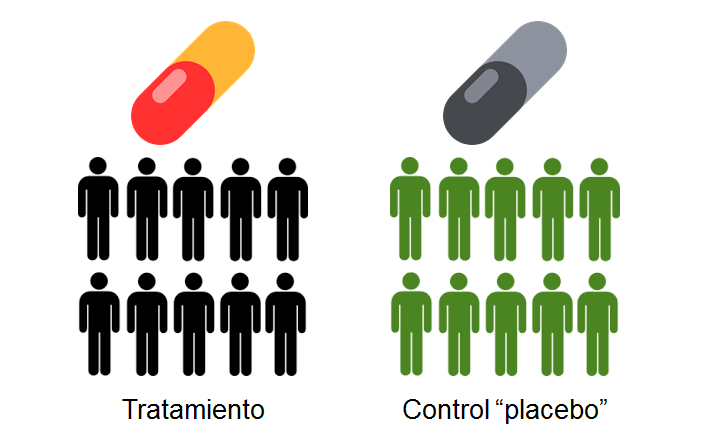
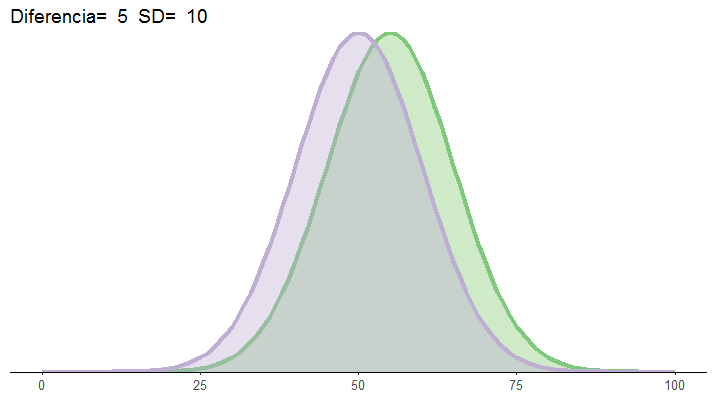
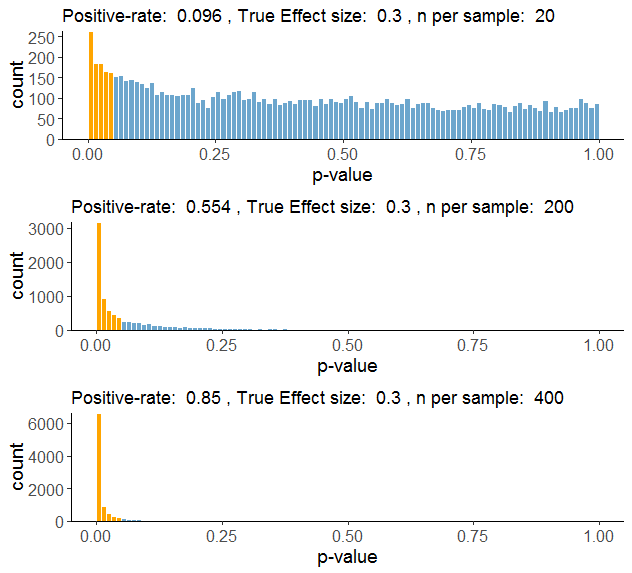
He simulado 10.000 estudios aleatorios que investigan un mismo efecto. Este efecto es real, y tiene un tamaño del efecto poblacional de d=0.3, es decir, un efecto pequeño a moderado. Os recuerdo que en la realidad no podríamos conocer este dato, ¡es lo bueno que tienen las simulaciones, que me lo puedo inventar! Cada estudio tiene una muestra que a priori es poco potente: N = 20 (comparamos dos grupos de 10 personas).
Este gráfico, como ya os he contado otras veces, es la distribución de los 10.000 p-valores que he calculado. Solamente una porción de los estudios, marcada en naranja, ha producido un resultado significativo (p < 0.05). En este caso, alrededor un 10% de los resultados son significativos, lo que implica que en esta simulación hemos encontrado una potencia de aproximadamente el 10%, o 0.1. ¡Una birria! ¡Un derroche!
Primera moraleja: Si leéis un estudio donde dicen que el tamaño del efecto es de d=0.3 o menor, y la muestra es de N=20 o menor… O bien han tenido una suerte increíble (solo un 10% de los estudios deberían dar resultado significativo), o bien se están callando los otros 9 estudios donde el resultado no era significativo. O bien… hay algo raro.
Bueno, alguno estará pensando, ¿y qué si se están derrochando los recursos en hacer estudios poco potentes? Siguen siendo estudios válidos, pueden aportar información. Sí, claro, es cierto. Pero con matices. En primer lugar, antes os comenté que los estudios con baja potencia también producen estimaciones poco precisas de los efectos. Por ejemplo, en nuestras simulaciones sabemos que el efecto real es d=0.3, y efectivamente, el efecto promedio observado en los 10.000 estudios se acerca mucho a ese valor, ¡pero con mucha dispersión! Veis que hay muchos estudios con estimaciones del tamaño del efecto de d>1, o incluso cercanos a d=2… Y también un número nada despreciable de estudios que se equivocan en el signo, es decir, estiman efectos negativos, que indicarían una diferencia entre grupos, pero en la dirección contraria, como por ejemplo, encontrar que usar la mascarilla facilita la propagación del virus. ¿Lo veis?
De nuevo, podemos tener a algún escéptico moviendo la cabeza, pensando “¿Y qué más da? Lo importante es que los estudios no están sesgados, simplemente carecen de precisión por tener muestras pequeñas”. Y es cierto, tiene razón: el promedio del efecto que hemos observado en nuestros 10.000 estudios (punto blanco en la figura) se acerca mucho al valor real (línea vertical). Además, contamos con una herramienta que nos permite agregar múltiples estudios en uno solo, para estimar el tamaño del efecto combinado, la técnica conocida como “meta-análisis”. Podríamos hacer meta-análisis y simplemente no confiar demasiado en los estudios aislados. ¡Caso cerrado!
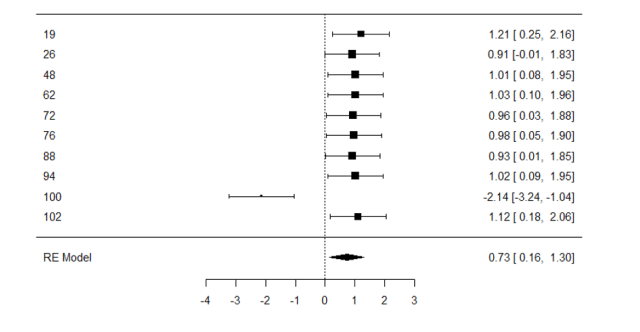
De hecho, a modo de experimento, aquí tenemos un meta-análisis con los primeros 10 estudios de esta simulación. La estimación del efecto, que se representa con ese diamante que veis ahí, se acerca mucho a la d=0.3, que sabemos que es el valor correcto. Lo que pasa es que hay tanto ruido en los datos, tan poca precisión, que ni agregando 10 estudios conseguimos que sea significativo.
Pero incluso este escenario peca de optimista. Y lo es porque la literatura publicada no tiene el aspecto que os estoy enseñando en estas figuras, debido a un proceso conocido como publicación selectiva, o sesgo de publicación, del que ya hablé en el anterior post. En pocas palabras: el sesgo de publicación consiste en que determinados resultados tienen más facilidad que otros de verse publicados. Por ejemplo, los estudios con resultados significativos o que encajan con las teorías y expectativas actuales se publican más fácilmente que los estudios no concluyentes o que no producen resultados significativos.
Entonces, ¿qué pasa si tenemos un montón de estudios de baja potencia, y ahora seleccionamos sólo los positivos para que se publiquen? ¿Puede eso sesgar, y por lo tanto contaminar la literatura? ¡Claramente sí!
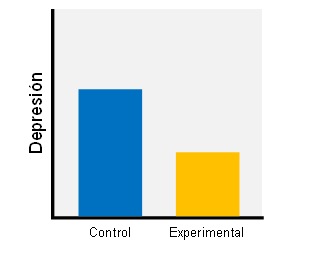
En esta figura, volvemos a representar los tamaños del efecto observados en nuestras simulaciones, sólo que ahora he marcado en amarillo los resultados significativos y que van en la dirección esperada (positivos). Como podéis comprobar, aunque el promedio de efectos observados de *todos* los estudios sea bastante correcto, cuando sólo consideramos los significativos estamos inflando enormemente nuestra estimación: nos da una d promedio de casi 1.2, quees un tamaño INMENSO. Para que os hagáis una idea, la diferencia de estatura promedio entre hombres y mujeres viene a ser de d=1, así que este efecto que hemos detectado es más grande, y a todas luces falso.
¿Cuáles son las consecuencias de tener una literatura repleta de efectos inflados? La primera ya la hemos dicho: los meta-análisis van a dejar de ser tan útiles para poner algo de orden. Ved lo que ocurre cuando aplicamos el meta-análisis a lo loco y sin pensar sobre algunos de los estudios que han sido significativos. Ahora el meta-análisis es significativo, y ofrece un tamaño del efecto exagerado, que duplica con creces el valor real. Por eso nunca os creáis un meta-análisis que no incorpore algún tipo de corrección para el sesgo de publicación. Agregar docenas, o incluso cientos, de efectos sesgados solo produce conclusiones también sesgadas. Cuidadín.
Sigamos con el escepticismo: ¿es tan grave que los tamaños del efecto estén sobrestimados? Quiero decir, leyendo esta literatura, me queda claro que el efecto existe, o sea, que usar mascarillas reduce la propagación del virus. Simplemente tengo que ignorar la magnitud del efecto, porque por culpa de la baja potencia y del sesgo de publicación, este no es fiable. ¿Podría valer así?
Bueno, pues de nuevo, no es una opción muy recomendable en la práctica. ¿Recordáis que os hablé del “análisis de potencia a priori”? En teoría, los investigadores diseñamos nuestros estudios para que tengan potencia óptima, y esto implica basarse en la literatura para tener una idea de cuál puede ser el tamaño del efecto que estoy buscando. Pero claro, si la literatura me ofrece efectos inflados, multiplicados varias veces por su tamaño real, me está condenando a diseñar sistemáticamente estudios de baja potencia, en la creencia de que las muestras pequeñas son suficientes. O sea, que la situación nos mete en un círculo vicioso: como los estudios son de baja potencia y sólo publicamos los que exageran la estimación, seguiremos haciendo estudios con muestras insuficientes.
Arreglando el mundo: potencia aceptable
Otro aspecto bueno que tienen las simulaciones es que, con ellas, es muy fácil “arreglar el mundo” y ver qué pasaría si hiciéramos las cosas bien. Ojalá en la vida real fuera tan sencillo. Vamos a ver qué ocurre cuando los estudios tienen buena potencia, muestras grandes, mediciones precisas…
Repetimos las simulaciones: de nuevo, 10.000 estudios sobre un efecto pequeño, d=0.3, pero ahora con muestras grandes, N = 300 (150 en cada grupo).
¡Cómo ha cambiado la cosa! Ahora un 75% de los estudios tienen resultados significativos, es decir, hemos incrementado la potencia al 75%, que ya empieza a ser un valor aceptable.
Bueno, y las estimaciones del tamaño del efecto, ¿habrán mejorado en precisión? Pues claro que sí: como veis, ahora el rango de valores es bastante más estrecho. No se ven muchos estudios sobrestimando groseramente el efecto, como antes:
¿Y qué pasa con el sesgo de publicación? ¿Seguirá estropeando las estimaciones? Podemos ver que ahora su efecto es bastante menos pernicioso: el efecto se “hincha” un poco cuando sólo miramos los resultados significativos, pero mucho menos que en el escenario de baja potencia que habíamos visto antes.
El motivo es que, cuando la muestra es pequeña (baja potencia), hace falta observar un efecto muy grande para que el resultado salga significativo. Así que, si solo se publican los resultados significativos, estamos basando nuestras conclusiones en esos pocos estudios con observaciones más extremas y exageradas.
Conclusiones
Si has acabado este post, enhorabuena por tu paciencia. Con un poco de suerte, habrás llegado a la conclusión de que, una vez más, tenemos que ser críticos con la literatura publicada. Generalmente, los efectos que se publican en áreas donde las muestras son poco potentes (ya sabéis, N = 15, N = 20…) están hinchados y no hay que tomarlos muy en serio, ni siquiera en un meta-análisis. Afortunadamente, hoy en día existen técnicas para estimar la magnitud de la distorsión introducida por el sesgo de publicación. Si lees un meta-análisis y no dice cómo ha tomado en cuenta la publicación selectiva de resultados… mala cosa.
Ahora que todo el mundo está confinado en casa por culpa de un peligroso bicho, he pensado que era buen momento para recuperar el blog, sobre todo porque la ansiedad del momento no me permite concentrarme en otras cosas. Esta vez voy a hablar de algo un poco diferente. Mi plan es demostraros, con un par de simulaciones de R, por qué no podemos creer una parte apreciable de la literatura científica publicada. ¿Quiere esto decir que los científicos/as están mintiendo? No exactamente, como veremos. Vamos allá.
Cuatro tipos de resultado
Para hacer nuestras simulaciones, voy a tener que crear un modelo que represente el proceso que estamos intentando describir, en este caso, el de publicación de un artículo científico. Lo primero que tenemos que hacer es considerar que cuando los investigadores/as realizamos un estudio, generalmente estamos poniendo a prueba una hipótesis. Por ejemplo: ¿Correlacionarán la ansiedad académica y el estrés en los estudiantes? ¿Funcionará este nuevo fármaco para tratar la diabetes? En cualquiera de estos casos, los investigadores hacen una predicción (la correlación entre ansiedad y estrés es mayor de cero, el fármaco reduce los síntomas de la enfermedad con respecto a un control…) que es puesta a prueba en el estudio, mediante un conjunto de técnicas que llamamos “contraste de hipótesis”, o “contraste de significación para la hipótesis nula” (NHST, por sus siglas en inglés). La lógica del NHST la hemos cubierto ya en un post previo, que tenéis aquí.
Por abreviar, en el estudio se obtiene un estadístico, llamado “p-valor”, que nos indica cómo de improbable es el resultado observado si asumimos que la hipótesis nula es cierta, es decir, que el resultado se debe únicamente al azar. Si el resultado del estudio es significativo (generalmente, p < 0.05), rechazaremos provisionalmente la hipótesis nula. Si el resultado no es significativo (p > 0.05), diremos que no podemos descartar que la hipótesis nula sea cierta, es decir, que no podemos decir que el resultado no se deba enteramente al azar. Fijaos en un detalle curioso: en este proceso, en ningún momento se habla directamente de la hipótesis que tenía el investigador en mente, conocida como la hipótesis alternativa. Simplemente se toma una decisión sobre si descartar o no la hipótesis nula para un estudio concreto.
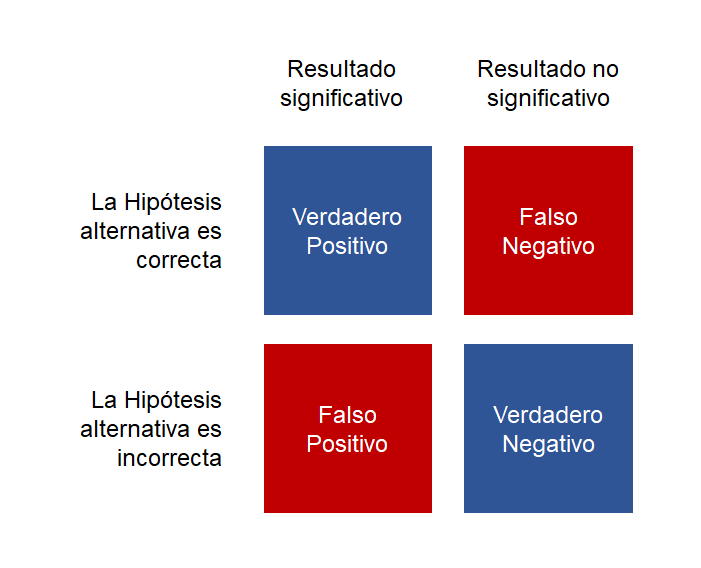
Lo que pasa es que, como vimos en un post previo, el error de muestreo es bastante traicionero, y puede conseguir que, por puro azar, observemos resultados en nuestra muestra que no se corresponden con la realidad (con la población). Así que la situación quedaría recogida en una tabla como esta:
Los cuatro tipos de resultado que puedes encontrar en un estudio científico.
Dado que la hipótesis que plantea el investigador puede ser correcta o incorrecta, tenemos dos formas de acertar y dos formas de equivocarnos: si la hipótesis alternativa era correcta y el p-valor significativo, estamos ante un “verdadero positivo”. Por el contrario, si la hipótesis alternativa era correcta, pero el p-valor no era significativo, estamos ante un “falso negativo”, o “error Tipo II”. Un “falso positivo”, también conocido como “error Tipo I”, aparecerá cuando nuestra hipótesis de partida era incorrecta, pero nuestro resultado es significativo. Por último, si nuestra hipótesis era incorrecta y el p-valor es no significativo, habremos dado con un verdadero negativo. En total, cuatro tipos de resultado que nos podemos encontrar en cualquier estudio que emplee contraste de hipótesis.
Ahora vamos a plantearnos en qué proporciones se distribuyen en la literatura publicada estos cuatro tipos de resultado. Idealmente, para que fuera plenamente fiable, querríamos que la literatura contuviese cuantos más verdaderos positivos y negativos mejor, y nos gustaría que no tuviera mucha representación de falsos resultados, ¿verdad? En otras palabras, querríamos que el proceso de publicación actuase como un filtro que dejase pasar solo los resultados verdaderos. Ya veremos que eso entra en el terreno de la utopía…
El proceso de publicación en un mundo ideal
Vamos a empezar a simular el proceso de publicación con R. Para ello, tenemos que definir un modelo que nos permita saber qué estudios se van a publicar y qué estudios no. Evidentemente, el modelo será una simplificación muy burda de la realidad, mucho más compleja, pero estamos aquí para aprender y reflexionar…
Comencemos planteándonos qué porcentaje de las hipótesis que los científicos y científicas se plantean son correctas. Podría ser razonable asumir que en algunas áreas los expertos tienen una capacidad predictiva con alta precisión, de forma que prácticamente sólo plantean hipótesis correctas. Sin embargo, en el contexto de la psicología, donde no tenemos teorías bien desarrolladas y aún discrepamos en asuntos fundamentales (como el de la medición, o incluso el objeto de estudio), creo que es más sensato admitir que, muy a menudo, los investigadores plantean hipótesis que no se corresponden con la realidad. En principio esto no tiene nada de malo, puesto que así también se puede avanzar: basta con hacer estudios y comprobar que estas hipótesis incorrectas no acumulan evidencia a su favor.
En resumen, y siendo generosos, vamos a asumir que la probabilidad de atinar con una hipótesis correcta es de 0.6 (es decir, el 60% de las veces que planteamos una nueva hipótesis, esta es cierta).
A continuación, ¿cuál será la probabilidad de obtener un resultado significativo? Dependerá, lógicamente, de si la hipótesis planteada es cierta o no. Si es cierta, debería ser más fácil encontrar un p-valor que la sostenga. En concreto, si la hipótesis en cierta, la probabilidad de obtener un resultado significativo se llama potencia estadística. Si necesitas refrescar este concepto, no te preocupes, repasa este post previo. Por convención, se dice que un valor aceptable de potencia estadística no debe ser inferior a 0.8. Es decir, deberíamos diseñar nuestros estudios de manera que, si de verdad el efecto que buscamos existe, lo encontremos el 80% de las veces.
¿Cuál es la probabilidad de obtener un falso positivo? En este caso es también una cantidad conocida. Cuando planteamos una hipótesis incorrecta (es decir, un efecto que no existe realmente), imponemos un criterio para que el error Tipo I (falso positivo) no ocurra más del 5% de las veces (revísalo en este post si te hace falta). Por lo tanto, la probabilidad de este tipo de resultado es 0.05, ó 5%.
Ahora continuamos. El estudio está realizado, y el análisis ha sido significativo o no. Queda la tarea de escribirlo e intentar publicarlo en una revista. Es bien conocido que este proceso no es del todo neutral, pues se ha documentado la presencia de sesgos de publicación. Fundamentalmente, existe un sesgo a favor de los resultados significativos. Es decir, a las editoriales no les gusta publicar resultados no concluyentes, o no significativos. Esto quiere decir que es más fácil publicar un resultado significativo (sea auténtico o falso) que uno resultado no significativo. Así nace también el concepto del “cajón de los fracasos”, conocido como “the file drawer problem”: una buena parte de los resultados, sea por no ser significativos o por otros motivos, acaban sin publicarse. Esto quiere decir que echamos a perder muchísima información que podría ser valiosa, junto con otra que no.
Para modelar este sesgo de publicación, vamos a asumir que el 50% de los resultados significativos se publican, pero solo el 1% de los resultados no significativos, independientemente de que sean resultados verdaderos o falsos. En este caso, los números me los he inventado, pero podrían ser una opción razonable (agradecería comentarios, es fácil rehacer la simulación con otros valores de partida).
Ya tenemos todos los elementos que componen nuestro proceso (simulado) de publicación, de forma que podemos averiguar cómo de probable es que cada uno de los cuatro tipos de resultado de la tabla acabe publicado en la literatura.
Aquí tenéis el código de R que permite hacer la simulación completa. En cada paso del proceso, utilizamos una distribución binomial para decidir si el estudio sale significativo o no, o se publica o no:
H <- 0.6 #probabilidad de proponer una H correcta.
power <- 0.8 #probabilidad de detectar un efecto que existe.
alpha <- 0.05 #probabilidad de detectar un efecto que no existe.
PubPos <- 0.5 #Probabilidad de publicar un resultado significativo.
PubNull <- 0.01 #Probabilidad de publicar un resultado no significativo.
nSims <- 10000 #Número de simulaciones.
sims <- data.frame(H = rbinom(nSims, 1, H))
sims<-
sims %>%
mutate(PSig = (H*power)+((1-H)*alpha)) %>%
mutate(Sig = rbinom(nSims, 1, PSig)) %>%
mutate(tipo =
ifelse((H==1)&(Sig==1), "True Positive",
ifelse((H==1)&(Sig==0), "False Negative",
ifelse((H==0)&(Sig==1), "False Positive",
ifelse((H==0)&(Sig==0), "True Negative", NA
))))) %>%
mutate(Publish = rbinom(nSims, 1, ((Sig*PubPos)+((1-Sig)*PubNull))))
El resultado de la simulación es el siguiente:
En un mundo ideal, podríamos confiar en la literatura científica.
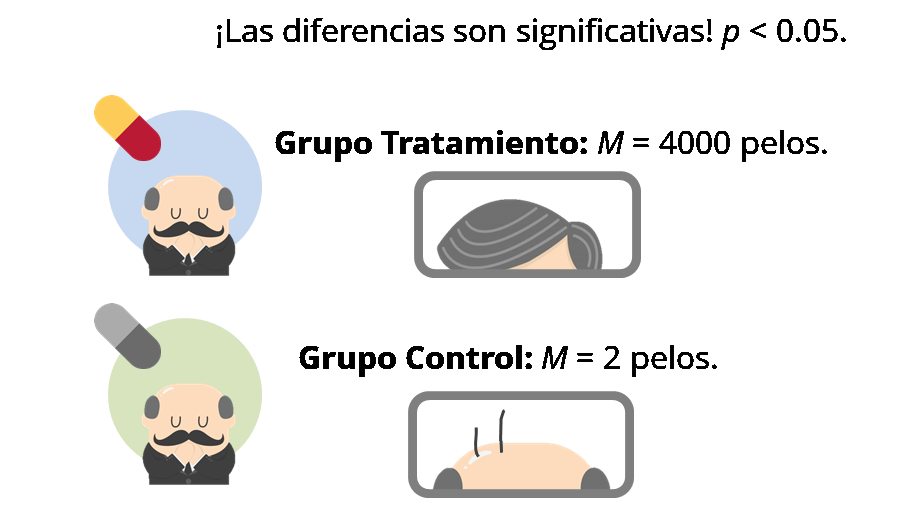
Así es la disección de la literatura científica en un mundo ideal. En la literatura publicada (derecha) proliferan los resultados significativos (un 94%), por efecto del sesgo de publicación. Sólo una mínima parte de los resultados publicados son nulos (no significativos). La probabilidad de encontrarse con un falso positivo es incluso algo menor a la probabilidad nominal del error Tipo I (4%). Sólo es una pena que tengamos en el cajón (izquierda) un montón de resultados aparentemente válidos: verdaderos positivos, y sobre todo verdaderos negativos. Pero no es algo muy grave, y por lo menos el proceso ha filtrado correctamente los falsos negativos, que es lo que más nos interesaba.
Bah… Contened la emoción. No os creáis nada de esto. Como suelen decir de los modelos matemáticos, “garbage in, garbage out”. Y es que el modelo es simplista, pero además hemos partido de unos supuestos que en la realidad sabemos que no se sostienen. Vamos a ver por qué.
Disección de la literatura en el mundo real
Es que vamos a ver. La simulación anterior se ha basado en números óptimos, increíbles. La realidad va a ser muy distinta. A continuación voy a repetir la simulación con otros valores que creo más cercanos a la realidad.
Para empezar, ¿es sensato asumir que más de la mitad de las veces que plantemos una hipótesis ésta sea correcta? A mí ya de entrada me parece una exageración, especialmente en psicología. Aun así, como no quiero que sea el foco de este argumento, voy a dar el supuesto por bueno: seguiremos asumiendo que el 60% de las hipótesis son, a priori, correctas.
Hemos dicho que la potencia mínima recomendable a la hora de diseñar un estudio es del 80%. Algunos autores proponen más, un 90%. Esto requiere muestras muy grandes de participantes, y en principio garantizaría que no hacemos estudios faltos de potencia que pasen por alto los efectos que estamos buscando. Sin embargo, hacer un estudio con buena potencia es muy caro. Casi nadie sigue la recomendación del 90%, ni del 80% siquiera. Yo sigo encontrándome con artículos en revistas de alto impacto con muestras de 10 participantes por celda. ¿Cuál sería un valor más realista de la potencia en psicología? Esto depende muchísimo del área de estudio (no es lo mismo el área de personalidad que la de social o la de neurociencia), pero algunas estimaciones nos dejan bastante mal. Por ejemplo, hay estudios que nos asignan una potencia promedio del 50%, que es como lanzar una moneda al aire, e incluso todavía peores, rondando el 30%.
Treinta. Por. Ciento.
En fin, que sí, que tenemos un problema serio de potencia. Actualizaremos la simulación con este dato.
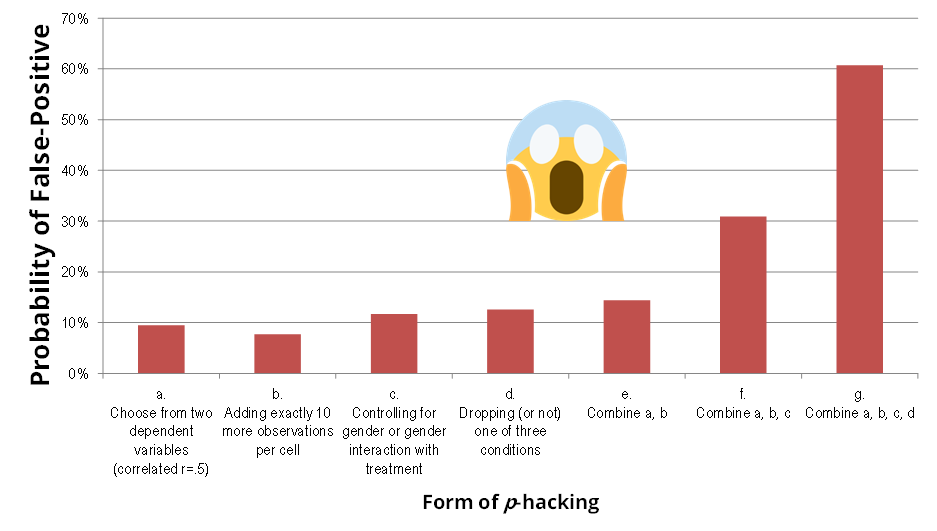
Más problemas que nos impone la dura realidad. Hemos dicho que la tasa de error Tipo I debería mantenerse por debajo del 5%, ¿verdad? Bien, pues tampoco es así en la vida real. ¿Habéis oído hablar del p-hacking? Se trata de un conjunto de técnicas, algunas de ellas muuuuy extendidas, que consisten en alterar el proceso de análisis de datos para obtener un p-valor significativo. Por ejemplo, es habitual que la gente pruebe distintos tipos de análisis hasta dar con el que mejores resultados produce, o excluya participantes sin un plan previo… Debo aclarar que, aunque el p-hacking se considere una práctica cuestionable, no siempre es premeditado, ni se hace con la intención de engañar. De hecho, puede ser muy sutil. En cualquier caso, y juicios aparte, ahora nos interesa tener una estimación de cómo de grave es el problema, es decir, cómo de fácil es conseguir mediante el p-hacking que un resultado no significativo se vuelva significativo. Pues bien, agarraos a la silla, porque un estudio se dedicó a calcularlo y…
Probar distintas técnicas de análisis hasta obtener un resultado significativo: la receta para el falso positivo.
Eso es, ¡puede llegar al 60%! Es una barbaridad. Por supuesto, esto no quiere decir que todos los estudios se hayan p-hackeado en tal grado. Siendo conservador, para la nueva simulación voy a asumir que, al tener en cuenta que hay algunos estudios p-hackeados, la probabilidad del falso positivo se incrementa desde un 5% hasta un 25%.
En cuanto al sesgo de publicación, lo vamos a dejar como estaba, que bastante grave era en la primera simulación.
Con estos nuevos datos, he rehecho las simulaciones y obtengo el siguiente patrón:
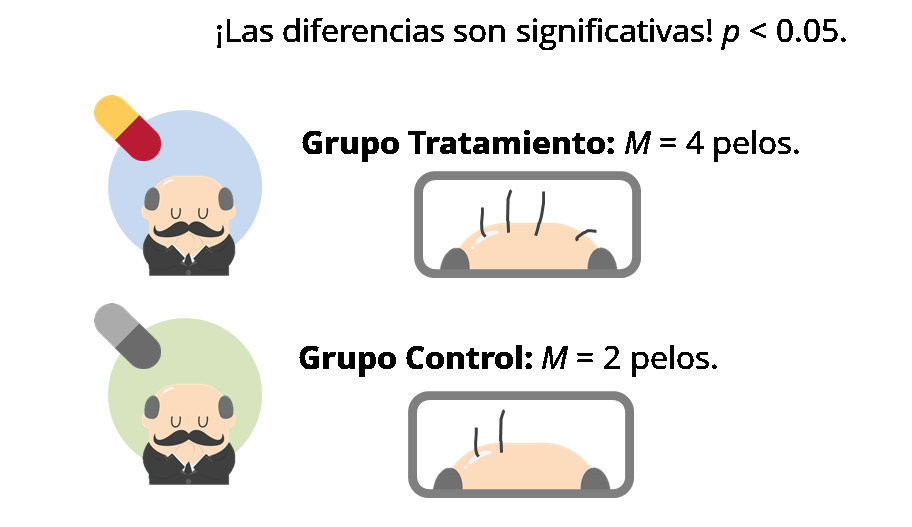
La triste realidad de la literatura publicada.
¡Hay más de un 30% de la literatura que son falsos positivos! Es decir, son resultados significativos que se usan para apoyar la existencia un efecto que no existe realmente. La pena es que el sesgo de publicación, esa preferencia por publicar los resultados significativos, impide que pasen a la literatura gran parte de los negativos verdaderos, que podrían compensar a los falsos positivos.
Conclusiones
No puedo afirmar con rigor que los resultados de la segunda simulación se acercan más a la realidad que la primera figura. No puedo, pero vamos, que lo creo. Por desgracia. La consecuencia es que hay una porción nada desdeñable de la literatura científica que presenta conclusiones falsas. ¿Tal vez estoy siendo demasiado pesimista? Hay quien iría más lejos todavía, o si no leed a Ioannidis.
¿Cómo separar el grano de la paja? Esto es lo más complicado. Muchas veces no lo podemos saber. En ocasiones, los falsos positivos se delatan por sus números imposibles: muestras pequeñas, abundancia de resultados significativos, análisis de muchas variables dependientes o indicadores a la vez… Pero admito que en el resto de los casos, es imposible diferenciar a simple vista los resultados poco fiables. Creo que las revistas podrían dar un paso al frente y ayudarnos un poco, simplemente relajando sus criterios para permitir la publicación de resultados nulos con más frecuencia. Esto tendría la consecuencia directa de que podríamos confrontar un falso positivo (obtenido por azar) con otros estudios que no encuentren el mismo efecto. A la vez, al no exigir un umbral de significación para la publicación, seguramente descendería la incidencia de algunas formas de p-hacking, al perder incentivos.
Después de unos cuantos años dando clase de Aprendizaje en la uni, ya estoy acostumbrado a una queja habitual en el primer curso del grado, cuando llegamos a esa parte del temario donde se habla de teorías del condicionamiento, y aparecen esos temidos modelos matemáticos:
“¿Por qué tengo que estudiar estas ecuaciones que aparecen en el manual? ¿No se suponía que esto es Psicología, y no matemáticas? Ni siquiera estamos en la asignatura de estadística”.
Como yo también fui estudiante, empatizo con este resquemor que aparece todos los años al estudiar teorías como la de Rescorla-Wagner o Pearce y Hall. Sin embargo, creo que esta sensación negativa no le hace justicia al contenido que se está transmitiendo, y que es cuestión de dedicar un poco más de tiempo a comprender los entresijos de estos modelos. En el post de hoy, voy a intentar complementar un poco ese apartado, y veréis cómo no es tan difícil. Para los más atrevidos/as, incluiré el código para simular el modelo de Rescorla-Wagner en R. ¿Empezamos?
Los modelos matemáticos
En general, hay dos grandes tipos de teorías en psicología: aquellas que se expresan sólo verbalmente (por ejemplo, las formulaciones tradicionales de las teorías de la comparación social, o las de la disonancia cognitiva), y aquellas otras que permiten cierto grado de formalización, es decir, que se pueden expresar en el lenguaje de las matemáticas.
Diseñar una teoría que sea formalizable tiene muchas ventajas. La más evidente es que nos va a permitir hacer predicciones cuantitativas, en forma de números. Por ejemplo, en vez de predecir que “este individuo aprenderá más que este otro”, podría ser más preciso apuntar que “este individuo aprenderá tres veces más que el otro”. (Dicho esto, mi yo más cínico está convencido de que hacer predicciones numéricas es prácticamente inútil en la mayoría de las aplicaciones en psicología, donde la flexibilidad del modelador es casi absoluta y la precisión de las medidas, de risa.)
En este post vamos a hablar del modelo de Rescorla-Wagner (Rescorla y Wagner, 1972), uno de estos “modelos formales” que describe, mediante un algoritmo sencillo, el proceso de aprendizaje por condicionamiento. Se trata probablemente del modelo de aprendizaje más famoso, que se ha aplicado a infinidad de ámbitos y que lidera toda una familia de modelos con características similares llamada “modelos asociativos” (Pearce & Bouton, 2001).
La historia del modelo de Rescorla-Wagner
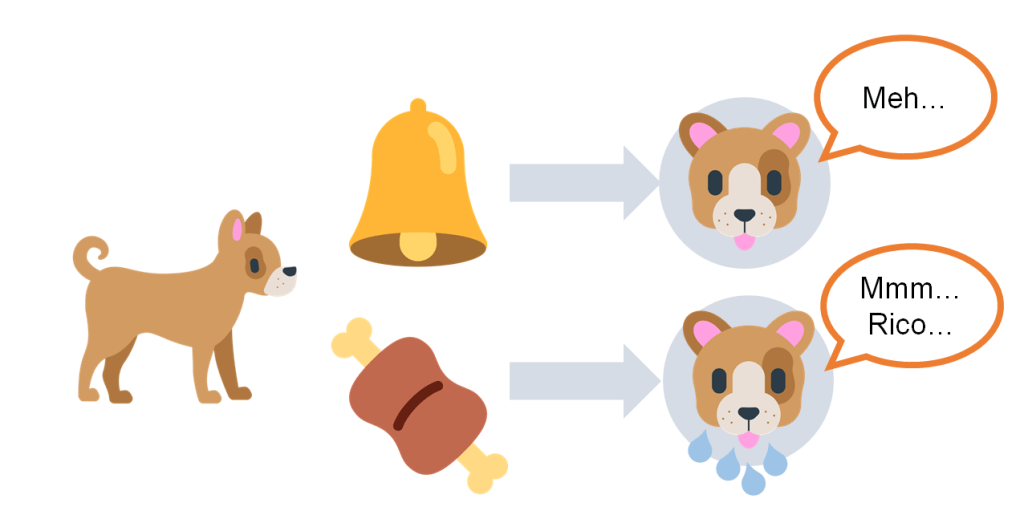
No voy a entrar en detalles históricos porque no quiero que sean el foco del post, pero creo que es interesante comprender qué hueco o necesidad “rellena” este famoso modelo. Bien, imaginad una situación de aprendizaje como la del perro de Pavlov, que ya conocéis pero que os resumo ahora:
El perro escucha un estímulo inicialmente neutro, el sonido de una campana (en el experimento original, era un diapasón). Este sonido no provoca ninguna respuesta en especial, dado que en principio carece de relevancia biológica. Por el contrario, la presentación de un plato de comida sí que produce una respuesta en el perro hambriento, en forma de salivación abundante. Diríamos que la comida es un estímulo incondicionado (EI) que produce una respuesta incondicional (RI).
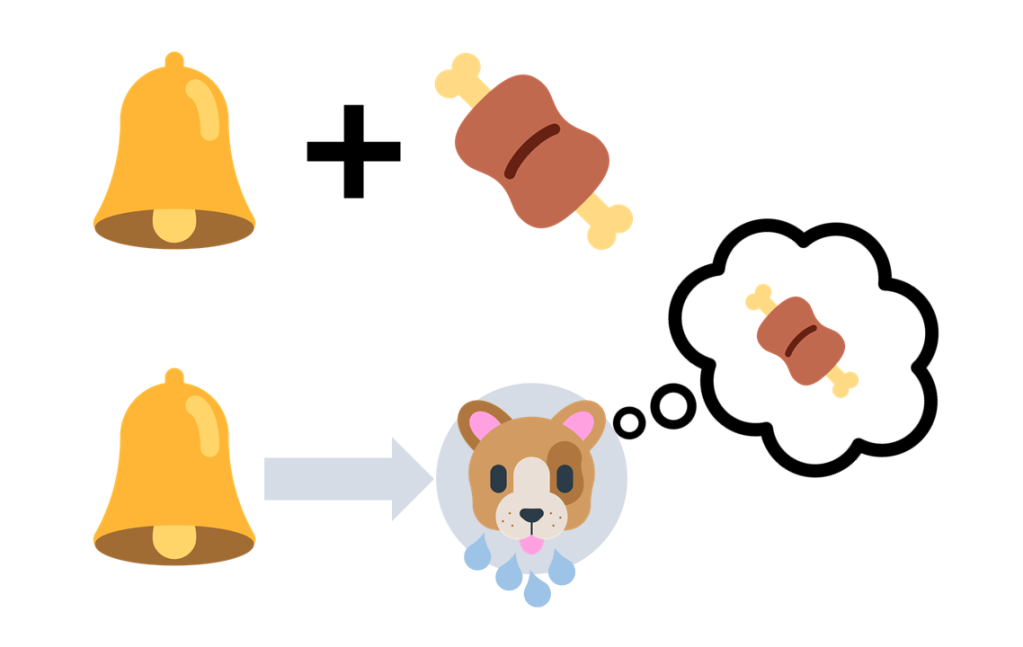
Por medio del procedimiento de condicionamiento clásico, vamos a emparejar repetidamente el sonido de la campana con la presentación de la comida. La idea es que el perro vaya aprendiendo que tras oír la campana va a poder alimentarse. Si de vez en cuando hacemos una prueba y reproducimos el sonido de la campana sin ir seguido de la comida, comprobaremos cómo ahora este sonido, inicialmente neutro, es capaz de provocar en cierto grado la respuesta de salivación. Es la prueba de que el animal ha aprendido la asociación entre los dos estímulos, y de que el sonido de la campana es ahora un estímulo condicionado (EC).
Este proceso se conoce como adquisición. Una vez ahí, podríamos extinguir el aprendizaje previo. Para ello, presentaríamos la campana (EC) sin ir seguida de la comida (EI), y paulatinamente veríamos cómo la respuesta de salivación iría desapareciendo. Este segundo procedimiento, la extinción, es muy relevante para muchos tipos de terapia.
Muy bien, pues ya hemos descrito dos fenómenos básicos en el aprendizaje: adquisición y extinción. Ahora, ¿cuál es el mecanismo que los hace funcionar? Inicialmente, podríamos pensar que basta con la mera contigüidad entre los estímulos. El perro aprende a “conectar” el sonido y la comida porque estos se presentan juntos en el tiempo, repetidamente. ¿Os sirve como explicación?
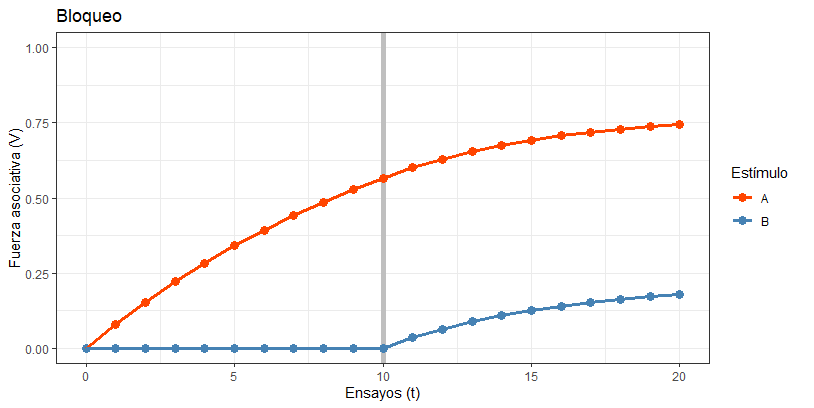
Pues va a ser que no. Aunque en los procedimientos descritos no lo podemos ver, hay otros que nos dan a entender claramente que la contigüidad es insuficiente. En concreto, vamos a hablar de Bloqueo:
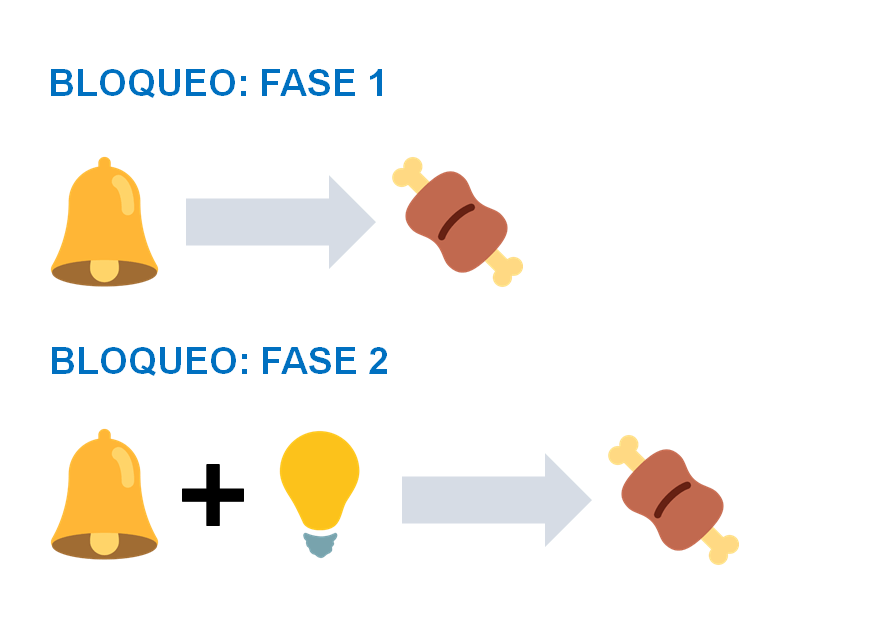
Un diseño de Bloqueo (Kamin, 1968) tiene dos fases, y dos estímulos condicionados diferentes (por ejemplo, el sonido de la campana, A y una luz, B). En la primera fase, el estímulo A (el sonido,) se empareja con la comida como en el caso de la asociación: A –> EI. Al final de la Fase 1, el perro será capaz de anticipar la comida al oír la campana.
En la Fase 2, continuamos con este entrenamiento, pero le añadimos el otro estímulo, B (la luz): A+B –> EI. Si ahora hacemos una prueba y le ponemos al perro la luz (B) en solitario, el resultado habitual es que el animal no va mostrar mucha respuesta. ¿Por qué (aparentemente) no está aprendiendo sobre la luz?
No puede ser un problema de contigüidad: la luz va seguida de la comida en repetidas ocasiones. Tiene que haber algo más. La respuesta está en la contingencia: aunque A y B son contiguos con la comida, A es más contingente con la comida que B. Y es que nunca hemos presentado la comida sin que esté presente A, pero en toda la primera fase hemos presentado la comida sin que esté B.
Entonces, ya tenemos un posible candidato a mecanismo de aprendizaje: los animales aprendemos las contingencias que se nos presentan, dejando la contigüidad en un segundo plano. ¿Cómo formalizar (es decir, expresar matemáticamente) esta intuición, para diseñar una teoría que lo refleje?
Eran principios de los 70 del siglo pasado, y la idea estaba ya presente en un campo recién inaugurado, el de la inteligencia artificial. Sí, aunque nunca se les da crédito en los manuales sobre aprendizaje (creo que yo no lo he visto en ninguno), Widrow y Hoff (1969) habían descrito la llamada “regla delta“, un algoritmo iterativo de optimización de funciones basado en la corrección progresiva de un error de predicción mediante el máximo gradiente (¡uf! qué lío), y que luego se volvería omnipresente para entrenar redes neuronales artificiales del estilo del Perceptrón. Los psicólogos Rescorla y Wagner hicieron suya la idea intuitiva tras esta regla, para diseñar su famoso modelo sensible a la contingencia. Y yo os lo cuento a continuación.
El concepto detrás del modelo de Rescorla-Wagner
La lógica que subyace al modelo es tremendamente simple: el combustible del aprendizaje es la “sorpresa”. Cuanto más aprendemos, menos nos sorprende lo que vemos, y seguiremos aprendiendo mientras algo nos sorprenda.
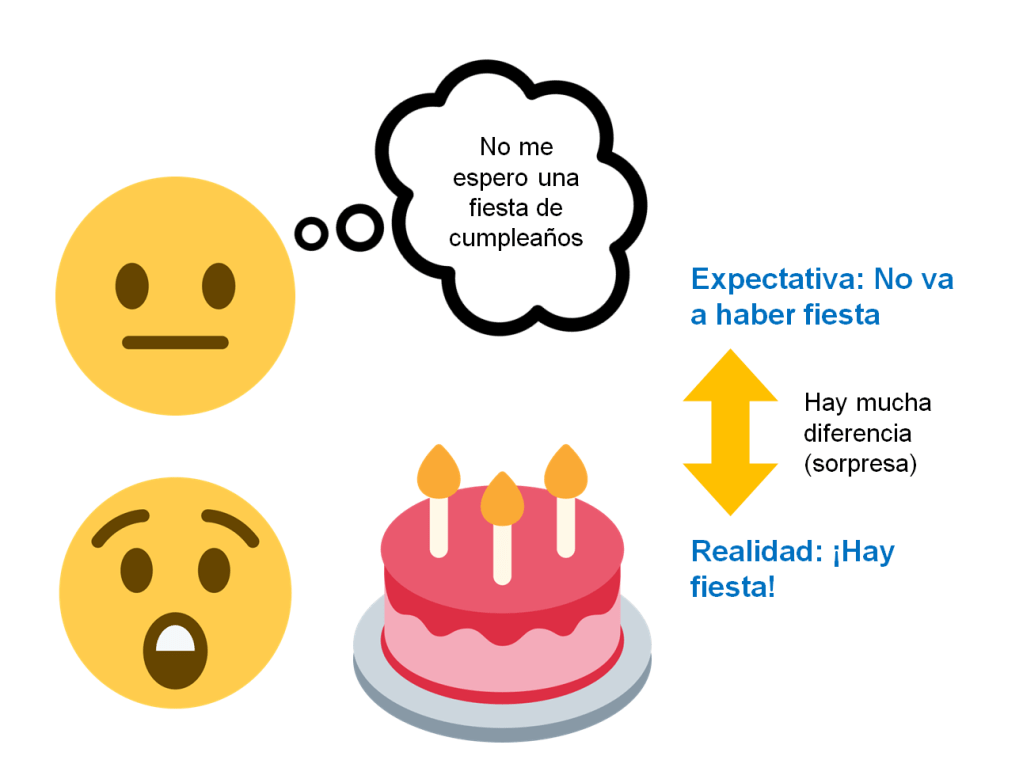
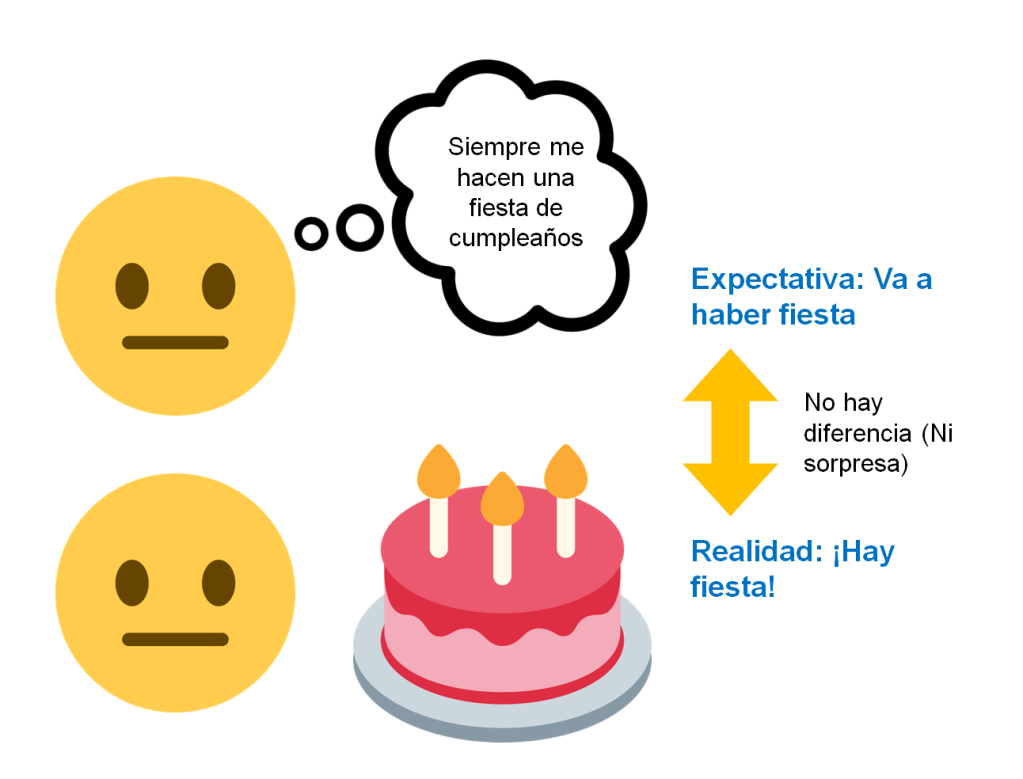
Lo vemos con un ejemplo. Vamos a definir “sorpresa” como la diferencia entre mi expectativa y la realidad. Imaginemos que es mi cumpleaños, y que no es habitual que lo celebre con los compañeros de trabajo. Por lo tanto, mi expectativa de encontrarme una fiesta es nula, o sea, tiene valor 0. Entonces llego al trabajo y descubro que, contra mi creencia previa, me tienen preparada una fiesta con pasteles y globos. Supongo que estaría muy sorprendido, ¿verdad? Lo sé porque hay una diferencia enorme entre la realidad (ha habido fiesta, por lo tanto fiesta = 1) y mi expectativa previa (mi expectativa era que no iba a haber ninguna fiesta, o sea, fiesta = 0).
¿Qué ocurriría si, a partir de entonces, se instaura una tradición en la empresa y todos los años celebramos una fiesta por mi cumpleaños? Pues que entonces, al acercarse el día, mi expectativa de fiesta sería máxima (expectativa: fiesta = 1). Por otro lado, como efectivamente estamos haciendo la fiesta (realidad: fiesta = 1), la diferencia entre mi expectativa y la realidad es mínima (1 – 1 = 0), y por lo tanto no estoy sorprendido.
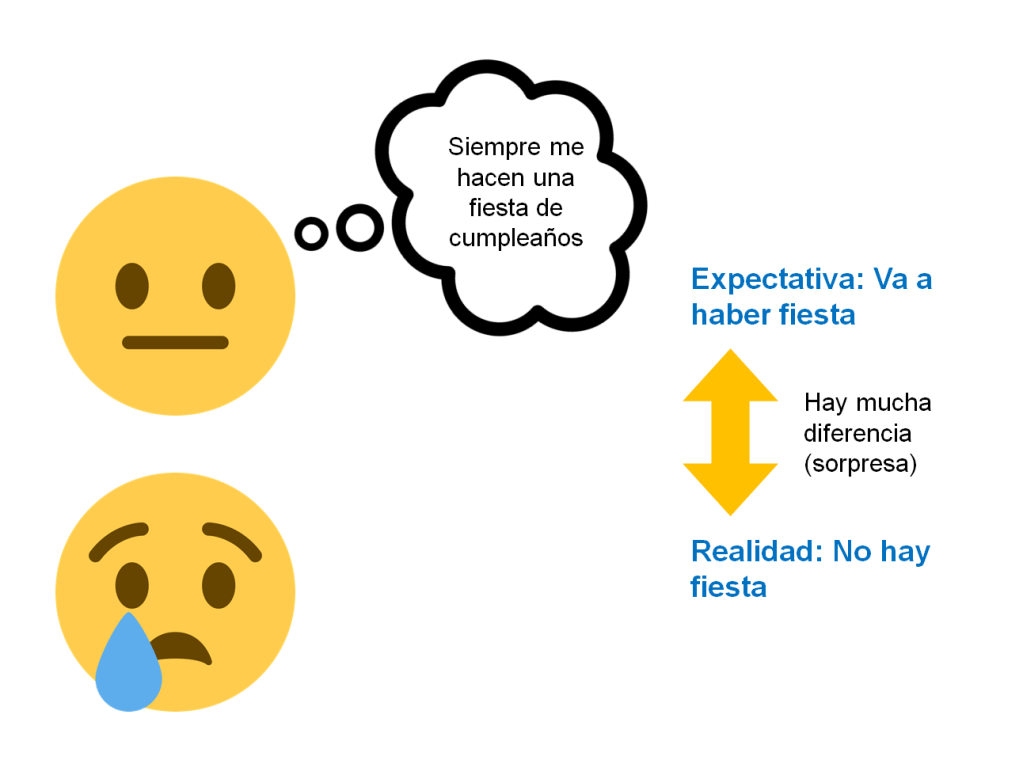
Sería posible también llevarse una sorpresa “negativa”: si, tras varios años en los que hacemos una fiesta por mi cumpleaños (expectativa: fiesta = 1), de pronto resulta que este año nadie ha organizado nada (realidad: fiesta = 0), mi expectativa de fiesta será muy diferente de la realidad, pero esta vez en negativo (0 – 1 = -1), es decir, una sorpresa desagradable, o una decepción.
De este ejemplo podemos ir sacando algunas conclusiones:
La sorpresa es la diferencia entre mi expectativa y la realidad que me encuentro.
Cuando un evento (que me hagan una fiesta) ocurre una y otra vez de forma regular o predecible, deja de ser tan sorprendente, porque he aprendido a predecirlo.
Y es que aprendo en la medida en que me sorprendo. Cuando una situación es muy sorprendente, puedo aprender sobre ella. Pero cuanto más capaz soy de predecir lo que va a pasar, menos me sorprende, y menos tengo por aprender.
Ahora podemos formalizar estas intuiciones en forma de un algoritmo de aprendizaje.
El algoritmo de Rescorla-Wagner.
La mítica ecuación que tanto miedo causa en primero de psicología no hace más que concretar estas ideas de forma matemática:
Ya puedo oler el terror en más de un estudiante de primer curso: “Madre mía, qué miedo da. Con todas esas letras griegas y sus subíndices”. Vamos a hacerlo más fácil definiendo las variables una a una.
Bien, el elemento principal en esta ecuación es V, la “fuerza asociativa”, que se traduciría como “la intensidad de mi expectativa” (*) de que va a ocurrir un evento, en este caso el EI. Si V es muy grande (cercana a 1), es que estoy casi seguro de que se va a presentar el EI.
Para entenderlo, imaginad que tenemos una representación mental de cada estímulo (el EC y el EI, o la campana y la comida). Cada representación se activa cuando se detecta el estímulo correspondiente. Cuando las dos representaciones están activas a la vez (y es justo lo que ocurre durante el entrenamiento de adquisición), se fortalece una “conexión” o asociación entre ambas, y V sería la medida de la fuerza de esa asociación.
La fuerza asociativa va a cambiar en cada ensayo, por eso le ponemos el subíndice “t” (de “tiempo”, o de “trial“, ensayo en inglés). Las ecuaciones de arriba describen la regla de actualización de V en cada ensayo. Así, en el ensayo 4, por ejemplo, la fuerza asociativa V4 será igual a la que teníamos en el ensayo anterior (V3) más una cantidad añadida, ΔV3 (**). La segunda ecuación nos explica cómo se calcula esta cantidad.
El corazón de la regla delta está en el paréntesis de la segunda ecuación: “λ – V”. Y es que esta diferencia encierra el concepto de “error de predicción” o de “sorpresa” del que hemos estado hablando. Ya sabemos que V codifica nuestra expectativa. Ahora bien, la letra griega lambda (λ) representa el estado de la realidad: ¿ha ocurrido el EI (la comida)? Entonces lambda vale 1. ¿No ha ocurrido? Entonces vale 0. Por lo tanto, ” λ – V ” es la diferencia entre la realidad y la expectativa, como en los ejemplos anteriores. Como veremos en las simulaciones, la regla de Rescorla-Wagner se alimenta de esta diferencia para ir corrigiendo el valor de V progresivamente. Cuanto mayor es la diferencia entre expectativa y realidad, más se incrementa la fuerza asociativa V en el próximo ensayo. Podéis pensar en la sorpresa como el “combustible” de Rescorla-Wagner: mientras haya combustible, siempre vas a seguir aprendiendo hasta agotarlo, es decir, hasta igualar V y lambda.
Ya solo nos quedan dos parámetros por mencionar, alfa y beta (α y β), que a veces, por simplificar, se unifican en un sólo parámetro (k). Son los parámetros que fijan la velocidad del aprendizaje, así que no hay mucho que decir al respecto.
Simulaciones: Adquisición y Extinción
¡Ya estamos preparados/as para ver el modelo en acción! He preparado esta pequeña función en R que podéis emplear para hacer pruebas por vuestra cuenta. Si no os apetece meteros con R, ignorad los trocitos de código, que el post se va a entender igualmente.
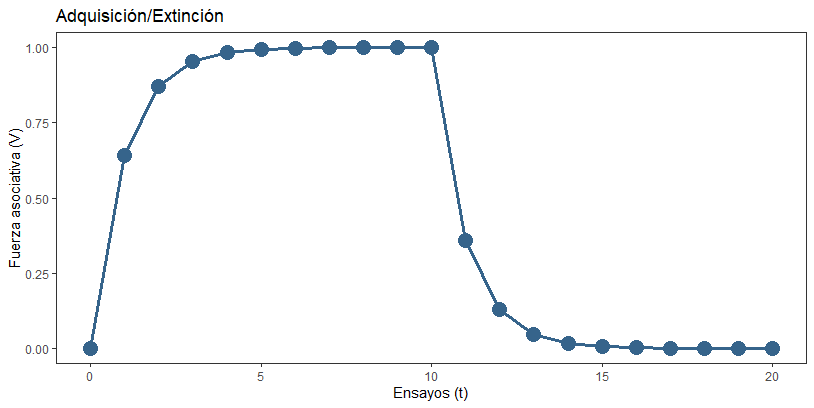
Vamos a comenzar simulando el proceso de adquisición y extinción que describimos antes: haremos diez ensayos en los que el EC irá seguido del EI (sonido –> comida), y otros diez ensayos de extinción en los que el EC no irá seguido del EI. Usaremos como parámetros de velocidad de aprendizaje dos valores altos (α = 0.8, β = 0.8). El resultado lo tenéis aquí:
CueA <- rep(1, 20) #Secuencia de valores del EC (1 si está presente, 0 si no)
CueB <- rep(0, 10)
Lambda <- c(rep(1, 10), rep(0, 10)) #10 ensayos de aquisición, 10 de extinción
V <- rep(0, 20+1)
alphaA <- 0.8 #Parámetros de velocidad de aprendizaje
alphaB <- 0.1
beta <- 0.8
Vamos a examinar la figura. Lo que vemos aquí es una curva de aprendizaje, una descripción de cómo va cambiando la fuerza asociativa a lo largo de los ensayos. En los primeros 10 ensayos, habíamos presentado el EC y el EI conjuntamente. En nuestro ejemplo, esto serían 10 años celebrando la fiesta de cumpleaños en el trabajo.
Al principio (t=0), mi expectativa de que me iban a hacer una fiesta de cumpleaños era nula (V0 = 0). Por eso, mi sorpresa en el primer año es mayúscula: 1 – 0 = 1. ¿Cuánto debería cambiar mi expectativa para el año que viene? Usemos la ecuación:
Ahora se entiende bien cómo funcionan los parámetros de velocidad de aprendizaje: aunque la sorpresa era máxima (1), no incrementamos la fuerza asociativa en toda esa magnitud, sino que depende de alfa y beta.
¿Y qué pasaría el segundo año? De nuevo, yo tenía una determinada expectativa de fiesta de cumpleaños, y me encuentro con que efectivamente hay fiesta (lambda = 1). ¿Cómo cambia mi expectativa para el tercer año? Vamos a las ecuaciones:
Es decir, tengo que incrementar mi expectativa en 0.23 puntos, por lo que mi expectativa para el tercer año será de V = 0.64 + 0.23 = 0.87. El cálculo es sencillo. Podría seguir así indefinidamente.
Vamos a fijarnos en una serie de datos interesantes. Primero, la fuerza asociativa va creciendo progresivamente para acercarse a su valor objetivo, lambda (en este caso, 1). Este crecimiento es negativamente acelerado. ¿Qué quiere decir esto? Como hemos comprobado, la sorpresa fue mayor en el primer ensayo que en el segundo. Y aunque no lo hemos calculado directamente, podéis creerme si os digo que la sorpresa fue mayor en el segundo que en el tercero, y en el tercero mayor que en el cuarto, etc. Conforme se reduce la sorpresa, el aprendizaje da pasos más pequeñitos, y por eso la forma de la curva es como estáis viendo. Esto se debe a que cada vez la sorpresa va siendo más pequeña: menos combustible = aprendizaje más lento.
En segundo lugar, fijaos en que la adquisición y la extinción son simétricas: son exactamente el mismo proceso, sólo que al pasar de lambda = 1 a lambda = 0 estamos trabajando con una sorpresa (y por tanto ΔV) negativa.
¿Podríamos reducir V hasta que fuera negativa, bajando por debajo de 0? Podríamos, pero no con este procedimiento. Harían falta técnicas de inhibición condicionada. Lo importante es entender que cuando V es negativa el condicionamiento es inhibitorio, y esencialmente sigue siendo lo mismo: el resultado de un aprendizaje basado en la reducción de la sorpresa.
Bien, ¿y si cambiamos un poco la simulación? Como decía antes, hay estímulos que permiten aprender más rápido que otros, y eso lo reflejamos en el modelo por medio de los parámetros alfa y beta. Imaginemos qué pasaría si el estímulo EC del que estoy aprendiendo es muy poco saliente, es decir, produce poco aprendizaje, y por lo tanto su alfa es muy pequeña, pongamos de 0.2:
alphaA <- 0.2
Ahí lo estáis viendo: al reducir el alfa, ahora el aprendizaje se vuelve más lento, y ni siquiera llegamos a alcanzar el valor objetivo de lambda = 1 en los diez ensayos de adquisición. Moraleja: podemos prodecir curvas con distintas formas y ritmos sólo cambiando estos parámetros de velocidad de aprendizaje, alfa y beta.
Simulaciones: Bloqueo
Y no podía faltar en esta fiesta el fenómeno de competición de claves más famoso, el bloqueo. Ya he explicado antes que fue uno de los resultados que motivó la necesidad de crear un modelo como Rescorla-Wagner, ya que implica que aprendemos sobre algo más que la mera contigüidad. Para explicar el bloqueo, Rescorla-Wagner asume que en la Fase 2 no aprendemos mucho sobre el segundo EC, B, porque ya hemos aprendido mucho con A, y por lo tanto no queda mucha sorpresa (de nuevo, recordad que la sorpresa es el combustible del modelo: si para la Fase 2 ya lo hemos gastado todo, no queda nada que aprender).
Tenemos que introducir un pequeño matiz en el modelo, porque ahora tenemos dos ECs, A y B, y cada uno tiene su propia fuerza asociativa. Hay que actualizar las dos fuerzas asociativas en cada ensayo, así que cambiamos un poco la ecuación:
¿Veis ese símbolo griego (∑) justo delante de V en el cálculo de la sorpresa? En matemáticas, ese símbolo se lee como “sumatorio“, y quiere decir que, si hay más de un estímulo predictor (o EC) en este ensayo, vamos a sumar todas las fuerzas asociativas de los estímulos presentes. O sea, que si en este ensayo tenemos una luz y un sonido, la sorpresa se calcula como la diferencia entre lo que ha ocurrido realmente (lambda) y lo que yo esperaba, que es la suma de las expectativas producidas por ambos estímulos.
Vamos con las simulaciones del Bloqueo. Necesito especificar los vectores de entrenamiento de los dos estímulos (recordemos, 0 significa que el estímulo no está presente, 1 que sí está presente):
CueA <- c(rep(1, 20)) #El EC A está presente en todos los ensayos.
CueB <- c(rep(0, 10), rep(1, 10)) #El EC B está presente sólo a partir de la Fase 2.
Lambda <- c(rep(1, 20)) #El EI está en todos los ensayos.
alphaA <- 0.4
alphaB <- 0.4
beta <- 0.2
¡TACHAAAN! Como podéis ver, en la Fase 1 estamos aprendiendo de A, a buen ritmo (llegamos a predecir el EI con una fuerza de más de 0.50). Entonces llega la Fase 2 e introducimos el nuevo estímulo, B, en combinación con A. Dado que A se ha gastado buena parte de la sorpresa (el “combustible”), no queda mucho para B, así que llegamos a aprender muy poquito sobre este estímulo al final de los veinte ensayos. Así explica Rescorla-Wagner el bloqueo: dado que los dos estímulos están repartiéndose la capacidad de predecir el EI, se aprende poco sobre B, porque aparece más tarde.
Conclusiones
Vamos terminando con este post, que ya está quedando demasiado largo, y tengo que recapitular hasta dónde hemos llegado. El modelo de Rescorla-Wagner es probablemente el más famoso y exitoso de los modelos formales de aprendizaje, y a sus más de 40 años ya podemos hacer balance de qué cosas hace bien y qué cosas no hace tan bien (Siegel & Allan, 1996).
En el lado positivo de la balanza, lo primero que reseñamos es que es un modelo súper sencillo, muy intuitivo y fácil de comprender (como espero que hayáis comprobado). También es muy fácil de implementar en cualquier ordenador. Ya veis que en R se puede hacer en un par de líneas de código. Por otro lado, yo siempre llamo a la precaución ante los modelos que “parecen” sencillos, porque al final estamos haciendo predicciones dinámicas y es fácil dejarse engañar por la aparente simplicidad, así que, ante la duda, lo mejor es simular la situación de aprendizaje para ver cómo se comporta el modelo.
El segundo punto fuerte ha sido su valor heurístico, a la hora de generar hipótesis que luego se han puesto a prueba experimentalmente. Y es que el modelo de Rescorla-Wagner (como todos los modelos) tiene supuestos: el aprendizaje es gradual, las fuerzas asociativas de los estímulos se suman linealmente, la extinción es el espejo de la adquisición… Y esos supuestos inspiran experimentos que los pueden poner a prueba, permitiéndonos avanzar en el conocimiento. Pocos modelos habrán generado tal cantidad de datos empíricos, predicciones, y debate teórico.
El tercer punto fuerte es que, efectivamente, el modelo explica muchos fenómenos de aprendizaje (Miller, Barnet, & Grahame, 1995; Siegel & Allan, 1996). Explica el bloqueo, por ejemplo, razonablemente bien. Hoy en día sigue siendo el “banco de pruebas” en el que se contrasta cualquier resultado experimental en el mundo del aprendizaje.
Vamos con los puntos débiles, con los problemas del modelo.
El principal problema es que, siendo cierto que explica muchos fenómenos satisfactoriamente, está bastante claro que no puede con muchos otros resultados que sí vemos en la literatura empírica. Voy a citar algunos ejemplos:
Primero, ya he dicho que para Rescorla-Wagner la extinción es esencialmente lo mismo que la adquisición, pero al revés, y por lo tanto es una especie de “desaprendizaje“. Hoy sabemos que esto tiene que ser incorrecto, puesto que, como bien saben los terapeutas que usan técnicas de exposición, el aprendizaje que ocurre durante la extinción no “sobrescribe” o elimina lo aprendido previamente. Otro fenómeno aparentemente inexplicable por el modelo (sin añadirle supuestos extra) es el bloqueo hacia atrás.
Otra limitación es que el modelo es lo que se conoce como “cadena de Markov“. Es decir, en cada ensayo, la fuerza asociativa V depende de la fuerza asociativa del ensayo inmediatamente precedente. Por lo tanto, no permite “reconstruir” cuál ha sido la historia de reforzamiento previa. Si dos estímulos idénticos han sido entrenados de formas diferentes, pero en el ensayo t tienen la misma fuerza asociativa, se van a comportar de manera idéntica a partir de ese momento. Hay resultados en la literatura que sugieren que los animales sí somos sensibles a la historia anterior de reforzamiento.
Más limitaciones: el modelo de Rescorla-Wagner no distingue entre aprendizaje y ejecución. Es decir, si dos estímulos A y B tienen fuerza asociativa VA = 0.3 y VB = 0.9, respectivamente, la predicción es que B va a mostrar una respuesta tres veces mayor que A. La idea es que se traduce directamente la fuerza asociativa a intensidad de la respuesta. Este supuesto se ha mostrado incorrecto en multitud de escenarios y situaciones. Hoy por hoy, se entiende que el modelo está incompleto sin una buena regla de respuesta, que haga esta traducción de manera más sofisticada.
Otra limitación, para mí de las más serias, es que el modelo, siendo sensible a las contingencias, es incapaz de capturar nada más que eso, meras correlaciones entre estímulos. Sin embargo, las personas (y también otros animales) podemos guiar nuestra conducta con algo más que simples correlaciones. Por ejemplo: todos sabemos que el canto del gallo correlaciona perfectamente con el amanecer (todos los días escuchamos al gallo cantar, y justo entonces se hace de día), pero a nadie se le ocurriría el maléfico plan de obligar a cantar al gallo para adelantar la salida del sol. En otras palabras: entendemos que no es lo mismo correlación y causalidad. Esto está totalmente fuera del alcance de Rescorla-Wagner, como discuto en este artículo (Matute et al., 2019).
Me dejo la limitación más jugosa (para mí) para el final. Es un tema que me cabrea un poco. Y es que este modelo, tal vez por su posición prominente en el área del aprendizaje, por lo bien asentado que está entre los investigadores, o por lo que sea, tiene la consistencia de un chicle. Se estira, se estira, y puede acomodarse a cualquier forma. Esto significa que, en realidad, Rescorla-Wagner puede explicarlo TODO (o casi), y por lo tanto pierde su capacidad discriminativa y se vuelve casi inútil. Veréis por qué.
Primero, tenemos los parámetros de velocidad de aprendizaje, alfa y beta. Generalmente estos valores no son conocidos, y pocas veces podemos predecir si un estímulo va a ser más saliente (tener un alfa mayor) que otro. Son parámetros libres. Si en mi experimento el animal ha aprendido muy rápido, diré que alfa es muy grande, y el modelo lo predice. Pero si ha aprendido muy despacio (el resultado contrario), diré que alfa es pequeña, y el modelo también lo predice. WIN-WIN. Recordemos que modificaciones posteriores del modelo (Van Hamme y Wasserman) permiten todavía más flexibilidad jugando con estos parámetros de velocidad de aprendizaje. Más aún: modelos similares a Rescorla-Wagner como el de Pearce y Hall proponen que los parámetros de aprendizaje no están fijos durante el entrenamiento, sino que van cambiando en función de lo que se aprende. Estiramos el chicle un poco más.
Además, podemos añadir supuestos extra al modelo. ¿Que no se puede explicar un resultado raro? Pues propón, por ejemplo, que se forman asociaciones “intra-compuesto” entre los elementos de un compuesto de estímulos. O que existe una tendencia hacia considerar los estímulos compuestos como agrupaciones estimulares o como elementos libres, y que eso depende de otros factores… Buf. El chicle permite alargarse, alargarse, hasta explicar cualquier conjunto de datos, sean reales o inventados.
Si os ponéis a revisar la literatura, veréis ejemplos de esto que estoy diciendo. Prácticamente no hay resultado contrario a las predicciones de Rescorla-Wagner que no se pueda acomodar a posteriori por medio de la inclusión de nuevos supuestos o de la tortura de los parámetros libres. Lo que me fastidia de esta habilidad que tienen mis colegas para estirar el chicle de Rescorla-Wagner es que, mientras tanto, están obviando otras propuestas teóricas diferentes que están ahí, que explican el resultado sin tanta pirueta, y que por cuestiones de tradición (cuando no directamente por una cuestión emocional) pasan a segundo o tercer plano. Una pena. Pero bueno, esto era un comentario personal.
Hasta aquí por hoy, que este ha sido un post muy largo. ¡Espero que os sirva para estudiar!
(*) Nota: Si me lee algún conductista, es posible que le entren ganas de colgarme por los pulgares por emplear tan profusamente un término mentalista como “expectativa”. Pues bien, sí, tiene razón, lo admito, pero me importa poco ahora mismo: yo escribo para que me entienda el común de los mortales (o la mayoría). Evidentemente se puede traducir el concepto en términos menos “esotéricos”, por ejemplo como una tendencia a ejecutar respuestas de anticipación del EI. También me podría ahorrar los globitos con verbalizaciones de “lo que piensa un perrito” y otras inexactitudes que estoy cometiendo. Pero en aras de facilitar que se entienda el mensaje principal, prefiero sacrificar un poquito de rigor. ¿Me lo permitís por hoy? 🙂
(**) Nota: la letra griega delta (Δ) se suele emplear en matemáticas y en otras ciencias para indicar un incremento en una variable. Así, podéis leer ΔV como “incremento en V”. Eso sí, tened la precaución de recordar que a veces este incremento es negativo (o sea, un decremento).
Referencias
Kamin, L. (1968). “Attention-like” processes in classical conditioning. In M. R. Jone (Ed.), Miami Symposium on the Prediction ofBehavior, 1967: Aversive Stimulation (pp. 9–31). Coral Gables (Florida): University of Miami Press.
Matute, H., Blanco, F., & Díaz-Lago, M. (2019). Learning mechanisms underlying accurate and biased contingency judgments. Journal of Experimental Psychology: Animal Learning and Cognition, 45(4), 373–389. https://doi.org/10.1037/xan0000222
Miller, R. R., Barnet, R. C., & Grahame, N. J. (1995). Assessment of the Rescorla-Wagner model. Psychological Bulletin, 117(3), 363–386. https://doi.org/10.1037/0033-2909.117.3.363
Rescorla, R. A., & Wagner, A. R. (1972). A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. In A. H. Black & W. F. Prokasy (Eds.), Classical Conditioning II: current research and theory (pp. 64–99). New York: Appleton-Century-Crofts.
Siegel, S., & Allan, L. G. (1996). The widespread influence of the Rescorla-Wagner model. Psychonomic Bulletin & Review, 3(3), 314–321. https://doi.org/10.3758/BF03210755
Widrow, B., & Hoff, M. E. (1960). Adaptive switching circuits. IRE Western Electric Show and Convention Record, Part 4, 96–104.
Continuamos con nuestro repaso a esas prácticas estadísticas que están tan extendidas, pero que a menudo nos llevan a cometer errores serios. Hoy me apetece abordar uno de los temas que más me saca de quicio. Ya habréis comprobado que tengo pasión por la “visualización” de los conceptos estadísticos y de los datos. Una (buena) imagen vale más que mil palabras, dicen, y yo lo suscribo sin reservas. Sin embargo, parece que hay una tradición bien instaurada en psicología, y es la de presentar los resultados en formato de tabla. Una tabla para las medias, los descriptivos, y también una para las correlaciones, los p-valores, los tamaños del efecto… Casi todos los TFGs, TFMs, tesis doctorales, y gran parte de los artículos que leo optan por representar los datos a través de tablas.
Qué belleza de tabla. Y “sólo” ocupa media página. Ugh.
A ver cómo lo digo para no despertar las iras de los fanboys de las tablas. Las tablas tienen sus ventajas, claro. Para empezar, permiten precisión, porque puedes poner el número exacto. Pero tienen otros factores en su contra. Primero, ocupan espacio. No es raro que me encuentre tablas de dos o tres páginas en un TFG (reza para que las celdas no salgan cortadas entre páginas, creando una confusión insufrible). Segundo, especialmente si hablamos de tablas grandes, son difíciles de leer y de recordar. Por eso, si queréis un consejo de propina, os diré que, por favor, no utilicéis tablas en una presentación. Ay, esas tablas que te ocupan la diapositiva entera, con los números raquíticos y apretados, y tan rellenas de valores que te quedas confuso sin saber dónde tienes que mirar, mientras dejas de escuchar a la persona que está exponiendo… En fin.
La alternativa para los que amamos las visualizaciones es clara: hacer una buena figura. Pero aquí entra otro conflicto, y es que determinados tipos de visualización, aunque puedan trasmitir la información de forma más eficiente y atractiva que una tabla, al final acaban cayendo en una de las limitaciones clave de estas: sólo pueden representar estadísticos resumen. Es decir, en las tablas y en cierto tipo de figuras me tengo que conformar con escoger UNA pieza de información que represente a toda la muestra: la media, la mediana, el coeficiente de correlación… Esto puede ser un problema. Por eso voy a dedicar el post a convenceros de los peligros de las tablas y de otras visualizaciones basadas en estadísticos resumen. Empecemos.
Los peligros de los estadísticos resumen
Como decía antes, es muy habitual que empleemos un estadístico resumen para describir nuestros datos. Por ejemplo, para indicar que el sueldo de un grupo de empleados es bajo, calcularé la media o la mediana, y tomaré decisiones basándome en ese valor. Todo bien, todo correcto, siempre que sea consciente de que estoy obviando información relevante. En el caso del sueldo, tener una media alta no nos debe hacer olvidar que suele haber bastante desigualdad y asimetría en la distribución (muchas personas cobrando poco, pocas personas cobrando mucho), lo que hace que la media deje de ser representativa. Vamos a demostrarlo con este simple ejercicio en R que podéis repetir en casa.
Pongámonos en situación. Imaginemos que cuatro estudiantes de psicología están interesados en comprobar si la cafeína afecta la capacidad de concentración. Para ello, diseñan un estudio en el que preguntarán a los participantes cuántos cafés toman por semana (variable x), y después les pedirán que realicen una prueba de concentración, grabando la puntuación resultante (variable y). El objetivo sería calcular una correlación entre las dos variables, como vimos en un post anterior. Ahora bien, los cuatro estudiantes deciden repartirse el trabajo: cada uno de ellos reclutará una muestra de 11 participantes, siguiendo un procedimiento idéntico.
Vámonos a R para introducir los datos obtenidos por los estudiantes: recordad, cuatro estudios idénticos, con un total de 44 participantes.
Bien, con el código anterior he creado una matriz de datos (en R se conoce como “dataframe“) que contiene cuatro sets de datos distintos (uno para cada estudiante). Cada set de datos únicamente contiene los valores de dos variables, x e y (cafés semanales y puntuación de concentración, respectivamente). Ahora los estudiantes deben poner en común su trabajo, así que cada uno elabora una tabla con los estadísticos resumen, como es costumbre: medias, desviaciones típicas, coeficiente de correlación… En R (con tidyverse) lo haríamos así:
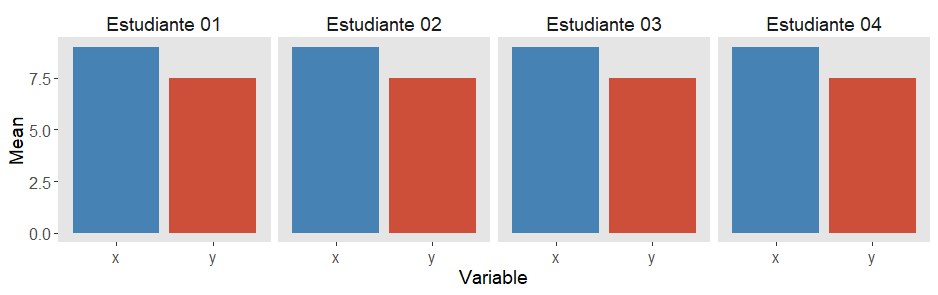
…Y el resultado obtenido sería una tabla como esta:
WTF!! ¿Notais algo raro? Qué casualidad. ¡Los cuatro sets de datos son idénticos! Bueno, o eso parece a simple vista. Tienen la misma media, desviación típica, tamaño muestral, coeficiente de correlación, y p-valor. Tiene que ser un error.
Bueno, tal vez estemos prestando atención al lugar equivocado. Hasta ahora solo hemos examinado los estadísticos resumen, y esos claramente son idénticos en los cuatro conjuntos de datos. ¿Qué tal si dejamos a un lado la tabla y representamos los datos con un gráfico? Podría ser que, aunque la media y otros estadísticos resumen fueran idénticos entre dos grupos de datos, la distribución de los datos fuese muy distinta, así que vamos a elaborar una figura que me permita vislumbrar esas distribuciones. Por eso empezaremos con unos histogramaspara ver la distribución de las dos variables:
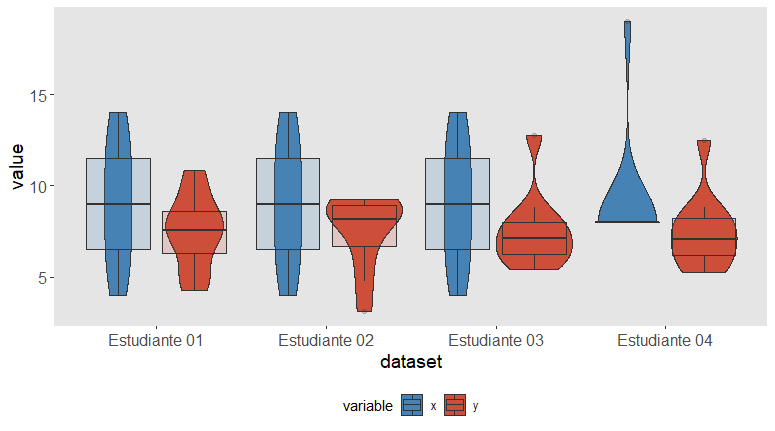
Ya tenemos la primera pista que nos permite descubrir que los cuatro sets de datos NO son idénticos, a pesar de tener exactamente los mismos estadísticos resumen: media, desviación típica, n, correlación y p-valor. De hecho, las distribuciones de las dos variables x e y son completamente diferentes de un set de datos a otro. Por ejemplo, mirad la fila de arriba, que contiene los histogramas para la variable y: en la muestra del Estudiante 4, parece que 10 participantes han afirmado tomar 8 cafés por semana, y un solo participante dice tomarse un número mucho mayor, 19. Es una distribución un tanto extrema, con solo dos valores, y diferente a la obtenida por los otros estudiantes.
He aquí un problema grave de los estadísticos resumen: nos dicen poco acerca de nuestros datos en concreto, ya que hay una variedad inmensa de conjuntos de datos que tienen idéntica media, desviación típica, n… y que por lo tanto son indistinguibles si miramos únicamente estas medidas resumen.
¿Y qué hay de los coeficientes de correlación? ¿Cómo es posible que estos cuatro sets de datos tengan la misma correlación entre las dos variables? Vamos a examinar este asunto a través de un scatter plot o gráfico de dispersión, que nos indicará cómo se relacionan las dos variables entre sí:
El resultado de este código es el siguiente gráfico:
Oh, vaya, parece que no damos una: cada conjunto de datos, a pesar de tener exactamente el mismo coeficiente de correlación (y su correspondiente p-valor), muestra una relación entre las variables completamente distinta:
En el caso del Estudiante 1, la figura no tiene mal aspecto, los datos se distribuyen con cierta aleatoriedad, pero mostrando una tendencia ascendente clara, y de ahí el coeficiente de correlación positivo y significativo. Cuanta más cafeína (x), mejor rendimiento (y).
El Estudiante 2 ha obtenido unos datos que claramente se distribuyen de forma no lineal, sino cuadrática: ¿veis cómo están dispuestos formando una curva? Esto nos sugiere que las dosis intermedias de cafeína mejoran la concentración, pero que una dosis muy alta reduce esta capacidad (una especie de “u invertida”).
El caso del Estudiante 3 nos recuerda lo comentado en el post sobre los outliers. La línea de ajuste está afectada por una única observación que tiene una puntuación de concentración particularmente elevada. Si no estuviera ese caso concreto, la línea estaría menos inclinada y por lo tanto el coeficiente sería más pequeño, quizá no significativo.
El Estudiante 4 ha tenido muy mala suerte. Todos los participantes han coincidido en la misma cantidad de cafés semanales (ocho), salvo por uno, que se toma la friolera de 19. En este caso, la correlación observada es en realidad un artefacto producido por esta observación un tanto anómala. Si la excluyésemos, ni siquiera podríamos calcular un coeficiente de correlación, puesto que la variable x en este set de datos sería una constante.
Bien, creo que ahora se ilustra más claramente el problema. Cuatro sets de datos que cuentan cuatro historias totalmente diferentes. En algunas de las historias, la relación encontrada parece un artefacto, en otras realmente existe, pero es no lineal… Pero los cuatro conjuntos de datos comparten una tabla con medidas resumen idénticas. Si no nos hubiéramos molestado en representar los gráficos anteriores, tendríamos la conclusión (incorrecta) de que los resultados de los cuatro estudiantes son equivalentes.
Este set de cuatro conjuntos de datos es ya famoso, se conoce como “cuarteto de Anscombe“, y se emplea para ilustrar justo lo que acabo de decir, que hay que desconfiar de los estadísticos resumen. Así que, moraleja: No te conformes con hacer una tabla con los estadísticos resumen. Haz un buen gráfico. Y como lector, exígelo. No cuesta nada.
Por cierto, si el cuarteto de Anscombe os parece intrigante, que sepáis que la cosa se puede complicar mucho, mucho más. Os presento a un descendiente moderno del cuarteto de Anscombre, conocido como “Datasaurus” (Smith, 2017). Como véis en el gif, podemos tener datos con casi cualquier distribución y tipo de relación, y no cambiar apenas los estadísticos resumen:
Gráficos de barras: la opción simple pero engañosa
Aunque creo que el punto ya se ha entendido bien, voy a continuar un poco más para demostrar que, en realidad, el problema no es inherente a las tablas, sino al uso de los estadísticos resumen, que solo dan información parcial. Efectivamente, hay tipos de gráficos muy extendidos que se basan también en medidas resumen, y por lo tanto tienen el mismo problema que hemos comentado. Un ejemplo habitual son los gráficos de barras para expresar promedios u otros estadísticos de centralidad. Vamos a comprobarlo:
¿Separados al nacer?
Como ya habíamos comprobado previamente, los cuatro sets de datos comparten idénticas medias para las variables x e y. Por eso este tipo de representación gráfica no nos ayuda precisamente a descubrir la historia real detrás de cada conjunto de datos, haciéndonos creer que son equivalentes. Los gráficos de barras no nos muestran nada de las distribuciones de los datos. (Son, sin embargo, buenos y sencillos de entender para transmitir información de proporciones).
Dado que los gráficos de barras son prácticamente omnipresentes en las publicaciones científicas, un grupo de jóvenes investigadores lanzó hace unos años una campaña de crowdfunding llamada “#barbarplots“, dirigida a desterrar este tipo de gráficos para la mayoría de las aplicaciones habituales. Aquí podéis ver su video promocional.
Otras alternativas gráficas
Os estaréis preguntando: si no debo utilizar tablas ni gráficos de barras, ¿qué otras formas tengo de representar mis resultados? Voy a mencionar unas cuantas alternativas, pero mejor ved alguno de los papers donde se discuten los motivos, como Weissgerber et al. (2015).
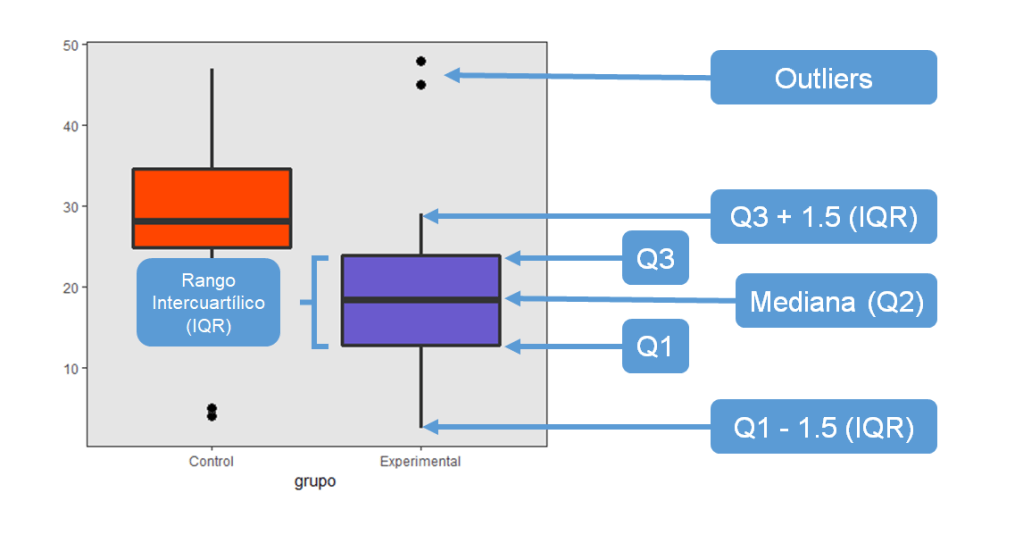
Boxplots y Violin plots
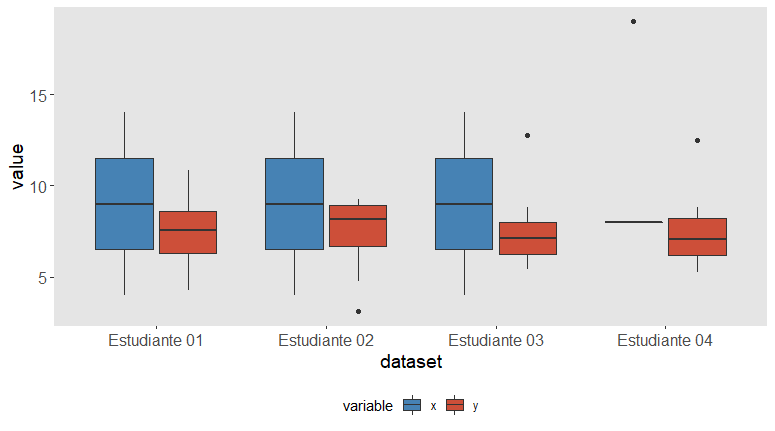
Los gráficos de caja (boxplots) que comentamos en un post anterior son una buena forma de visualizar las distribuciones. Apliquémoslo a los datos del cuarteto de Anscombe:
Aunque este gráfico sería en todo caso un complemento a los gráficos de dispersión de más arriba, ya nos sirve para detectar diferencias claras entre las distribuciones: el outlier en la variable y del Estudiante 3, la distribución totalmente descuajaringada en la variable x del Estudiante 4…
El problema habitual con los gráficos de caja es que requieren un poco de entrenamiento para poder interpretarlos (así que sí, es normal que no los entiendas bien a la primera). Afortunadamente hay otras alternativas. Con sólo cambiar una línea de código, podemos pasar de los boxplots a los “violin plots“, o incluso combinar ambos, como en la siguiente figura:
La gracia del componente “violín” de este gráfico es que transmite la forma de la distribución de una manera bastante intuitiva que no requiere un ojo entrenado. Esa forma curvada con aspecto de “vasija” es en realidad una aproximación de la densidad de la distribución: allí donde se hace más estrecha hay menos datos. Así podemos detectar asimetrías, outliers…
Dotplots
¿Le damos otra vuelta de tuerca a los violin plots? En vez de dibujar las densidades aproximadas, cuando el número de datos no es grande podemos representar cada punto de datos individual. Es justo lo que hacen los siguientes dotplots.
Ahora es mucho más fácil darse cuenta de que, por ejemplo, la variable x en el set del Estudiante 4 no tiene más que dos valores.
Otra utilidad interesante de este tipo de gráficos es que nos permite descubrir posibles problemas como por ejemplo la comparación de grupos con tamaños muy diferentes, presencia de outliers, varianzas no homogéneas, etc. Os pongo como muestra esta figura de Weissgerber et al (2015), en la que el mismo gráfico de barras puede estar ocultando sets de datos muy diferentes:
En general estamos tan acostumbrados a los estadísticos resumen que, incluso si empleamos este tipo de visualizaciones más modernas vamos a tener que combinarlas con algún tipo de representación de la media, de la mediana… Además suelen ser estos estadísticos resumen los que empleamos en la inferencia, así que necesitamos verlos de alguna manera en el gráfico. Suerte que hoy en día no tenemos que limitarnos a un tipo de visualización, sino que podemos mezclarlas. Por ejemplo, podemos usar los márgenes de un gráfico de dispersión para dibujar los histogramas:
A mí me gusta particularmente la idea de dibujar los datos reales por encima del gráfico de barras, añadiendo un pequeño desplazamiento aleatorio en el eje horizontal (jitter):
Esta figura combina lo mejor de los dos mundos: tenemos las medias de las dos variables, pero también una idea aproximada de la distribución, y de la n de cada variable…
Conclusiones
Terminamos ya este post que ha tratado sobre uno de los problemas clásicos a la hora de transmitir la información estadística: confiar demasiado en los estadísticos resumen (media, mediana…). Hemos comprobado cómo los estadísticos resumen pueden ser engañosos, lo cual convierte a las tablas en una opción un tanto ineficiente para comunicar resultados. Pero este problema se extiende a otro tipo de visualizaciones que también confían en los mismos estadísticos, como los gráficos de barras.
Así que si quieres un consejo para tu próximo trabajo de investigación, es el siguiente: merece la pena buscar una buena manera de visualizar los datos y transmitir toda la información relevante. No hurtes al lector la información de las distribuciones, ni te fíes de las “tradiciones”. ¡No es obligatorio hacer una tabla, o un gráfico de tarta! Arriesga, que ahora el software te lo pone fácil.
Por cierto, si alguien lo pregunta: todas las figuras las he elaborado en R con ayuda del paquete ggplot2 (bueno, en general me he hecho fan de las mecánicas tidyverse). Pero hay aplicaciones gratuitas que hacen figuras más que decentes, y si no las conocéis preguntadme en los comentarios. ¡Hasta la próxima entrega!
Después de dos posts suavecitos, sin meteros mucha caña, creo que ya podemos empezar a tratar temas más específicos (y más prácticos). Si habéis hecho alguna investigación empírica con recogida de datos, seguro que la historia de hoy os va a sonar muy, muy familiar. Acabas tu trabajo de campo y te dispones a hacer los análisis. Los datos parecen ir en la línea que habías previsto… hasta que te fijas bien y te das cuenta de que hay dos puñeteros participantes que hacen justo lo contrario de lo que tendrían que hacer, y que te estropean el resultado del estudio entero. ¡Malditos!
Esas dos o tres observaciones que se salen de la escala y que nos atormentan se conocen popularmente como “outliers” (MacClelland, 2000). Se trata de casos con valores muy extremos, diferentes al resto de su grupo, que pueden dar al traste con tu estimación. Estas observaciones pueden ser fruto de un error al introducir los datos (por ejemplo, si me baila el dedo y puntúo un examen de 0 a 10 con un “90”, en vez de un 9), pero también pueden ser valores perfectamente válidos, sólo que muy infrecuentes. Nuestro objetivo es detectar los outliers, evaluar el riesgo de que malogren el estudio, y tomar alguna decisión al respecto. ¡Ya veremos cuál!
[AVISO para lectores ya curtidos con la estadística: en este post sólo vamos a hablar de outliers univariados, que son el caso más sencillo. Hay otras técnicas de detección de outliers multivariados, pero no las vamos a tratar hoy]
Los outliers te destrozan la estimación (pero pueden ser interesantes)
Vamos a comenzar intentando comprender por qué los outliers son tan peligrosos a través de un ejemplo sencillo. Supongamos que me interesa averiguar cuál es el tamaño promedio de los perros de una determinada población. Esta información podría ser interesante a la hora de adoptar determinadas políticas, como por ejemplo el tamaño que tienen que tener los parques y lugares comunes. Entonces, contrato a un ayudante para que se dedique a visitar algunas viviendas de la ciudad, cargando con una báscula para pesar a los perros que se vaya encontrando.
Nuestro ayudante se percata en seguida de que, al menos en las afueras de este pueblo, donde las casas son grandes y están aisladas, a la gente le gustan los perros enormes que sirvan como guardián: ya lleva encuestados dos San Bernardos, unos cuantos mastines, varios pastores alemanes… En una primera muestra de unos 10 animales, el peso medio ha sido de nada menos que ¡82.54 kg! Podéis ver el gráfico resultante en el panel superior de la siguiente figura.
Sin embargo, al tercer día, nuestro aventurero investigador se adentra en las callejuelas del centro y da con una vivienda de pequeñas dimensiones, en la que una señora mayor cuidaba de un (bastante nervioso) perrito chihuahua, de solamente 1.5kg de peso. Este perrillo tiene un peso sensiblemente inferior al de todos los animales previamente encuestados, y por lo tanto lo podemos considerar un caso extremo, un outlier. Al calcular el nuevo promedio después de introducir este dato, observamos que la media ha bajado notablemente (hasta 73.53kg).
La figura anterior es una muestra del efecto que tienen los outliers sobre la estimación del promedio: con sólo añadir esa observación, la media se ha transformado radicalmente. Por otro lado, también podemos comprobar que otros estadísticos son más robustos a los outliers: en el gráfico tenéis representada la mediana, que apenas se ve afectada.
Este ejemplo ilustra también una de esas ocasiones en las que los outliers nos dan información valiosa. En este caso, nos está indicando que medir el peso de los perros, así en general, puede ser poco informativo, y que deberíamos tener en cuenta parámetros como la raza, o el lugar de residencia. No es lo mismo un dogo alemán que un caniche. No tienen el mismo tamaño los perros que viven en fincas grandes que los que viven en un apartamento en la ciudad. Aunque solemos hablar de los outliers en términos negativos porque pueden dar al traste con tus predicciones (no en vano, yo lo aprendí casi todo con un paper que se titulaba “nasty data“), lo cierto es que también pueden ser una fuente de conocimiento y descubrimiento. Hay programas de investigación enteros que se basan en la observación de individuos excepcionales.
Los outliers distorsionan tus resultados
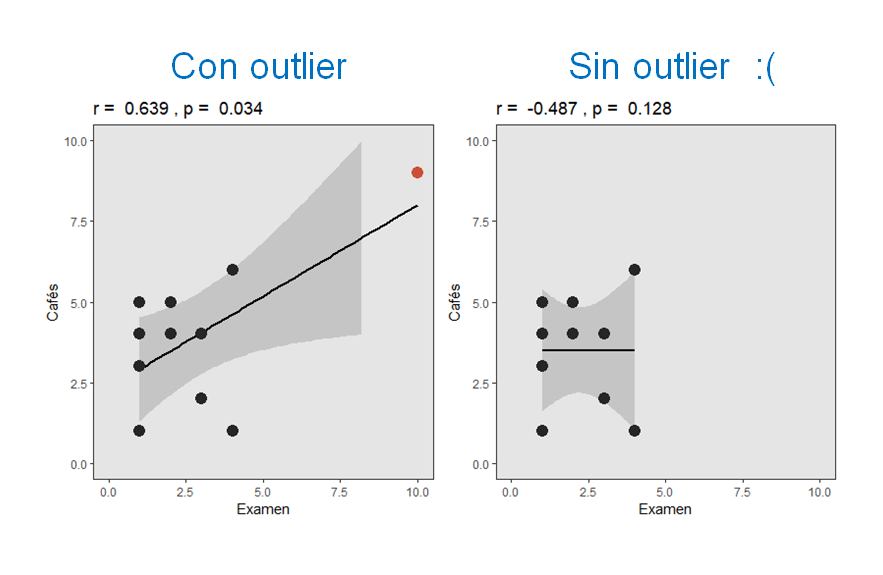
Aprovechando que el otro día estuvimos hablando de las correlaciones, vamos a poner otro ejemplo del peligro de los outliers, quizá más práctico para quien esté trabajando con datos reales. Imaginad que estamos haciendo un estudio sobre el efecto de la cafeína en el rendimiento académico. Así que hemos reunido una muestra de estudiantes a los que hemos preguntado cuántos cafés toman durante la semana, y hemos calculado la correlación de ese número de cafés con la nota de un examen de matemáticas. …Pero resulta que el examen era bastante difícil (casi todo el mundo ha suspendido). Sin embargo, hay una persona que ha sacado un 10. Al ser una nota muy distinta a la del resto de la clase, podemos considerarla una observación extrema, o un outlier.
A la izquierda, podemos ver que justo esa persona que ha sacado un 10 es también particularmente aficionada a los cafés, puntuando por encima del resto (he marcado el punto en rojo). La correlación entre las dos variables es positiva, p < 0.05. ¡BUM! Ya tenemos resultado. Bueno, pero, ¿qué habría pasado si justo esa persona que ha sacado el 10 no fuera tan, tan, extremadamente aficionada a tomar cafés? El resultado lo tenéis a la derecha: la correlación desaparece. Porque esa correlación era, en realidad, un artefacto producido por un único caso extremo.
Moraleja: siempre que leas un artículo donde aparezcan coeficientes de correlación, ¡exige una figura con los datos! A veces hay una o dos observaciones que explican el resultado.
Casos demasiado influyentes
Este último ejemplo nos lleva al siguiente concepto que debemos conocer: el de influencia. Los parámetros de nuestro modelo estadístico (en este caso, sería el coeficiente de correlación) se estiman a partir de los datos. Por lo tanto, cada dato está “contribuyendo” con un poco de información al modelo. Pero puede ocurrir que unos casos tengan más peso que otros en la estimación. A ese peso lo llamamos “influencia“, y suele ocurrir que los outliers sean también casos más influyentes que el resto. La manera de darnos cuenta es eliminar ese dato de la muestra y observar cómo cambia el modelo. En la siguiente figura, tenemos los mismos datos que en los ejemplos anteriores, pero sin el outlier, y vemos que la recta de ajuste se queda plana (no detectamos ninguna correlación significativa).
De esto se deduce que, en principio, deberíamos protegernos frente a aquellos datos que tienen demasiada influencia en el modelo, porque nos van a distorsionar el resultado.
¿Cómo cuantificar la influencia de tus datos? Una posibilidad es calcular unos estadísticos llamados “las distancias de Cook” (la mayoría de los paquetes de software lo pueden hacer con un par de clics). Básicamente, estas distancias se obtienen eliminando cada dato uno por uno, y registrando cuánto cambian los parámetros del modelo (en este caso, la inclinación de la recta). Los casos con valores de influencia más altos (medidos con este procedimiento) generalmente están introduciendo una distorsión en los resultados, así que podríamos plantearnos hacer algo al respecto.
¿Cómo detectar los outliers?
La pregunta del millón: ¿cómo de “anómalo” o “extremo” tiene que ser un dato para que yo decida que tengo que tomar medidas? Existen varias técnicas, y por regla general es mejor combinar un par de ellas para asegurarnos de que convergen en la misma conclusión. Por un lado tenemos los métodos gráficos, y por el otro los criterios estadísticos (Aguinis, 2013).
En cuanto a los métodos gráficos, tenemos la opción socorrida del histograma. Un histograma ilustra la distribución de los datos mediante barras verticales que representan la cantidad de casos que tienen un valor determinado. Las barras más altas corresponden a los valores más frecuentes. Un outlier se revelaría como un dato alejado del resto de la muestra. En la siguiente figura, la mayoría de los valores oscilan entre 0 y 6, pero hay un valor mucho más alto:
De todas formas, se trata de un procedimiento algo rudimentario y que depende demasiado del buen ojo que tenga el observador. Por suerte tenemos una alternativa mucho más informativa, los llamados “gráficos de caja” (boxplots):
En este tipo de gráficos se representan las distribuciones de los datos de forma un poco diferente, porque se divide la muestra en cuatro porciones de tamaño similar: los cuartiles (primero, segundo, tercero y cuarto, o Q1, Q2, Q3 y Q4). La línea gruesa que queda aproximadamente en la mitad de la caja es la mediana, es decir, el punto de corte que divide a la muestra en dos mitades. A cada lado de la mediana, por arriba y por abajo, se extiende el “rango intercuartílico” (en inglés IQR), es decir, los cuartiles 1 a 3. Los outliers quedan fuera, y se representan en forma de puntos. Son valores extremos, muy improbables dada la distribución de la variable: están más de 1.5 veces el rango intercuartílico por encima del tercer cuartil (Q3), o por debajo del primer cuartil (Q1). Dependiendo del software que utilices, puede cambiar el punto de corte (entre 1.5 y 3 suele variar).
En cuanto a los métodos estadísticos para detectar outliers, tal vez el más conocido sea el método de Tukey. La idea es la siguiente: un outlier se define como un valor que está excesivamente alejado de la mediana, que es el punto medio de la distribución. Para descubrirlos, el primer paso que debemos dar es convertir nuestros datos a puntuaciones Z. Para ello, basta con restar a cada puntuación la media de todo el grupo, y dividir el resultado por la desviación típica. Al estandarizar los datos de esta manera, conseguimos que la media muestral de los datos así transformados sea igual a cero, y la desviación típica igual a 1. Ahora, los datos se expresan directamente como la distancia con respecto al centro de la distribución. Por ejemplo, una puntuación de 2.53 significa que esa observación es 2.53 desviaciones típicas mayor que la media, y una puntuación de -0.32 significa que ese caso está 0.32 desviaciones típicas por debajo de la media. Ya solo falta elegir un umbral, un punto de corte a partir del cual decidimos que la puntuación es un outlier porque está demasiado alejada del centro de la distribución. El punto de corte habitual suele ponerse en 1.5, 2, 2.5, ó 3. Si escogemos, por ejemplo, el 3 como punto de corte, consideraríamos un outlier a toda puntuación transformada por encima de 3 o por debajo de -3.
En este sentido, a veces uno está leyendo un artículo y descubre que han “expulsado a todos los outliers”, sin especificar cómo. Aquí sería importante que los autores nos dijeran cuál ha sido el punto de corte escogido para definir el caso como outlier. No es lo mismo un criterio estricto como “3 desviaciones típicas” que uno mucho más laxo, como “1.5 desviaciones típicas”.
¿Qué hacer con los outliers?
Llega el punto más delicado de todos, y el que produce un sinfín de malas prácticas y confusión. Imaginemos que he detectado unos cuantos casos extremos en mis datos. ¿Qué hago con ellos? ¿Los elimino o los dejo estar? Sobre este tema creo que no hay una opinión clara que se pueda generalizar a todas las situaciones. Realmente, por lo que voy leyendo, depende de a qué autores les preguntes, la recomendación es una u otra. Intentaré transmitir mi opinión sintetizando los argumentos que más me han convencido, pero estoy seguro de que otras personas podrán aportar otros puntos de vista. Allá voy.
PASO 1. ¿Es un error?
Lo primero que tenemos que decidir es si esa observación extrema que tenemos delante podría corresponder a un error de codificación. No sería tan raro, especialmente si utilizáis métodos de entrada de datos no automatizados. Suponed que estamos recopilando el peso de los perros de una ciudad, como en el ejemplo de arriba. Si de pronto me encuentro con un caso en el que un supuesto perro pesa 540 kg, seguramente concluiré que es un error. En estos casos, lo mejor será borrar ese dato erróneo.
PASO 2. ¿Afecta a las
conclusiones?
Una vez descartado el error, tendríamos que investigar el grado de influencia de ese dato extremo en nuestros resultados, como he explicado antes. Si el outlier no produce cambios importantes (por ejemplo, afecta al valor del estadístico pero el p-valor sigue siendo significativo) ni supone una violación de los supuestos del análisis, entonces tal vez lo más cauto y transparente sea dejarlo ahí, pero indicar en el artículo que, de eliminar ese caso extremo, los resultados no cambiarían drásticamente. Esto además sería una señal de la robustez de las conclusiones.
Pero también podría ocurrir lo contrario, sobre todo si el outlier es además un caso influyente. Podría pasar, por ejemplo, que al eliminar ese caso extremo nuestra correlación se vuelva no significativa. ¿Y entonces qué hacemos? Contar el resultado sin más en un artículo no sería del todo honesto, pues sabemos que las conclusiones son muy dependientes de una sola observación. Ay, ay, ay…
Según indican algunos manuales y artículos sobre el tema (por ejemplo este), parece que en este tipo de situaciones (en las que el resultado cambia si quitamos el outlier), lo mejor es contar en el artículo los dos análisis: con y sin outlier. De esta forma no engañamos a los lectores.
La excepción vendría en aquellas situaciones en las que tenemos perfectamente claro que un resultado significativo se debe en realidad al outlier, como en el ejemplo que vimos más arriba y que os retomo a continuación:
En estos casos, quizá lo mejor es quitar el outlier e interpretar que no existe una asociación significativa, ya que el coeficiente significativo (el de la izquierda, r = 0.639) no describe el efecto que tenemos realmente en los datos.
Por regla general, imagino que lo más importante es siempre justificar bien las decisiones que tomemos, sean las que sean. Por ejemplo, puede ser razonable pensar que si una observación distorsiona enormemente las conclusiones deberíamos eliminarla, ya que no está “contando la misma historia” que el resto de los datos. Pero lo que es menos razonable es eliminar a todos los participantes que tengan una puntuación extrema sin mayor análisis ni explicación, o incluso sin decir nada en el texto, ¿verdad? Pues justo esto es lo que se hace rutinariamente en muchos campos de investigación. Al loro con eso.
Otras opciones: no todo va a ser borrar datos
Y es que hay otras alternativas que conviene conocer y probar antes de ponerse a eliminar los outliers sin ton ni son. La primera opción es probar algún tipo de transformación de los datos que minimice el efecto distorsionador del caso extremo (Zimmerman, 1995). Si el outlier es un caso con una puntuación excesivamente alta, por ejemplo, una transformación logarítmica o una raíz cuadrada puede reducir la distancia entre las observaciones:
La segunda alternativa es elegir otro modelo estadístico que tenga supuestos diferentes. Por ejemplo, ya hemos comentado que las medias son muy sensibles a los casos extremos, mientras las medianas son bastante más resistentes. Por regla general, la estadística no paramétrica (que no exige los mismos supuestos sobre las distribuciones de los datos) puede ser una buena alternativa cuando tienes uno de esos molestos outliers. Lo mismo puede decirse de las técnicas de bootstrapping. En esta línea, también hay aproximaciones “robustas” para casi todos los tipos de análisis que empleamos comúnmente en psicología. Por ejemplo, podemos utilizar medias recortadas (“trimmed means”), que básicamente consisten en calcular la media después de haber eliminado la proporción más extrema de los datos. Una contrapartida: este tipo de análisis suelen tener una pérdida considerable de potencia, así que repasa este post sobre la potencia estadística y decide si te interesa.
Por último, acabo de aprender que hay quien recomiendaimputar a los outliers valores que sí sean representativos de la muestra, como la media. Yo no tenía ni idea de que las técnicas de imputación podían emplearse en este contexto. ¡Las cosas que uno aprende cuando se prepara un post! Aun así, me parece un último recurso, y menos justificable que probar una transformación. Si alguien tiene una opinión diferente, soy todo orejas en los comentarios.
Referencias
Aguinis, H.,
Gottfredson, R.K., & Joo, H. (2013). Best-Practice Recommendations for
Defining Identifying and Handling Outliers. Organizational
Research Methods. 16(2), 270–301. doi:10.1177/1094428112470848
McClelland,
G. H. (2000). Nasty Data: Unruly , ill-mannered observations can ruin your
analysis. In H. T. Reis & C. M. Judd (Eds.), Handbook of Research
Methods in Social and Personality Psychology (Vol. 0345, pp. 393–411). Cambridge,
UK: Cambridge University Press.
Zimmerman, D. W. (1995). Increasing the
power of nonparametric tests by detecting and downweighting outliers. Journal of Experimental Education,
64, 71-78.
En esta segunda entrega de nuestro “curso de ESTADÍSTICA MAL”, continuamos con nuestro recorrido por los hábitos equivocados y las creencias erróneas al usar o interpretar la estadística. Si en el post anterior hablábamos de la necesidad de incluir controles adecuados, hoy trataremos otro tema fundamental: el de confundir correlación con causalidad.
Al menos en ámbitos de la psicología (e imagino que en otras ciencias será igual), la cantinela “¡correlación no es causalidad!” se ha convertido en una especie de martillo neumático con el que los profesores taladramos una y otra vez a los estudiantes. Pero, a tenor de las cosas que luego uno tiene que leer en artículos o noticias en los medios, parece que no acabamos de interiorizar la idea. ¿Qué es correlación? ¿Qué lo hace distinto de la causalidad? ¿Por qué es tan importante? De todo esto vamos a hablar ahora.
¿Qué es una correlación?
Empecemos por el principio. Cuando hablamos de “correlación”, estamos expresando la idea de que hay una asociación entre dos variables. Por ejemplo, estatura y peso (bueno, ya sé que coloquialmente decimos “peso” para referimos a masa, no me seáis tikismikis). En fin, tiene sentido pensar que las personas más altas también tengan mayor masa esquelética, muscular, etc., y por lo tanto pesen más, ¿verdad? Esto significa que muy probablemente peso y estatura van a correlacionar fuertemente.
Entenderemos mejor el concepto si lo visualizamos. En cada uno de los tres ejemplos que tenéis debajo, he representado la relación entre un par de variables. Cada punto negro en las figuras corresponde a una observación (un participante) en la que he medido las dos variables. Por ejemplo, si quiero investigar cómo correlacionan la estatura y el peso de un grupo de personas, para cada una de ellas recolecto la información: la persona 1 mide 1.60 cm y pesa 55 kg, la persona 2 mide 1.83 y pesa 92 kg, etc. Fácil, ¿no?
Estas figuras se llaman “gráficos de puntos” o “scatter plots”, y como habéis comprobado, se limitan a ubicar cada observación (cada persona) en los dos ejes de las variables (peso y estatura), dando lugar a lo que conocemos como “nube de puntos”.
Como podéis observar, las nubes de puntos se distribuyen tomando distintas formas, que he delimitado aproximadamente con esas elipses rojas: más achatadas, más estrechas… La “dirección” a la que apuntan las nubes viene demarcada por esa línea negra que les hemos ajustado a los datos (en otro post os explico cómo se calcula la línea. No sólo es fácil, sino que es la base del 90% de la estadística que se hace en psicología[1]). A la izquierda tenemos una nube con una línea “ascendente”, porque las personas con los valores más altos de estatura también tienen los valores más altos del peso. En el panel del centro, la relación entre las dos variables es justo la contraria, descendente, porque las personas más altas son las que menos pesan (un escenario un poco extraño). Por último, a la derecha vemos un ejemplo donde la nube de puntos tiene una forma aproximadamente circular, sin que la línea muestre una tendencia ni claramente ascendente ni claramente descendente.
Como ya imaginabais, la inclinación de la línea de ajuste nos indica la intensidad de la correlación, y viene descrita por un estadístico, el famoso “coeficiente de correlación de Pearson”, o simplemente r. Si el valor de r es positivo (panel de la izquierda, r = 0.76), significa que a mayores valores de x les corresponden mayores valores de y, mientras que si es negativo (panel del centro, r = -0.52), la relación es justo la inversa (a mayor valor de x, menor valor de y). Un valor cercano a 0 (panel de la derecha, r = 0.17) nos dice que las dos variables x e y no están correlacionadas, y por eso la línea estará casi plana.
Buf. ¿Cansados? Venga, ya se ha terminado el tostón de la parte técnica. Podemos seguir.
Ahora que sabemos lo que es una correlación, ¿qué diferencia este concepto de la causalidad? Bien. Como habéis podido comprobar, la correlación es una noción puramente estadística. Podemos encontrar una correlación significativa entre cualquier par de variables arbitrario: peso y estatura, número de cafés diarios y ansiedad, talla de calzado y capacidad matemática… En cada caso, sería tentador interpretar el resultado como si fuera una relación de causa-efecto: “te pones más nervioso porque tomas muchos cafés”. Pero en realidad la correlación no expresa más que lo dicho, una mera asociación entre variables, sin significado causal.
¿Para qué queremos hablar de causalidad?
Buena pregunta. En realidad, prácticamente todas las cuestiones de interés científico o práctico se pueden reducir a un “por qué”: ¿por qué me pongo nervioso después de tomar tres cafés? ¿por qué funciona (o no funciona) un tratamiento farmacológico? ¿por qué este grupo de pacientes muestra este síntoma? Es decir, casi siempre estamos interesados en obtener interpretaciones de tipo causal.
Esta obsesión que tenemos con la causalidad tiene todo el sentido del mundo. Si nos limitásemos a estudiar las correlaciones únicamente, nos quedaríamos en el plano descriptivo y perderíamos la oportunidad de intervenir en los fenómenos que estudiamos: plantear tratamientos, tomar medidas, prevenir eventos no deseados como por ejemplo una enfermedad… Todo eso es posible gracias a que alguien se ha planteado una pregunta en términos causales: “¿por qué ocurre este fenómeno?, ¿qué pasa si hago esto?”, etc.
¿En qué se diferencian causalidad y correlación?
En primer lugar, si la causalidad tiende a confundirse con la correlación, es porque en realidad la primera implica a la segunda. Así es: las causas correlacionan con sus efectos. Esto ocurre necesariamente, salvo que alguna otra variable enmascare esta correlación. De modo que, siendo rigurosos, habría que completar el mantra que da título al post: correlación no es causalidad… pero para hablar de causalidad necesito haber observado una correlación (como mínimo). Así que la correlación “sugiere” que podría haber causalidad (imaginadme haciendo el signo de las comillas con los dedos al escribir ese “sugiere, por favor).
¿Lo comprobamos? Si recogéis los datos y hacéis el análisis pertinente, será fácil advertir cómo fumar tabaco diariamente o trabajar en un entorno contaminado correlaciona con las dificultades respiratorias. Es de hecho una correlación bastante alta. A partir de esta correlación, quizá podríamos concluir que, por ejemplo, el humo del tabaco perjudica (causa dificultades) la capacidad pulmonar. Es decir, hemos interpretado causalmente la correlación.
Por otro lado, también sería muy fácil detectar una correlación entre, por ejemplo, la popularidad del famoso tema navideño de Mariah Carey (ya os lo sabéis de memoria: “All I want for Christmas...”) y el brote anual de la gripe, como ha advertido nuestra atenta amiga Lola Tórtola:
Efectivamente: llega esta época del año y ocurren dos eventos, siempre a la vez: empiezas a escuchar por todas partes ese estribillo ratonero “All I want for Christmas… is you!”, y a tu alrededor brotan como setas pañuelos al viento, señores tosiéndose en la mano y niños con los mocos colganderos. Supongo que sería tentador, vista esta potente correlación, concluir que efectivamente, ¡Mariah Carey es la causante de que tengas mocos y fiebre al final de cada año! ¿Será posible?
Evidentemente, aquí estaríamos cometiendo un error al interpretar la correlación como una relación de causa-efecto. Pero, ¿qué hace a esta correlación diferente de las que sí pueden interpretarse causalmente, como la del tabaco y los problemas respiratorios? Aquí entramos en terrenos filosóficos, y por tanto resbaladizos y densos como el plomo. No voy a adentrarme en este pantano por ahora, solo unas pinceladas. Por cierto, tal vez los autores que mejor explican todo este tema (farragoso e históricamente peliagudo) son Steven Sloman y Judea Pearl (el primero desde la psicología cognitiva, el segundo desde la inteligencia artificial). Os dejo las referencias más abajo para quienes queráis ampliar el punto.
Al grano. La primera diferencia es que la correlación es “simétrica”, mientras que la causalidad, por definición, no lo es. En los ejemplos anteriores de correlación, hemos tratado a las dos variables (por ejemplo, peso y estatura) en igualdad de condiciones. El peso correlaciona con la estatura. Y la estatura con el peso, exactamente igual. Como veis abajo, si invertimos los ejes del gráfico queda una línea igualmente ascendente y con idéntico valor para los estadísticos:
Con la causalidad, evidentemente, no sucede lo mismo. Causas y efectos son entidades ontológicamente diferentes. Las causas producen (o previenen) los efectos, pero los efectos no pueden producir las causas. A esta asimetría lógica también le sigue una asimetría temporal: las causas siempre preceden en el tiempo a los efectos. O es así, al menos, en el universo conocido y a la escala a la que nos movemos habitualmente los seres vivos.
La asimetría causal tiene algunas consecuencias interesantes, y una de ellas es que, para razonar en términos causales, no nos queda otra que plantearnos contrafactuales, es decir, escenarios hipotéticos en los que algo habría cambiado con respecto a la realidad actual. Por ejemplo, si una persona fumadora tiene dificultades respiratorias, yo podría preguntarme: ¿Y si esta persona nunca hubiera fumado un solo cigarrillo? Si me respondo a mí mismo diciendo que, probablemente, en ese escenario alternativo los pulmones de la persona estarían sanos, esto es un indicio de que estoy interpretando “fumar tabaco” como potencial causa de “problemas respiratorios”. Si no está la causa, ya no hay efecto.
Probad a hacer el mismo ejercicio con el otro ejemplo: ¿Y si prohibiésemos a las radios, televisiones, y medios en general, que reprodujesen la famosa canción de Mariah Carey? ¿Y si la erradicásemos completamente, quemando todas las copias, para que nadie la volviera a escuchar? ¿Mejoraría eso la incidencia anual de la gripe? Apuesto a que responderéis rápidamente que no, porque en vuestra cabeza no estáis interpretando a la canción como la causa del pico de gripe, sino como una mera coincidencia sin importancia. ¡Ay, cuidado con confundir la causalidad con la “casualidad”!
Y por último, una relación causal contiene uno de los mayores regalos que nos ha dado la naturaleza a los científicos: la intervención (AKA manipulación de variables). Partamos del escenario contrafactual antes mencionado: creo que, si el paciente nunca hubiera fumado tabaco, su capacidad respiratoria sería mucho mejor. Pero esto es una cábala, una mera idea, no he hecho más que imaginar qué habría pasado si el mundo hubiera sido distinto (esa es la definición de “contrafactual”). ¿Cómo comprobar si efectivamente el tabaco le ha causado el problema respiratorio? ¡Interviniendo sobre la causa! En este caso, podría hacer que la persona abandonase el hábito de fumar, y probablemente vería un resultado en términos de mejora de la salud respiratoria.
Pero esto va más allá. Como dice Steven Sloman, la naturaleza habla un lenguaje causal, y los científicos tenemos un método único para hacerle preguntas en ese mismo lenguaje: los experimentos. Sí, si queréis de verdad comprobar si una variable es la causa de otra, lo que necesitáis es un experimento: manipulamos (es decir, intervenimos) la variable que pensamos que es la causa, con la esperanza de que esto produzca un cambio visible en la otra variable. (A esta manipulación hay que acompañarla de los debidos controles, como expliqué en otro post). Si observamos dicho cambio en respuesta a la intervención en una situación controlada, entonces lo podemos atribuir al rol causal de la variable manipulada.
Cuando no podemos hacer un experimento: errores habituales
Por regla general, es arriesgado (y por tanto no recomendable) hacer una interpretación causal a partir de una correlación sin tener un experimento adecuado. Sin embargo, a veces un experimento es imposible por razones prácticas o incluso éticas. Imaginad por ejemplo que quiero saber si la proximidad a un elemento radiactivo produce cáncer: lógicamente no voy a hacer un experimento pidiendo a personas sanas que se paseen por ahí con una barra de uranio en el bolsillo, ¿no? Entonces, ¿qué hacemos?
En esas situaciones, solemos plantear otro diseño de investigación, conocido como cuasi-experimento. Ahora imaginad un estudio de este tipo: queremos saber si las personas ancianas que hacen ejercicio tienen mejor estado de salud. La pregunta implícita es causal: estamos suponiendo que, dado que el ejercicio es saludable, aquellas personas mayores que hacen ejercicio regularmente estarán más sanas. Pero, por motivos prácticos, no puedo hacer un experimento: es difícil asignar un programa de ejercicio mantenido en el tiempo a ciertas edades. Así que nos conformaremos con medir esas dos variables (hábitos de ejercicio físico y salud general) en una muestra de personas mayores de 65 años, para extraer la correlación entre ellas.
Hemos obtenido una correlación bastante alta (r = 0.77), lo suficiente para ser significativa. Esto quiere decir que las personas mayores que más ejercicio físico realizan son también las que experimentan mayor nivel de salud general. ¿Podemos ir más allá, y lanzar la recomendación de hacer ejercicio físico para todas las personas mayores, con la idea de que esto mejorará su estado de salud?
No, no podemos. Estaríamos cayendo en el error antes descrito, confundir causalidad con casualidad. Dado que mi diseño no es experimental (no ha habido asignación aleatoria a las condiciones, ni manipulación de variables), esta correlación puede interpretarse de muchas maneras. Por ejemplo:
La relación causal que habíamos propuesto: El ejercicio físico causa una mejora en la salud general.
La relación causal inversa: El mal nivel de salud general es la causa de que las personas más enfermas no puedan hacer mucho ejercicio (y de ahí la correlación).
Tal vez ni lo uno ni lo otro. Quizá lo que ocurre es que hay una causa común que no hemos tenido en cuenta, como por ejemplo la edad de los participantes, que es la que produce a las otras dos: las personas más jóvenes hacen más ejercicio y también están más sanas. Y por lo tanto, la asociación que observamos entre ejercicio y salud es una correlación espuria, no indicativa de causalidad, como la de Mariah Carey y la gripe.
Podríamos resolver este dilema de varias formas, pero a fin de cuentas la única que zanjaría la cuestión y nos permitiría afirmar que el ejercicio causa una mejora en la salud es hacer un experimento donde manipulásemos la causa potencial (ejercicio) para ver si hay una mejora en la salud, mientras controlamos por las posibles variables extrañas (edad, entre otras).
Conclusiones
Hemos escuchado ese mantra “correlación no implica causalidad” en infinidad de ocasiones, pero quizá nunca nos habíamos detenido a preguntarnos qué tienen en común ambos conceptos, ni cuáles son sus diferencias.
En el plano de las interpretaciones, lo importante es no confundirlas entre sí, y sobre todo no extraer conclusiones causales a partir de estudios correlacionales. Veremos cuánto tiempo pasa hasta que vuelva a ver un titular que cae en este error.
Referencias
Pearl, J., & Mackenzie (2018). The Book of Why: The New Science of Cause and Effect. Basic Books.
Sloman, S. (2009). Causal Models. How People Think About the World and Its Alternatives. Oxford University Press.
[1] Para los matemáticos que lleguen a este post y estén ahora mismo mordiéndose los nudillos de rabia: efectivamente, en este post estoy cometiendo una incorrección, y es la de hablar de “correlación” cuando realmente me refiero a una correlación lineal. ¡Claro que puede haber relaciones no lineales entre variables! Pero este post pretende ser formativo para estudiantes de grado, y ajustar líneas es básicamente todo lo que hacemos en psicología. Por cierto: el mejor modelo no es el que mejor ajusta a los datos, porque lo importante es la teoría que hay detrás. Abracitos.
Si hay un sentimiento constante que me acompaña desde que me propuse aprender estadística, es esa sensación por un lado estimulante y por otro un poco mortificadora de estar haciéndolo todo mal. O sea: ¿No compruebas los supuestos del análisis? MAL. ¿Interpretas un resultado no significativo como ausencia de efecto? MAL. Vale, ya sé que a palos se avanza, pero la experiencia es, como digo, a ratos un poco frustrante. Si te ves reflejado o reflejada en esto que estoy contando, entonces has llegado al lugar adecuado, porque esta serie de posts que estoy inaugurando la escribo para ti: sí, TÚ, que quieres usar la estadística para tu TFG, o para tu pequeña investigación, o simplemente para entender los papers, pero te has hartado de darte cabezazos contra la pared.
En este “curso” de estadística, voy a tratar uno por uno los errores más clásicos y frecuentes en el uso e interpretación de la misma. Espero que te guste.
Cuando no tienes un buen control.
Y voy a empezar hablando de uno de los problemas clásicos que me encuentro en los TFGs y TFMs, pero que también aparece con cierta frecuencia en artículos que han pasado revisión por pares (¡!). Me refiero a los estudios que no pueden concluir lo que dicen porque carecen de una buena condición de control. Y me diréis: ¿es tan grave el asunto? ¿y cómo se hace un buen control? Bueno, paso a paso. Vamos a ilustrarlo mediante ejemplos inspirados en artículos reales de diversas temáticas.
Ejemplo 1: Sin condición de control.
Poneos en situación. Un artículo en una revista sobre psicología educativa nos presenta una nueva técnica de adquisición de habilidades matemáticas. En vez de escuchar pasivamente al profesor y practicar los ejercicios de geometría (qué es una bisectriz, qué es un ángulo…), los autores proponen que, para aprender matemáticas, nada como echar una partida al DOOM en vez de ir a clase. Y tiene toda la lógica: jugando a DOOM, el estudiante se divierte, activa los circuitos cerebrales de recompensa [nota: inserte aquí el lector/a un poco más de jerga neuroeducativa, que no estoy inspirado], y sobre todo experimenta activamente con entornos tridimensionales y asimila la geometría casi sin darse cuenta. ¿Os convence la propuesta? No importa, sigo.
Los autores describen entonces su estudio. Primero, seleccionan a aquellos estudiantes de secundaria con la peor nota de la clase en matemáticas, los que más dificultades tienen. A continuación, para asegurarse, les hacen una prueba de conocimiento sobre geometría. Esta primera medición suele llamarse “línea base”, ya que se realiza antes del tratamiento, y nos permite ver cuál es el punto de partida. A continuación, los estudiantes tienen dispensa de clase de geometría para todo el curso, y en su lugar se dan una buena viciada matando cacodemonios. Por último, ya al final del curso, les vuelven a hacer un test de geometría para ver cómo han mejorado. Este diseño se conoce a veces como “pretest-posttest”, y seguro que si habéis estudiado psicología, pedagogía, o ciencias afines os va a sonar mucho. En contextos educativos, por ejemplo, no es nada raro encontrarse artículos como el que estoy describiendo (Knapp, 2016).
En cualquier caso, el resultado obtenido lo tenemos aquí:
¡Tiene buena pinta! Sin duda observamos una mejora en los estudiantes entre antes y después de hacerse unos expertos en asesinar marcianos. En concreto, la diferencia la evaluamos con una prueba t y es significativa: p = 0.021. ¡Genial! El tratamiento ha funcionado.
Bueno…
…Ya, imagino que os habéis dado cuenta. El estudio no demuestra que el tratamiento sirva para nada. ¿Dónde está el problema? En el diseño, que carece de un grupo de control, y por lo tanto no permite descartar otras posibles explicaciones para la mejora observada. Sólo por esta vez, vamos a enumerar unas cuantas explicaciones alternativas que se nos podrían ocurrir:
Eventos no controlados y Maduración: la línea base se obtuvo a principios de curso, y la medición final al final del mismo. Entre tanto han pasado meses, con todo lo que conlleva, incluyendo la maduración del sistema nervioso (especialmente relevante en el caso de niños pequeños), y también la posible influencia de los contenidos de otras asignaturas. Imaginad por ejemplo que a mitad del estudio, en la asignatura de lengua les enseñaron a leer de forma ordenada los problemas de matemáticas, reduciendo por lo tanto la cantidad de “fallos tontos” al responder, y sin que el videojuego haya tenido nada que ver.
Efecto de práctica: la segunda vez que se hace el test de geometría, no solo ha habido incontables horas de juego desde la última vez, sino que se da otra circunstancia. El test ya no es una experiencia nueva, incluso aunque cambiemos las preguntas. No es extraño que los estudiantes hayan adquirido cierta destreza con la práctica, que estén menos ansiosos, o incluso que hayan aprendido de sus errores.
Regresión a la media: esta explicación la suele pasar por alto todo el mundo. Fijaos en que hemos seleccionado para el estudio aquellos niños que peor nota tenían en geometría. Por lo tanto, la próxima vez que los midamos, tienen más probabilidad de mejorar dicha nota. Pero esto no quiere decir que hayan aprendido nada, se trata de un conocido artefacto estadístico que tal vez requiera un post por sí mismo.
Me dejo muchas posibles explicaciones en el tintero, pero el mensaje creo que queda claro clarinete: necesitamos un grupo de control. La pregunta ahora es ¿qué tipo de control?
Ejemplo 2: Un mal control (controles pasivos).
Vamos a pensar otra situación, esta vez en el contexto clínico. En este ámbito, con frecuencia nos interesa saber si un tratamiento funciona, por ejemplo, para reducir la depresión de los pacientes. Todavía con cierta frecuencia me encuentro con estudios que emplean un control de tipo pasivo, cuyo exponente más conocido es el control “de lista de espera”. La idea es la siguiente. Reunimos un grupo de pacientes con depresión. A la mitad de ellos les aplicamos nuestro nuevo tratamiento (grupo “experimental”). A la otra mitad (grupo control) les diremos que están en lista de espera para recibir el tratamiento. Después (una vez completada la intervención en el grupo experimental) mediremos a los dos grupos en el mismo momento.
Al medir a todos los participantes a la vez estamos evitando algunos de los problemas del caso anterior. Imaginemos que el resultado es el siguiente:
El análisis estadístico me indica que el grupo experimental tiene una puntuación de depresión significativamente menor que el grupo control, p = 0.03. A partir de ahí, podría concluir que el tratamiento ha funcionado.
Otra vez: no, no lo puedo concluir. ¿Por qué? Esta vez sí que tengo un grupo de control para comparar. Lo que pasa es que el grupo de control es muy malo. Pensadlo bien, mirando la figura: ¿me está diciendo la figura que el grupo experimental ha reducido la depresión? ¿o quizá es que el grupo control ha aumentado la suya?
Efectivamente. El control de lista de espera es muy mal control, y no sé por qué se sigue utilizando hoy en día (médicos y nutricionistas, daos por aludidos). El problema es que los pacientes que están en lista de espera son conscientes de que no se los está tratando, lo cual afecta a su salud percibida, calidad de vida, y otros parámetros relevantes. En el caso de la depresión, se ha documentado que las listas de espera tienen un efecto negativo, conocido como “efecto nocebo”, de forma que pueden observarse en los controles empeoramientos de hasta un 30% con respecto a la línea base (Furukawa et al., 2014). En definitiva, el gráfico de arriba podría interpretarse como que el tratamiento no funciona nada, ya que simplemente mantiene a raya el efecto perjudicial de la lista de espera.
¿Qué tipo de control podríamos utilizar en vez de la lista de espera? En muchos casos podríamos plantearnos un control con tratamiento de tipo “placebo”, es decir, un tratamiento que es realmente inactivo (no va a producir una mejoría sustancial), pero que el participante pueda pensar que es activo. Por ejemplo, cuando el tratamiento es farmacológico, el placebo puede ser una pastilla con el mismo aspecto y sabor, sólo que sin el principio activo. En el caso de una psicoterapia, podemos plantear alguna actividad que iguale al tratamiento en cuanto a sensación de estar siendo atendido y escuchado, pero que carezca del elemento principal al que teóricamente atribuimos la eficacia. Se ha comprobado cómo esa percepción y expectativa de estar siendo tratado pueden mejorar el estado de los pacientes, lo que se conoce como el “efecto placebo”.
De hecho, hoy en día todos los medicamentos comerciales se prueban (como mínimo, ¡minimísimo!) frente a un placebo, de forma que sólo se aprueban si demuestran ser más eficaces que el mero efecto psicológico que proporciona la expectativa de tratamiento. Sin embargo, incluso el placebo es un control poco exigente (es que es pedir muy poco, “curar más” que una pastillita de azúcar). Deberías plantearte alternativas mejores, más rigurosas. Por ejemplo, comparar tu nuevo tratamiento con el tratamiento de referencia de esa patología.
Ejemplo 3. Más efectos de las expectativas
El efecto placebo es un buen ejemplo de cómo las expectativas del paciente pueden afectar a su evolución. ¿Cabría pensar en la posibilidad de que también influyeran las expectativas del experimentador? ¡Por supuesto!
Veréis, en un artículo clásico, Bargh et al. (1996) demostraron un curioso efecto que podríamos llamar “facilitación viejuna” (elderly priming). Este tipo de efectos de priming o facilitación consisten en la exposición, de manera más o menos sutil, a unos estímulos que supuestamente “activan” en los participantes los esquemas conductuales con los que están conectados, produciendo así cambios en la conducta que son muchas veces inconscientes para el participante. En este experimento en concreto, Bargh y colaboradores citaban a los participantes en el laboratorio. Allí los entretenían realizando tareas mientras les leían una serie de palabras. En el grupo experimental, las palabras tenían que ver con la vejez, como por ejemplo “anciano”, “obsoleto”, “cansado”… En el grupo control, las palabras correspondían a otro campo semántico (“monitor”, “sediento”…). Al acabar la tarea, los participantes abandonaban el laboratorio, y el experimentador cronometraba cuánto tiempo tardaban en hacerlo. El resultado es que los participantes del grupo experimental, que habían sido expuestos a las palabras que tenían que ver con la vejez, salían caminando significativamente más despacio. Es decir, el esquema de “vejez” activado mediante las palabras se había transferido a sus movimientos corporales, haciendo que se muevan “como ancianos”.
Hasta aquí todo nos encaja: hay un grupo de control, el control no está pasivo sino que realiza una tarea de características muy similares… ¿dónde está el problema?
En 2012, Doyen et al. realizaron una serie de intentos de replicar este estudio, y llegaron a una conclusión muy interesante. El efecto de elderly priming sólo se replicaba cuando el experimentador que cronometraba a los participantes conocía la hipótesis del estudio, y a qué grupo correspondía cada participante. Cuando la medición se automatizaba por medio de un cronómetro electrónico, el efecto se desvanecía. La conclusión es que probablemente el efecto descrito inicialmente en el artículo de Bargh y colaboradores se debía (en parte) a una contaminación de las expectativas del experimentador. Sin proponérselo, incluso sin darse cuenta, el propio experimentador estaba sesgando las mediciones al retrasar inadvertidamente la pulsación del reloj en uno de los grupos con respecto al otro.
De modo más general, las expectativas del investigador pueden influir claramente en el resultado de un estudio. Por ejemplo, es casi inevitable que un fisioterapeuta que está tratando a un paciente especialmente grave le dedique algo de esfuerzo extra, mientras que se esmere menos en el grupo “placebo”, donde sabe que su intervención no debería producir un efecto.
Hoy en día se intenta prevenir este tipo de problemas mediante el uso de controles “doble ciego”. En un control de este tipo, ni el paciente ni el experimentador conocen a qué grupo corresponde cada participante, de modo que sus expectativas no pueden influir directamente en la medición (Holman et al., 2015).
Ejemplo 4. Controles incomparables
Saltamos a otro contexto habitual para hablar de otro de los problemas típicos con los controles. Sabéis que las personas que han sufrido un ictus o un accidente cerebrovascular pueden mostrar déficits serios en áreas como la coordinación de movimientos o el habla. Las secuelas pueden ser tanto físicas como cognitivas. Para tratar a estos pacientes, se han diseñado muchas intervenciones basadas en ejercicios de neuro-rehabilitación, que prometen bien recuperar parte de la función perdida, bien compensarla.
Vamos a imaginar que has diseñado un programa de rehabilitación neurológica para mejorar la agilidad mental en pacientes con ictus. Como eres una persona aplicada, has leído atentamente los ejemplos anteriores de este post, y estás dispuesto/a a evitar los errores comentados. Así, decides que vas a tener un grupo de control (¡bien hecho!), y que dicho control va a recibir un tratamiento en vez de quedarse sin hacer nada (¡chachi!). Incluso optas por un diseño un poco más sofisticado: vas a medir a los dos grupos en dos ocasiones, antes y después del tratamiento, de forma que podrás comparar el efecto de la intervención en ambos grupos. Así, realizas tu estudio aplicando tu técnica a una muestra de pacientes con ictus a la que has medido previamente, y lo comparas con un grupo de controles sanos que ha pasado por un tratamiento placebo que se asemeja en tiempo y forma, pero no contiene los ingredientes clave cuya eficacia quieres demostrar. El resultado quedaría tal que así:
A simple vista, parece que el tratamiento funciona, puesto que los pacientes mejoran notablemente, en mayor medida que los controles.
Sin embargo, el haber tomado las cautelas mencionadas no te libra de los problemas. Y es que reclutar pacientes con ictus es costoso, lento y caro. Así que tus controles han sido personas sanas. Observa con cuidado la diferencia de puntuaciones en el momento “pre”, antes de la intervención. ¿Empiezas a ver dónde está el fallo? ¡El estudio no te dice absolutamente nada sobre la eficacia del tratamiento!, porque tu condición de control no es comparable con la experimental. En el momento de la primera medición (línea base) los dos grupos ya son completamente diferentes.
En este caso, lo apropiado habría sido hacer un grupo de control con pacientes comparables a los del grupo experimental. En este tipo de estudios contamos con una dificultad añadida, y es que es muy difícil encontrar casos que sean realmente comparables. Por ejemplo, un ictus tiene secuelas que pueden ser de características y gravedad muy diferentes a otro, y el pronóstico del paciente está muy ligado a factores individuales como el sexo, la edad, o el nivel de salud general… Si quisiéramos hacer las cosas bien, tendríamos que emplear una muestra que controlase todos estos factores uno por uno. Habitualmente, se utilizan técnicas como el “apareamiento”: para cada participante del grupo experimental, se localiza otro para el grupo control que tenga valores similares en todos estos parámetros. Una labor complicada y tediosa.
Conclusiones
Vamos a terminar recapitulando. En primer lugar, ¿para qué queremos un grupo o una condición de control? Para descartar explicaciones alternativas a nuestros resultados. Esto significa que tenemos que: (1) identificar todas las posibles variables contaminadoras o fuentes de error, (2) igualar a los grupos en todas estas variables, o intentar que las diferencias se repartan aleatoriamente entre los grupos. Un buen grupo de control es idéntico al grupo experimental salvo en una cosa: justo la que es objeto de nuestra manipulación, o la que queremos investigar.
Esto no es tan fácil como parece. Es habitual que nos rompamos la cabeza decidiendo el mejor diseño, y que los revisores imaginen sin problema explicaciones alternativas que ni se nos habían pasado por la cabeza, que requieren controles adicionales. Por otra parte, a veces se publican artículos con controles muy defectuosos. Os aseguro que los ejemplos que he contado en este post están inspirados en diseños de estudios reales, la mayoría de ellos publicados, por increíble que parezca.
Los anteriores posts de esta serie de estadística introdujeron dos conceptos clave para todo aquel que quiera dedicarse a la investigación en ciencias sociales, e incluso para cualquiera que pretenda leerse un artículo científico con un poco de rigor: hablamos del tamaño del efecto y de la potencia estadística. Ojalá mis cursos de estadística y diseño de investigación hubiesen empezado por aquí. Primero, porque me habrían ahorrado más de un dolor de cabeza posterior al planear estudios que jamás van a producir ningún resultado fiable, y segundo porque cuando los entiendes correctamente, otros problemas y conceptos se vuelven casi evidentes.
Repasemos un poco, por si acaso. El tamaño del efecto es una medida de la magnitud del efecto o diferencia que estamos buscando, o bien del que observamos en nuestro estudio. Por ejemplo, si quiero saber si un tratamiento para la ansiedad funciona, estoy asumiendo que en la población “existe” una diferencia entre quienes siguen el tratamiento y quienes no lo siguen, y que esa diferencia tiene determinada magnitud, como podría ser “los síntomas se reducen un 40% gracias al tratamiento”. No solo queremos saber si algo funciona, sino “cómo de bien” funciona. Asimismo, si ahora realizo un estudio en el que comparo pacientes que siguen el tratamiento y controles que no, la diferencia entre los dos grupos será mi efecto observado, que de nuevo tendrá determinado tamaño o magnitud. En principio, el efecto observado es una estimación del efecto real poblacional, así que debería tener en este caso un valor similar, 40%, pero lógicamente, debido al error de muestreo, si repito el estudio iré observando distintos tamaños del efecto: 38%, 45%… Por último, recordad que, cuando nuestro diseño consiste en comparar dos grupos, el tamaño del efecto observado se puede expresar con un estadístico llamado d de Cohen.
Por otro lado, la potencia estadística es la capacidad que tiene mi estudio de producir un resultado significativo (p < 0.05) cuando el efecto real existe en la población (o sea, tiene una magnitud distinta de cero). La potencia se puede expresar como probabilidad, o como proporción: es el porcentaje de estudios que, si se llevaran a cabo, producirían una p < 0.05 si el efecto realmente existe. Si recordáis, en psicología tenemos un problemilla con la potencia (je je), y es que tradicionalmente solemos emplear estudios con potencias incluso por debajo del 50%, lo cual quiere decir que la mitad de los estudios no van a producir resultados significativos… a pesar de que los efectos quizá sí están ahí. Una manera de mejorar la potencia sensiblemente es emplear muestras más grandes, porque esto reduce el error de muestreo.
Bien, hasta aquí el repaso de los anteriores posts. Lo que nos había faltado por hacer es justamente conectar estas dos piezas. No tiene sentido hablar de potencia estadística, así, en el vacío. La potencia va ligada al tamaño del efecto. Ahora entenderéis por qué.
Por qué queremos muestras grandes
Imaginad que estamos investigando un fenómeno que produce efectos pequeños-medianos, como es lo más habitual en psicología. Un ejemplo podría ser el de un tratamiento cuya efectividad probablemente va a ser marginal, o el de una manipulación de “priming” cuyo efecto en el comportamiento va a ser en todo caso sutil y difícil de capturar (ej: pensar en palabras relacionadas con la vejez hace que te muevas más despacio)… Vamos a examinar la potencia de nuestro estudio bajo dos escenarios posibles: muestras pequeñas, y muestras grandes. Para ello, como de costumbre, podéis ir a esta web (https://rextester.com/l/r_online_compiler) y copia-pegar el código que tenéis abajo y que os he preparado.
sd <- 10 #desviación típica de la población
numMuestras <- 10000 #número de experimentos que vamos a generar
pDist<- function(grupo1.mean, grupo2.mean, n){
pvalue <-c()
for(i in 1:numMuestras){
grupo1.sample <- rnorm(n, grupo1.mean, sd)
grupo2.sample <- rnorm(n, grupo2.mean, sd)
pvalue <- c(pvalue, t.test(grupo1.sample, grupo2.sample)$p.value)
d <- (grupo1.mean-grupo2.mean) / sd
power<-length(which(pvalue < 0.05))/numMuestras
}
hist(pvalue, main= paste0("d: ", round(d, 3), ", N: ", n*2, ", Potencia: ", round(power, 3))) #genera el gráfico
}
Este código está creando una función para simular un gran número de experimentos aleatorios (10.000) a partir de una población que le especifiquemos, y dibujar su distribución en forma de histograma, al estilo de lo que hicimos en el post sobre la potencia. Ejecutadlo. Ahora solo falta que llaméis a la función pasándole los argumentos correspondientes, que en este caso son las medias que asumimos para la población (que van a determinar el tamaño del efecto), y el tamaño muestral. Teclead en la consola de R:
pDist(54, 50, 10)
Con esto le estamos especificando a R que tiene que generar las muestras a partir de dos poblaciones cuyas puntuaciones medias son 54 y 50, respectivamente (lo cual implica un tamaño del efecto de d = 0.40, es decir, pequeño-mediano), y que el tamaño de cada grupo de datos extraído de estas poblaciones es de 10 (o sea, que en total, el estudio tendría N=20 sujetos). La función nos habrá generado un histograma con la distribución de p-valores, similar a esta:
¿Ya lo tenéis? Fijaos en que la potencia es bastante baja: 0.131. Es decir, sólo el 13% de los estudios simulados han conseguido detectar el efecto. Los demás no han conseguido encontrar el resultado significativo. Si hubiéramos hecho un estudio real, la probabilidad de éxito es tan baja que sería una pena derrochar los recursos. Vamos a ver qué pasa si aumentamos los tamaños de cada muestra, tecleando lo siguiente:
pDist(54, 50, 50)
Ahora le estamos pidiendo muestras bastante más grandes: de 50 participantes por grupo (en total, N=100), en vez de los 10 de la simulación anterior. Las medias las hemos dejado como estaban. El histograma revela que este cambio en la N ha afectado notablemente a la potencia:
Ahora la forma de la distribución es mucho más asimétrica, y aproximadamente el 50% de los estudios son significativos. Sigue siendo una potencia mediocre, dado que la mínima recomendada es del 80%, pero algo hemos avanzado. Deberíamos buscar una muestra mayor de 100 participantes si queremos obtener buena potencia.
La pregunta que os quería lanzar ahora es: ¿realmente necesitamos una muestra tan grande en todos los estudios? Claro que no. Lo que está pasando aquí es que estamos buscando un efecto que hemos definido como pequeño-mediano en la población (d=0.40). Pero si el efecto que buscamos fuera más grande, la muestra necesaria para obtener una potencia del 80% podría ser bastante más pequeña. Para entenderlo, lo mejor es que sigamos jugando con las simulaciones. Volved a R y teclead lo siguiente:
pDist(62, 50, 10)
Estamos pidiendo a R que genere muestras de dos poblaciones que, ahora, difieren notablemente en sus puntuaciones medias: 62-50=12 puntos de diferencia. Se trata de un tamaño del efecto de d=1.2, lo que consideramos “enorme”. Aprovechad para recrearos la vista con la siguiente figura, porque en psicología casi nunca tenemos la ocasión de detectar efectos tan grandes. Vamosa ver qué tal le ha ido a la potencia con este efecto enorme y untamaño muestral pequeño, de 10 participantes por grupo:
¡Guau! Fijaos en el salto. Seguimos teniendo una muestra pequeña, de 20 participantes nada más. Pero, dado que el efecto que buscamos ahora es muy grande, con esa muestra diminuta alcanzamos una potencia de 0.7, es decir, el 70% de los estudios son significativos.
La moraleja de toda esta historia es la siguiente: no se trata de aumentar el tamaño muestral porque sí, y cuanto más grande mejor. No. Se trata de escoger un tamaño muestral suficiente para detectar un efecto del tamaño del que estoy buscando con una potencia adecuada (idealmente, mayor del 80%).
Lupas y microscopios
Tal vez os ayude la metáfora que empleo en mis clases. Los efectos son de distintos tamaños: pequeños como moléculas (d=0.10, d=0.05…), o grandes como camiones (d=1.20). Lógicamente, un camión es más fácil de observar que una molécula. Para ver el camión no necesito ningún instrumental específico, mientras que para ver la molécula necesito un microscopio.
Por otro lado, la potencia es como un instrumento óptico que puede aumentar un objeto en distintos grados. Pensad en un estudio poco potente, con una N pequeña, como si fuera una lupa: tiene la capacidad de aumentar un poco el tamaño del efecto que busco, pero no mucho. Un estudio muy potente sería equivalente a un microscopio de barrido, capaz de magnificar el tamaño de objetos muy, muy, pequeños.
Aquí viene el punto importante: si mi objetivo es detectar
una molécula, no tiene sentido que emplee una lupa, ¿verdad? No voy a conseguir
ver nada. Necesito un microscopio. Pero en otras ocasiones me interesan efectos
grandes, como camiones, que puedo observar con la lupa, o con unas gafas de
leer, sin necesidad de recurrir al microscopio. El tamaño muestral va en consonancia con el tamaño del efecto.
Otras veces suceden cosas extrañas. Imaginad que leéis un estudio donde, con una muestra pequeña (N=10 sujetos) han encontrado un efecto minúsculo (d=0.10). Pues bien, casi con toda seguridad podéis sospechar que hay algún error o que esa estimación es muy poco fiable. Pensadlo: es como si alguien te estuviera contando que ha visto una molécula a simple vista, ¡sin microscopio ni nada!
Esta metáfora también nos ayuda a entender un dilema: en estos ejemplos, yo conozco de antemano el tamaño del objeto que estoy buscando. Sé si lo que busco es un camión o una molécula, y escojo la herramienta en consonancia. En la vida real, sin embargo, no contamos con esta información. Yo no sé si el efecto que busco es grande, pequeño o mediano. Y por lo tanto siempre hay cierta dificultad para escoger el tamaño muestral adecuado. ¡Qué pena!
Análisis de potencia
Esto nos lleva al siguiente punto, los llamados “a priori power analysis” o “análisis de potencia a priori” que muchas revistas piden a los autores. Se trata en su mayor parte de análisis dirigidos a decidir cuál es el tamaño muestral adecuado para un estudio antes de llevarlo a cabo, de forma que garanticemos una potencia aceptable (por ejemplo, del 80%). Aunque las técnicas para realizar estos análisis están evolucionando constantemente, una de las tradicionales y más empleadas sería como sigue:
Paso 1: Lee la literatura sobre tu tema de investigación, y extrae el tamaño del efecto observado promedio. O bien, simplemente decide si es pequeño/mediano/grande en función de las convenciones habituales.
Paso 2: Asumiendo que ese efecto observado es una buena estimación del efecto real, decide cuál tiene que ser tu tamaño muestral para alcanzar la potencia del 80% o el 90%.
Paso 3: Ahora realiza el estudio con ese tamaño muestral.
A pesar de que muchos revisores siguen pidiendo que los
autores realicemos una variante de estos tres pasos, lo cierto es que la lógica de este análisis hace agua. El
problema está en el paso 2: “Asumiendo
que ese efecto observado es una buena estimación del efecto real”. Y es un
problema, ¡porque los tamaños observados
que se publican en la literatura seguramente no tienen nada que ver con el
tamaño “real”! Ahora entenderemos por qué.
En primer lugar, muchos de los estudios publicados (sobre todo los anteriores a 2011 y a la famosa crisis de credibilidad en psicología) tienen baja potencia. Esto significa dos cosas: (1) que la mayoría de ellos fracasarían en producir un resultado significativo, (2) que la estimación del tamaño del efecto, d, no será fiable, por culpa del error de muestreo. Ahora bien, es muy raro encontrar resultados no significativos que se hayan publicado, sobre todo con anterioridad a la crisis. ¿Cómo es que, teniendo una potencia ridícula, a veces del 20% ó 30%, no veamos más que estudios con resultados significativos? ¿No contradice esto todo lo que nos has contado, Fernando?
Efectivamente, lo contradice, pero tiene una explicación: la publicación selectiva, o “sesgo de publicación”. Imaginad que los investigadores realizan 10 estudios sobre un tema, usando diseños de potencia baja, de un 20%. El 80% de estos estudios (8 de los 10) no será significativo, y precisamente por eso nadie los publicará. Sin embargo, los dos estudios (el 20%) que sí salen significativos son los únicos que sí se van a publicar. Así que cuando calculas el tamaño del efecto a partir de los resultados publicados en la literatura, ojo: ¡estás obviando todos los estudios que no fueron significativos!
Además, como las muestras pequeñas están más contaminadas
por el error de muestreo, las estimaciones del tamaño del efecto observado en
esos estudios serán muy volátiles. Y lo que es peor, como justo estamos
seleccionando para publicar esos poquitos estudios significativos, estamos
introduciendo un sesgo: los estudios significativos son los que van a tener las
estimaciones más exageradas, más desviadas del tamaño poblacional real. En
definitiva, que el tamaño del efecto “promedio”
va a estar sobreestimado.
Hoy en día hay otras formas de planificar el tamaño muestral que no tienen estos problemas, e incluso hay soluciones como el muestreo secuencial. Sin embargo, me apetecía comentar este caso porque aun a día de hoy es bastante frecuente que lo pidan en las revistas.
“The new statistics”
Y voy a terminar el post de hoy comentando algo que tiene mucha relación con lo que hemos estado explicando estos días. Si habéis leído los posts anteriores, tal vez os haya preocupado (y si no es así, ¡debería!) el problema que hemos estado describiendo acerca de la potencia estadística y la facilidad con la que pueden aparecer “falsos positivos” (error tipo I). En el fondo, esto puede tener que ver con la costumbre (en mi opinión, muchas veces innecesaria) de buscar en nuestros estudios respuestas dicotómicas: o el tratamiento funciona, o no; o el efecto existe, o no. Esta dicotomía viene marcada por la forma de utilizar los p-valores como una guía para tomar decisiones con solo dos posibles opciones: si el p-valor es menor del umbral (usualmente 0.05), entonces decimos que el resultado es significativo. De lo contrario, el resultado no es significativo. Entiendo que en ocasiones sí que nos interesa usar la investigación para tomar decisiones binarias de este tipo, “o sí o no”. Pero en otras muchas situaciones preferiríamos tener una respuesta más matizada: “el tratamiento mejora sobre el control un 40%, o un 60%”. “La diferencia entre dos grupos es de 20 puntos”. Es decir, querríamos cuantificar los efectos que encontramos, y la incertidumbre con la que los hemos estimado, pero no siempre queremos reducirlo todo a una decisión de tipo “sí/no”, ¿verdad? Recordad el ejemplo del post anterior, en el que un tratamiento podría funcionar significativamente mejor que otro, y sin embargo producir un cambio tan minúsculo que en términos prácticos no nos sirve. Además está la arbitrariedad del umbral: un p-valor de 0.049 es igual de significativo que uno de 0.0001. ¿Cómo te quedas?
Así que los estadísticos se han roto bastante la cabeza intentando diseñar herramientas mejores para analizar nuestros datos en esas situaciones. Una de esas propuestas es la de Geoff Cumming (2013): “The new statistics” (sí, el título es muy ambicioso). La idea es la siguiente: en vez de calcular un p-valor para nuestro estudio, vamos a centrarnos en estimar el tamaño del efecto observado. Si la estimación es buena (ya sabéis, muestras grandes, medidas precisas), se aproximará al efecto real en la población. Además, calcularemos un intervalo de confianza para ese efecto que hemos encontrado. En definitiva, movemos el foco de las decisiones (p-valores) a la estimación (tamaños del efecto). Así, en vez de decir que “mi resultado ha sido significativo”, lo que diré es que “he encontrado un efecto de tamaño 0.54 +/- 3” (siendo ese “3” la cuantificación de la incertidumbre acerca de la estimación puntual).
La propuesta tuvo bastante repercusión en su momento, apareció en editoriales y guías para los autores de algunas revistas, y no ha parado de enriquecerse con nuevas opciones e investigaciones (si queréis aprender más, visitad el blog del autor). Sin embargo, parece que esta visión no acaba de calar del todo, y se han señalado muchos problemas con ella. Aparte de las cuestiones técnicas en las que no voy a entrar (tampoco estoy capacitado para opinar sobre ellas), sospecho que también existe un factor humano. Creo que al final, como pasó también con otra famosa herramienta estadística, los Bayes Factors, hay una tentación irresistible en todas las personas (y en los investigadores, cómo no), por crearse una sensación de certeza, aunque sea vacua e ilusoria. Creo que imponer umbrales fijos y dicotomías, como la regla de decisión basada en los p-valores (significativo/no significativo) sirven precisamente para eso: para generarnos una impresión de confianza, de seguridad. O sí o no. Para borrar los matices. Honestamente, no comparto esta manía de convertirlo todo en una decisión binaria, y de hecho me parece que podría llevarnos a confusiones, prácticas científicas cuestionables (sesgo de publicación, p-hacking), exageraciones… Buf. Pero podemos hablar de ello otro día.
Vamos a aprovechar el verano para repasar algunos conceptos clave de estadística, que sé que algunos/as ya estáis dándole al temario del PIR, o bien simplemente os va la marcha como a mí y no os importa leer de estos temas desde la playa. Esta vez vamos a avanzar un poco con respecto al último post, para tratar otro de esos temas que ojalá me hubieran explicado en clase cuando empecé a estudiar estadística: el tamaño del efecto.
¿Cómo de bien funciona un tratamiento?
Comenzaremos con un ejemplo para ponernos en situación.
Imaginad que he descubierto un tónico crecepelo y quiero ponerlo a prueba. ¡Yo
estoy convencido de que funciona! La pregunta es: sí, pero ¿cómo de bien funciona?
Para saberlo, como de costumbre, haremos un experimento. En este caso, basta con reclutar una muestra de pacientes con calvicie (¡ay!), y asignarlos al azar a uno de dos grupos: en el grupo Tratamiento, beberán mi tónico milagroso, mientras que en el grupo Control tomarán un placebo (un jarabe sin propiedades especiales más allá de su alegre sabor a fresa). Al cabo de un mes, examinaré la calvorota de todos los participantes, contando el número de cabellos nuevos que han crecido en este periodo. En resumen, obtendré dos cantidades: el número promedio de cabellos nuevos en el grupo Tratamiento, y el número promedio de cabellos en el grupo Control. Si mi tónico crecepelo funciona, la media del grupo Tratamiento será significativamente mayor que la del grupo Control. ¿Hasta aquí bien?
Imaginemos que hago mi estudio y el resultado es el siguiente: En el grupo Tratamiento, de media han crecido unos 4000 cabellos nuevos por cada participante, mientras que en el grupo Control apenas llegamos a un pírrico promedio de 2 cabellos nuevos. Esta diferencia es evidentemente significativa (si calculamos el p-valor, será inferior a 0.05).
Está claro que, si obtuviera un resultado como este, ya me estaría apareciendo el símbolo del dólar en las pupilas y me habría puesto a meditar sobre si prefiero comprarme un yate con 50 metros de eslora o una mansión de lujo, porque ciertamente el tónico está funcionando de maravilla. Pero antes de dejarnos llevar por la fantasía, pensemos en otra situación bastante diferente que podría haberme encontrado:
Imaginad que el resultado hubiera sido que, en promedio, los cabellos nuevos en el grupo Tratamiento fueran 4, frente a sólo 2 en el grupo Control. Esta diferencia es significativa (p < 0.05), de lo cual puedo concluir que efectivamente el tónico funciona. Por otro lado, la ventaja de utilizarlo es claramente insuficiente. Sí, estamos duplicando el número de cabellos con respecto al control, pero no creo que nadie en su sano juicio vaya a pagar un pastizal por esos dos cabellos extra en la calva. Habrá que cambiar de proyecto, que este no parece muy provechoso.
¿Qué enseñanza extraemos de esta historia? En primer lugar, que no basta con preguntarse si un tratamiento funciona o no, sino que también hay que plantearse cómo de bien funciona. Imaginad que el tónico tuviera efectos adversos, o fuera muy caro: merecería la pena tal vez si a cambio nos proporciona una mata de pelo como la de El Puma, pero claramente nadie lo utilizaría si la ventaja fuese casi inapreciable. O si queréis llevaros el ejemplo a la psicología: ¿deberían los pacientes acudir a un terapeuta que, en promedio, sólo mejora sus niveles de ansiedad el equivalente a un punto en un test como el STAI?
En términos estadísticos, el p-valor nos dice si el tratamiento funciona o no, es decir, si esa diferencia entre los dos grupos es lo bastante grande como para que sea muy improbable observarla por puro azar. Por otro lado, la diferencia entre las medias de los dos grupos (en este caso, 4000 – 2 = 3998 cabellos nuevos, o bien 4 -2 = 2 cabellos nuevos) es lo que vamos a llamar “tamaño del efecto”, una medida de cómo de bien funciona un tratamiento, es decir, una cuantificación aproximada de la diferencia entre las poblaciones. Sobre este último concepto vamos a profundizar hoy.
Visualizando el tamaño del efecto
Para entender mejor qué es el tamaño del efecto, al menos en un diseño de este tipo (dos grupos en los que queremos comprar las medias), vamos a jugar con unas simulaciones en R. Por si acaso, si alguien prefiere empezar desde el principio, la lógica de todo el análisis se explica en este post previo.
mean.G1 <- 55 #media en el grupo 1
mean.G2 <- 50 #media en el grupo 2
sd <- 10 #desviación típica (vamos a asumir que es idéntica en ambos grupos)
#Dibujamos las dos muestras:
plot(x=seq(1: 100),
dnorm(seq(1:100), mean.G1, sd),
type="l", xlab = "", ylab="", col="red",
main=paste("Diferencia: ", mean.G1-mean.G2, ", SD = ", sd))
lines(x=seq(1: 100),
dnorm(seq(1:100), mean.G2, sd),
type="l", col="blue")
Como siempre, podéis probar y cambiar el código en esta web sin necesidad de instalar R ni nada (https://rextester.com/l/r_online_compiler). Este trozo de código dibuja las distribuciones normales con los parámetros (media y desviación típica) de las dos poblaciones de interés: quienes toman el tónico crecepelo y quienes toman el jarabe placebo. En este caso, hemos supuesto que las dos poblaciones van a diferir de forma que en el grupo Tratamiento han crecido, de media, 55 pelos nuevos, mientras que en el grupo Control han crecido 50. Esta diferencia puede producir un resultado estadísticamente significativo siempre que la muestra empleada sea suficiente. Podéis comprobarlo, por ejemplo, para una N de 30 participantes por grupo:
Tened en cuenta que este resultado no va a ser significativo siempre, debido a que estamos generando una muestra aleatoria cada vez que ejecutamos el código y por lo tanto estamos a merced del error de muestreo, como vimos en post anteriores (probad a ejecutar esta misma línea cuatro o cinco veces, y ved cómo cambia el p-valor). Como estaba diciendo, la manera de “asegurar el tiro” y garantizar que obtendremos un resultado significativo en la mayoría de las ocasiones es tener muestras grandes. En cualquier caso, está claro que hay una diferencia entre las dos poblaciones. En concreto, la diferencia es de 55-50=5 unidades (en este caso, 5 cabellos). Las pruebas estadísticas, con suficiente muestra, pueden detectar esta diferencia, como acabamos de comprobar. Ahora bien, ¿es una diferencia grande o pequeña? Lo sabremos al examinar la figura. Como podéis ver, hay un alto grado de solapamiento entre las dos poblaciones:
Repetid ahora la simulación, cambiando sólo los valores de partida. Vamos a imaginar que la diferencia entre las poblaciones es más grande, por ejemplo, 70-50=20 cabellos nuevos. Sería un crecepelo mucho mejor que el del caso anterior. O podéis probar lo contrario, una diferencia más pequeña, como 51-50=1 cabello de diferencia. La conclusión evidente es que la diferencia de medias afecta al grado de solapamiento entre las distribuciones. Cuanto más parecidas son las medias, más cercanas las distribuciones y mayor solapamiento entre ellas:
Dijimos el otro día que una de las maneras de luchar contra el error de muestreo es tener medidas precisas. Una medida precisa es aquella que, entre otras propiedades, va a producir valores similares si medimos el mismo objeto varias veces. La manera de introducir este factor en nuestra simulación es cambiar el parámetro de desviación típica (“sd”). Cuando la desviación típica es pequeña, la distribución “adelgaza”, y ocupa menos espacio, porque casi todos sus valores se aglutinan muy cerca de la media. Cuando la desviación típica es grande, por el contrario, los valores están más dispersos. Probad con valores grandes o pequeños para el parámetro “sd” de las simulaciones, y ved cómo esto también afecta al solapamiento de las distribuciones:
En esta última imagen, por ejemplo, tenemos exactamente la misma diferencia de medias (60-50=10 cabellos), pero la desviación típica de las distribuciones hace que varíe el grado de solapamiento.
¿Y qué importa el grado de solapamiento entre las poblaciones? Bueno, pues es una manera de “imaginar visualmente” el tamaño del efecto: las distribuciones muy solapadas están indicando un tamaño del efecto más pequeño. Intuitivamente, esto puede entenderse como que las dos poblaciones cuyas diferencias quiero investigar son, en esencia, muy similares.
Una medida estándar: la d de Cohen
Hasta ahora, cuando hablamos de diferencias de medias, las estamos expresando en términos brutos, en las unidades de medida (por ejemplo, número de cabellos nuevos). Esto puede a veces no ser lo más conveniente. ¿Y si quiero establecer algún tipo de comparación entre estudios que utilizan medidas diferentes? Por ejemplo, un estudio puede medir el éxito de una dieta en términos de peso perdido, y otro en términos de reducción de volumen de cintura. Lógicamente cada uno va a expresar la diferencia de medias en sus propias unidades, lo que me impide compararlas directamente. Regla básica en razonamiento estadístico: no se pueden comparar cosas que no son comparables. ¿Tiene sentido decir que 5 kilogramos es mayor que tres centímetros? ¿A que no?
Por suerte, en estadística tenemos nuestros “truquillos” para permitir estas comparaciones, y generalmente consisten en alguna forma de estandarización (la diferencia entre dos valores de tendencia central se divide por su dispersión). Así, cuando hablamos de tamaño del efecto, en vez de hablar de diferencias brutas en las unidades de medida (número de cabellos nuevos, número de kilos perdidos, centímetros de reducción de cintura…), habitualmente usamos una medida estandarizada. En este caso, la más famosa sería la d de Cohen, que se calcula así:
En realidad, hay que andarse con ojo porque hay varias fórmulas ligeramente distintas para hacer este cálculo, pero esta sería la más sencilla. Si la aplicamos a cualquiera de nuestros ejemplos anteriores, podemos calcular la diferencia en unidades estándar entre las dos poblaciones. Por ejemplo, en el primer caso, la diferencia de medias era 55-50=5 cabellos, y dado que la desviación típica era de 10, nos dejaba una d = 0.50.
Cuando enseño estadística en clase, suelo evitar entrar de lleno con las ecuaciones y las fórmulas, optando en su lugar por las visualizaciones. Sin embargo, una vez que hemos intuido el concepto visualmente, la fórmula nos puede ser de ayuda para asentarlo. Como podéis comprobar, la d de Cohen es sensible a las propiedades que habíamos mencionado en las simulaciones: en primer lugar, la distancia entre las distribuciones es la diferencia de medias, y está en el numerador de la fórmula, de modo que a mayor diferencia de medias, mayor d. En segundo lugar, la dispersión (que hemos expresado como la desviación típica) de la distribución está en el denominador de la fórmula, lo que indica que a mayor desviación típica, menor el valor del tamaño del efecto, d. En otras palabras, d está expresando el grado de solapamiento entre las distribuciones. Esto era fácil de extraer de la fórmula, pero es todavía más sencillo entender ese paso después de haber visto las simulaciones previas.
¿Es la d de Cohen el único estadístico para el tamaño del efecto? Evidentemente no, aquí estamos usando el ejemplo más sencillo que se me ocurre, pero no siempre nos va a interesar comparar dos medias de dos grupos. A veces el tamaño del efecto se va a expresar como el grado de asociación entre dos variables numéricas (r de Pearson), o de porcentaje de varianza que predice una variable predictora (R2)… De momento nos quedamos con la d de Cohen, sabiendo que es sólo un caso.
Ahora podéis volver a las simulaciones anteriores y comprobar cómo el tamaño del efecto, medido con la d de Cohen, es efectivamente una expresión del grado de solapamiento entre las distribuciones. A más solapamiento, menor la d de Cohen. Para calcularla en cada caso, usad este código que incluye una línea con el cómputo necesario:
mean.G1 <- 55 #media en el grupo 1
mean.G2 <- 50 #media en el grupo 2
sd <- 10 #desviación típica (vamos a asumir que es idéntica en ambos grupos)
d <- (mean.G1-mean.G2)/sd #d de Cohen para la población con los parámetros indicados.
#Dibujamos las dos muestras:
plot(x=seq(1: 100),
dnorm(seq(1:100), mean.G1, sd),
type="l", xlab = "", ylab="", col="red",
main=paste("Diferencia: ", mean.G1-mean.G2, ", SD = ", sd, “, d: ”, d))
lines(x=seq(1: 100),
dnorm(seq(1:100), mean.G2, sd),
type="l", col="blue")
Para comprender mejor este tipo de conceptos, nada como simularlos
de primera mano y ver cómo cambian dinámicamente. En este sentido, os puede
ayudar esta app online que es una maravilla: https://rpsychologist.com/d3/cohend/
Un aspecto en el que conviene fijarse al jugar con estas visualizaciones: incluso cuando el efecto poblacional es real, y podría ser significativo en un estudio, siempre hay un grado relativamente grande de solapamiento entre las distribuciones. Si, por ejemplo, usáis la app online para examinar un efecto con tamaño d=0.10, veréis que las dos poblaciones van a ser casi idénticas.
Hasta ahora, estamos hablando del tamaño del efecto en la población, pero recordad que generalmente los parámetros de la población son desconocidos (salvo en este caso, porque los estamos simulando). En su lugar, lo que tenemos son estadísticos calculados a partir de la muestra que sirven para estimar estos parámetros, y que están como siempre sujetos al error de muestreo. Esto quiere decir que, si hacemos un estudio, podemos calcular el tamaño del efecto muestral con la d de Cohen usando la misma fórmula que tenéis arriba. En este caso sería el tamaño del efecto “observado”, que es el que generalmente nos cuentan en los artículos. Lo que ocurre es que, como pasa con todos los estadísticos obtenidos a partir de una muestra, si repetimos el estudio el resultado va a ser diferente. Lo mismo que las medias, las desviaciones típicas y los p-valores. Otro día volveremos sobre este punto.
Efectos grandes, efectos pequeños
¿Cuál es la ventaja de tener un estadístico estandarizado como la d de Cohen? En primer lugar, como decía antes, nos permite comparar entre estudios con medidas diferentes. Así, si un estudio mide el éxito de la dieta en términos de kilos perdidos y me da una d = 0.3, y otro estudio lo mide en términos de centímetros de cintura, y me da una d = 0.10, ya puedo afirmar que, en principio, parece que el primer estudio indica un efecto más grande que el segundo, independientemente de las unidades de medida.
La otra ventaja de las medidas estandarizadas es que nos permiten elaborar guías o pautas para saber cuándo un efecto es “grande”. Bueno, aunque esto requiere mucha cautela y nunca debe tomarse al pie de la letra. Orientativamente, en psicología decimos que un efecto es “pequeño” si d = 0.20, “mediano” si d = 0.50, y “grande” si d = 0.80. En ocasiones vais a ver papers y artículos donde indican tamaños del efecto inmensos, como d = 3.20, ó d = 5.79. Por lo general, recomiendo cautela al interpretarlos, ya que un efecto tan gigantesco estará seguramente sobrestimado. Pensad que la diferencia de estatura entre hombres y mujeres, que es uno de los efectos más grandes que podemos observar, tiene una d de “sólo” 1.20. Cuesta pensar que un efecto psicológico, que generalmente son mucho más sutiles, pueda tener un tamaño dos o tres veces mayor.
Por aquí lo vamos a dejar de momento, aunque queda un paso esencial, que es el de unir los conceptos de tamaño del efecto y de potencia (que vimos en el anterior post), ya que en realidad están íntimamente ligados. Esto lo dejamos para el próximo día. Seguid con vuestros chapuzones veraniegos mientras tanto.
Tras un descanso en el blog, aprovecho las vacaciones y retomo esta serie sobre estadística visual donde la dejamos, para progresar y entender un concepto sumamente importante en el diseño de estudios: la potencia estadística. Vamos a aprender por qué es importante reclutar muestras grandes para tus estudios, y qué ocurre cuando no cumplimos ese objetivo. Como siempre, echaré mano de simulaciones en R y de visualizaciones. ¡Al lío!
Recordemos que, al diseñar un estudio o experimento en psicología, generalmente obtenemos un estadístico que llamamos “p” o “p–valor”, y que toma valores entre 0 y 1. El p-valor nos va a decir la probabilidad de obtener unos datos como los que hemos conseguido (o más extremos) bajo la hipótesis nula. En otras palabras, es una cuantificación de “cómo de sorprendente” sería obtener nuestros datos por azar. Generalmente, usamos un umbral para interpretar el p-valor: si el p-valor es menor de 0.05, decimos que el resultado es significativo, pues los datos son muy “sorprendentes” (improbables bajo la hipótesis nula).
Ahora bien, hay ciertas intuiciones sobre los p-valores que están muy asentadas (como se ve en la imagen), pero que son incorrectas.
En el post anterior, comprobamos que el umbral del p-valor sirve para mantener a raya el error tipo I, o la tasa de “falso positivo”. ¿Cómo lo consigue? Vamos a simular en R unos cuantos experimentos al azar. En cada “experimento”, generamos dos muestras aleatorias de participantes, y las compararemos entre sí obteniendo un p-valor. Recordad que, si no tenéis R a mano, podéis copiapegar el código y jugar con él en esta web sin instalar nada: https://rextester.com/l/r_online_compiler
grupo1.n <- 10 #esto es el tamaño muestral de cada grupo
grupo2.n <- 10
grupo1.mean <- 50 #las medias de las poblaciones son idénticas (luego no hay diferencias)
grupo2.mean <- 50
grupo1.sd <- 10 #desviación típica de cada población.
grupo2.sd <- 10
numMuestras <- 10000
pvalue <-c()
for(i in 1:numMuestras){
grupo1.sample <- rnorm(grupo1.n, grupo1.mean, grupo1.sd)
grupo2.sample <- rnorm(grupo2.n, grupo2.mean, grupo2.sd)
pvalue <- c(pvalue, t.test(grupo1.sample, grupo2.sample)$p.value)
}
hist(pvalue) #esta línea produce un gráfico con la distribución de los valores.
En esta simulación, el efecto real que estamos buscando es cero (porque las dos medias poblacionales son idénticas, tienen el mismo valor, 50), es decir, la hipótesis nula es cierta. Sin embargo, cuando examinamos el gráfico con la distribución de los p-valores de los 10000 experimentos, vemos que, a pesar de lo que indica la intuición de los tuiteros de la encuesta que os cité arriba), todos los valores posibles son equiprobables, lo mismo los grandes que los pequeños. Y también vemos que es perfectamente posible encontrar por puro azar resultados significativos (están marcados en amarillo/naranja):
Al contrario de lo que tal vez imaginabas, cualquier valor de p es igual de probable cuando el efecto real es cero (las poblaciones no difieren).
Esto nos ayuda a entender por qué el umbral de significación se ha fijado en 0.05. Daos cuenta de que, en esta figura, el 5% de los p-valores está por debajo de 0.05, dado que la distribución es uniforme: o sea, hay una probabilidad del 0.05, o 5%, de tener un p-valor igual o menor de 0.05, una probabilidad de 0.10, o 10%, de tener un p-valor igual o menor a 0.10, y así sucesivamente. El error tipo I, o “falso positivo”, implica que, aunque el efecto es realmente inexistente, por puro azar encontramos datos que parecen apoyarlo. Si queremos cometer este error no más de un 5% de las veces (es decir, con una probabilidad de 0.05), entonces tiene todo el sentido del mundo que pongamos justo ahí el umbral de significación: sólo afirmaremos que el resultado es significativo cuando p < 0,05, lo que solo ocurre por puro azar el 5% de las veces. Por otro lado, esto también implica que hay que ser cautelosos al interpretar los resultados de un estudio aislado, porque meramente por azar vamos a tener resultados significativos ¡como mínimo el 5% de las veces!
Hasta aquí habíamos llegado en el post anterior, aunque convenía repasar para tenerlo fresco antes de seguir. ¡Continuemos!
Cuando el efecto sí está ahí.
Ahora vamos a imaginar una situación distinta. Estamos probando un tratamiento para la depresión, y para ver si funciona realizamos un estudio conde comparamos la puntuación de depresión de un grupo tratado con la de un grupo control que no ha recibido ningún tratamiento. Aprovecho para señalar que este tipo de grupo de control es nefasto, porque los pacientes no tratados pueden experimentar un deterioro (producido en parte por el efecto nocebo), haciéndonos creer que el tratamiento sí funciona incluso cuando no sea así. Por eso siempre es mejor tener un control que reciba algún tipo de tratamiento (un placebo, o la terapia de referencia…). En cualquier caso, para el ejemplo nos da lo mismo, pues el diseño del estudio es sencillo: vamos a comparar dos grupos, y esperamos que la puntuación del grupo tratado sea menor que la del control. Es decir, estamos imaginando que sí hay un efecto, y queremos detectarlo.
Como en el caso anterior, simularemos 10000 estudios como el que he descrito, y obtendremos para cada uno un p-valor para poder examinar su distribución. El código es idéntico al de antes, solo que ahora fijaremos medias diferentes para las poblaciones que van a generar todos estos estudios. A modo de ejemplo, he usado los valores de media poblacional 50 y 53, lo que produce un tamaño del efecto poblacional de 3 puntos (53-50=3). Cambiad la siguiente línea en el código, y ejecutadlo igual que antes:
grupo1.mean <- 53 #las medias de los dos grupos son diferentes.
grupo2.mean <- 50
Si todo ha ido bien, la forma de la distribución habrá cambiado totalmente: ahora ya no es uniforme, sino exponencial. Los valores pequeños son más probables que los grandes, lo que crea esa asimetría que podéis observar.
Ahora la cosa cambia: los p-valores pequeños aparecen con más probabilidad que los grandes.
La sección del gráfico que está en color amarillo/naranja corresponde a los p-valores significativos (por debajo de 0.05), igual que antes. Pero dado que ahora sabemos que sí que existe un efecto (es decir, las diferencias que encuentran estos 10000 experimentos no se deben únicamente al azar), hay que interpretarlos de otra manera. Ahora la parte resaltada de la distribución no representa resultados que han salido significativos por azar, sino estudios que han tenido éxito al capturar un efecto que sí existe: sabemos que hay diferencias entre las dos poblaciones, y esos son los estudios que han producido una p < 0.05 (significativo).
A esta porción resaltada la vamos a llamar “potencia estadística”: representa la probabilidad de que mi estudio vaya a capturar (obtener p < 0.05) un efecto que sí existe. En este caso, estábamos buscando un efecto relativamente pequeño (recordad, las medias poblacionales eran 50 y 53, una diferencia pequeña de sólo 3 puntos), así que no es de extrañar que la potencia obtenida haya sido un poco decepcionante: fijaos en que sólo un 10% de los resultados han sido significativos (os lo indico en la figura, arriba, donde dice “positive-rate” o “tasa de positivos”: 0.096, aproximadamente 10%). Es decir, que si realizo docenas, o cientos de experimentos como éste, incluso habiendo una diferencia real entre el tratamiento y el control… ¡sólo la voy a encontrar con éxito el 10% de las veces! Un despropósito.
Por suerte, podemos hacer algo para mejorar la potencia. En principio lo ideal sería usar mediciones más precisas, más exactas, lo que va a reducir el dichoso error de muestreo y a reducir las discrepancias entre estudios. Pero si no fuera posible (en psicología es generalmente una pesadilla desarrollar medidas precisas), recordad que hay otra forma de reducir este error de muestreo, que ya vimos en otros posts: aumentar la muestra.
Un consejo: no os creáis nada si no lo ven vuestros propios ojos. ¡Así que simuladlo! Coged el código del ejemplo anterior, y cambiad el tamaño muestral de los estudios, que yo había fijado en 10 por grupo. Subidlo a, por ejemplo, 50, y observad la distribución:
grupo1.n <- 50 #esto es el tamaño muestral de cada grupo
grupo2.n <- 50
¿A que va cambiando la cosa? Efectivamente, al aumentar el tamaño muestral, estamos conteniendo un poco el error de muestreo, y con ello aumentando nuestra potencia. Esto causa que una proporción mayor de estudios sean significativos (p < 0.05). Aquí os pongo algunos ejemplos para que lo visualicéis mejor:
Tres simulaciones con el mismo efecto, pero distinta potencia (tamaño muestral).
En estos tres ejemplos, lo único que está variando es la N, o tamaño muestral: en la fila de arriba, los grupos tienen 10 participantes, en la fila de en medio, 100, y en la de abajo, 200 participantes. Lo interesante es fijarse en cómo va aumentando la tasa de positivos, o potencia, al aumentar la muestra: hemos subido de un mísero y decepcionante 0.096 (aproximadamente 10% de los resultados son p < 0.05), a un más prometedor 0.85 (el 85% de los resultados son p < 0.05). En la fila de en medio, con una N de 100 participantes por grupo, la mitad de los estudios que hemos simulado producen el resultado esperado, y la otra mitad fallan. Es como lanzar una moneda al aire. Si repites el estudio, idéntico en todos los sentidos, podrías obtener un resultado diferente. Desde luego, esto no es lo que uno tenía en mente cuando decía que estaba haciendo ciencia.
Hay que tener en cuenta un detalle que no he mencionado: la potencia o “tasa de éxito” de los estudios también va a depender del tamaño del efecto real (es decir, de la magnitud de la diferencia entre las dos medias poblacionales, en este caso). Con una muestra de 100 participantes puede que tenga baja potencia para detectar una diferencia de 3 puntos (pequeña), pero podría ser una potencia aceptable para detectar efectos más grandes, de 20 puntos por ejemplo. Como siempre, probad a cambiar los números en la simulación (en este caso, dejando fija la N y cambiando las diferencias entre las medias) para aseguraros de que entendéis lo que está pasando.
La
utilidad del concepto de potencia
¿Y para qué queremos saber esto? Bien, creo que una de las cosas que más me ha perjudicado en mi formación estadística es precisamente que no me hablasen de esto mucho antes, desde el principio. Sí, antes de meternos a prender ANOVAs y análisis complicados. Mirar y entender estas distribuciones que os he enseñado arriba es un antídoto contra el autoengaño: es relativamente fácil obtener un p-valor significativo por azar (como vimos en las primeras simulaciones), y es todavía más fácil hacer un estudio y que NO salga significativo por falta de potencia (mirad, si no, la segunda fila del gráfico anterior: el 50% de los estudios van a fallar). Por otro lado, ahora que sabemos cómo se comportan los p-valores en uno y otro caso, podemos planificar con la potencia en mente. Básicamente, la enseñanza que hay que extraer de todo esto es que, si no queremos estrellarnos una y otra vez con un resultado no significativo, necesitamos muestras grandes. Mucho más grandes de lo que solía ser habitual hace unos años en psicología.
Y ya que estamos con el tema, ¿cuál es la potencia habitual en psicología? ¿Estamos como en la primera fila del gráfico, o como en la de abajo? Pues bien, se han hecho unas cuantas estimaciones examinando los estudios publicados (ojo, esto supone un sesgo: no sabemos cuál podría ser la potencia de los estudios que no se han publicado), con resultados un tanto mezclados. Es cierto que hay grandes diferencias en función del área: en estudios sobre personalidad trabajan con muestras grandes, mientras que en ámbitos neuropsicológicos (debido a que estudian muestras de pacientes difíciles de conseguir, o bien usan técnicas de medición muy caras) ocurre lo contrario, y las muestras tienden a ser demasiado pequeñas. Para que os hagáis una idea, una estimación de la potencia en ámbitos de psicología clínica (Rossi, 1990) nos dice que, para detectar un efecto de tamaño pequeño o medio, los estudios publicados tienen una potencia de 0.17 y 0.57, respectivamente. O sea, que cuando las diferencias reales son pequeñas, hay campos de la psicología donde los estudios se diseñan de tal forma que entre un 17% y un 57% logran capturar el resultado, lo cual es desastroso. No podéis verme, pero mientras escribo estas líneas estoy haciendo facepalm muy fuerte.
Y otra enseñanza que habremos adquirido al entender el concepto de potencia es que hay que desconfiar cuando los resultados de un artículo son, digamos, demasiado bonitos…
Imaginad un artículo donde intentan demostrar el efecto negativo de los videojuegos sobre la concentración. Es uno de esos artículos donde se describen múltiples experimentos, pongamos por ejemplo, siete. Cada uno de ellos utiliza una manipulación ligeramente diferente, o tiene una medición o tipo de muestra algo distinta, y con ello pretenden ofrecer evidencia robusta de que el fenómeno existe en un rango de posibles situaciones. Hasta aquí bien. ¿Cuál es el problema? Que los siete experimentos aportan un resultado significativo. No cuatro, ni seis, no: los siete.
¿Y qué?, me diréis. Al fin y al cabo esto debería interpretarse como que el resultado es robusto y replicable: ¡se ha replicado nada menos que siete veces! ¿Por qué debería levantar mi ceja y sospechar? Pues porque es un resultado demasiado bonito para ser verdad. La clave está en que la potencia de cada estudio individual no es perfecta (no llega al 100%). Es decir, como hemos visto, siempre hay cierta probabilidad de que, incluso aunque el efecto esté ahí, el estudio no sea capaz de detectarlo y no produzca un resultado significativo. Ahora pensad en cómo esto afecta a la probabilidad de obtener una secuencia de experimentos con resultados perfectos.
Para hacerlo más fácil, pensadlo de la siguiente manera. Imaginemos que los siete estudios están realizados con una potencia media: 0.50. Es decir, asumiendo que el efecto es real y lo podemos ver, el 50% de los experimentos van a producir una p < 0.05. Es como lanzar una moneda al aire. Pero es que el artículo no está contando un experimento aislado, ¡sino una serie de siete! O sea: has lanzado la moneda siete veces, y las siete te ha salido cara, que es justo lo que predecías. ¿Sospechoso?
¡Podemos calcular exactamente cómo de sospechoso es el resultado! Si recordáis las clases de matemáticas del bachillerato, la probabilidad de obtener una secuencia de sucesos en experimentos independientes se calcula como la probabilidad conjunta de todos ellos. En este caso, sería así:
0.50 x 0.50 x 0.50 x 0.50 x 0.50 x 0.50 x 0.50 = 0.0078.
Traduciendo a porcentaje: si intento replicar la cadena de siete experimentos en idénticas circunstancias, sólo lo conseguiré el 0.78% de las veces. Menos del 1%. Es muy improbable. Tan improbable como obtener con una moneda siete caras seguidas de siete lanzamientos.
La cosa se pone todavía peor si recordamos que, en realidad, la potencia media en los estudios de psicología puede ser bastante menor de 50%. Imaginemos que es por ejemplo del 30%. La probabilidad de obtener siete resultados significativos sería de 0.00022, o sea, del 0.02%.
¿Cómo interpretar entonces esos artículos preciosos, fantásticos, que nos dan tanta envidia, en los que todo sale significativo y están repletos de asteriscos? En dos palabras: publicación selectiva. Quizá los autores realizaron no siete, sino veinte o treinta experimentos como los que describen, pero luego seleccionaron aquellos que salieron significativos para contarlos en el artículo, callándose el resto. De hecho, esto parece ser que ocurre de manera muy habitual en ciertos ámbitos y sobre todo en algunas revistas, como la prestigiosa Science (Francis et al., 2014). Cuando uno lee la literatura científica, urge mantener una mentalidad escéptica.
Con esta reflexión lo dejamos por hoy. Otro día seguimos, ¡prometido! Buen verano.