
Después de unos cuantos años dando clase de Aprendizaje en la uni, ya estoy acostumbrado a una queja habitual en el primer curso del grado, cuando llegamos a esa parte del temario donde se habla de teorías del condicionamiento, y aparecen esos temidos modelos matemáticos:
“¿Por qué tengo que estudiar estas ecuaciones que aparecen en el manual? ¿No se suponía que esto es Psicología, y no matemáticas? Ni siquiera estamos en la asignatura de estadística”.
Como yo también fui estudiante, empatizo con este resquemor que aparece todos los años al estudiar teorías como la de Rescorla-Wagner o Pearce y Hall. Sin embargo, creo que esta sensación negativa no le hace justicia al contenido que se está transmitiendo, y que es cuestión de dedicar un poco más de tiempo a comprender los entresijos de estos modelos. En el post de hoy, voy a intentar complementar un poco ese apartado, y veréis cómo no es tan difícil. Para los más atrevidos/as, incluiré el código para simular el modelo de Rescorla-Wagner en R. ¿Empezamos?
Los modelos matemáticos
En general, hay dos grandes tipos de teorías en psicología: aquellas que se expresan sólo verbalmente (por ejemplo, las formulaciones tradicionales de las teorías de la comparación social, o las de la disonancia cognitiva), y aquellas otras que permiten cierto grado de formalización, es decir, que se pueden expresar en el lenguaje de las matemáticas.
Diseñar una teoría que sea formalizable tiene muchas ventajas. La más evidente es que nos va a permitir hacer predicciones cuantitativas, en forma de números. Por ejemplo, en vez de predecir que “este individuo aprenderá más que este otro”, podría ser más preciso apuntar que “este individuo aprenderá tres veces más que el otro”. (Dicho esto, mi yo más cínico está convencido de que hacer predicciones numéricas es prácticamente inútil en la mayoría de las aplicaciones en psicología, donde la flexibilidad del modelador es casi absoluta y la precisión de las medidas, de risa.)
En este post vamos a hablar del modelo de Rescorla-Wagner (Rescorla y Wagner, 1972), uno de estos “modelos formales” que describe, mediante un algoritmo sencillo, el proceso de aprendizaje por condicionamiento. Se trata probablemente del modelo de aprendizaje más famoso, que se ha aplicado a infinidad de ámbitos y que lidera toda una familia de modelos con características similares llamada “modelos asociativos” (Pearce & Bouton, 2001).
La historia del modelo de Rescorla-Wagner
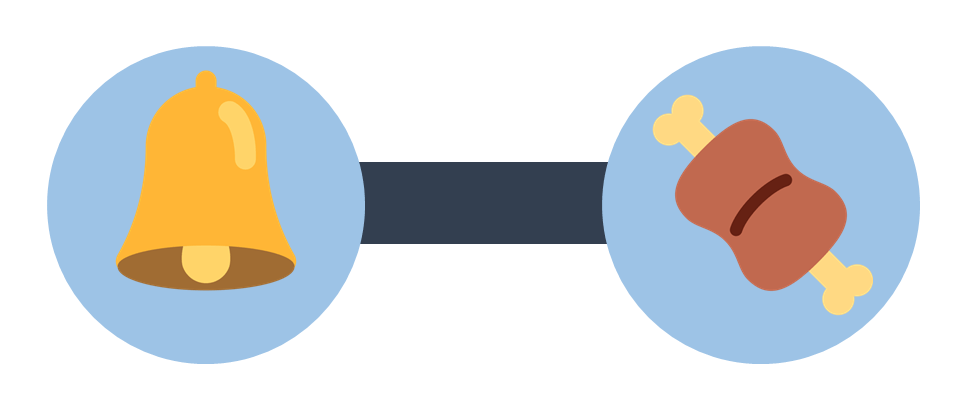
No voy a entrar en detalles históricos porque no quiero que sean el foco del post, pero creo que es interesante comprender qué hueco o necesidad “rellena” este famoso modelo. Bien, imaginad una situación de aprendizaje como la del perro de Pavlov, que ya conocéis pero que os resumo ahora:
El perro escucha un estímulo inicialmente neutro, el sonido de una campana (en el experimento original, era un diapasón). Este sonido no provoca ninguna respuesta en especial, dado que en principio carece de relevancia biológica. Por el contrario, la presentación de un plato de comida sí que produce una respuesta en el perro hambriento, en forma de salivación abundante. Diríamos que la comida es un estímulo incondicionado (EI) que produce una respuesta incondicional (RI).
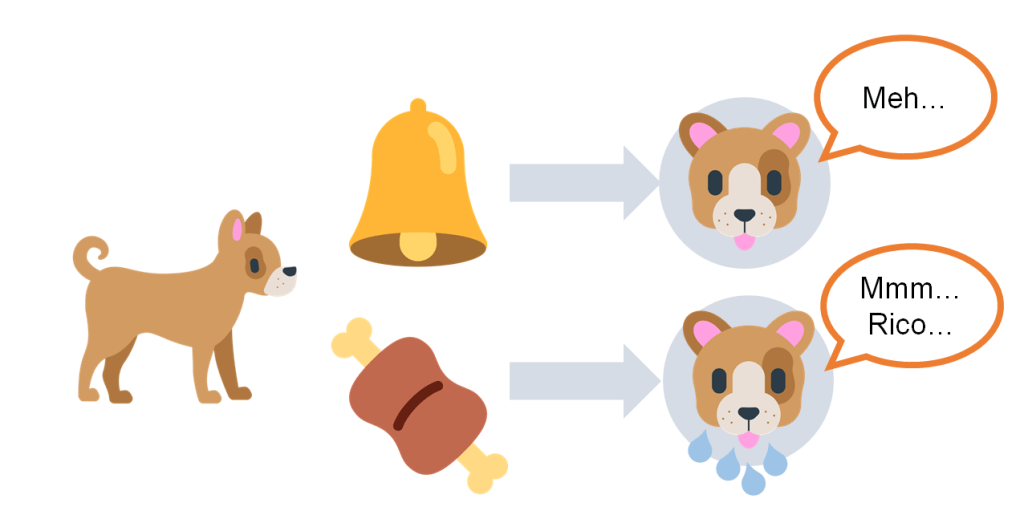
Por medio del procedimiento de condicionamiento clásico, vamos a emparejar repetidamente el sonido de la campana con la presentación de la comida. La idea es que el perro vaya aprendiendo que tras oír la campana va a poder alimentarse. Si de vez en cuando hacemos una prueba y reproducimos el sonido de la campana sin ir seguido de la comida, comprobaremos cómo ahora este sonido, inicialmente neutro, es capaz de provocar en cierto grado la respuesta de salivación. Es la prueba de que el animal ha aprendido la asociación entre los dos estímulos, y de que el sonido de la campana es ahora un estímulo condicionado (EC).
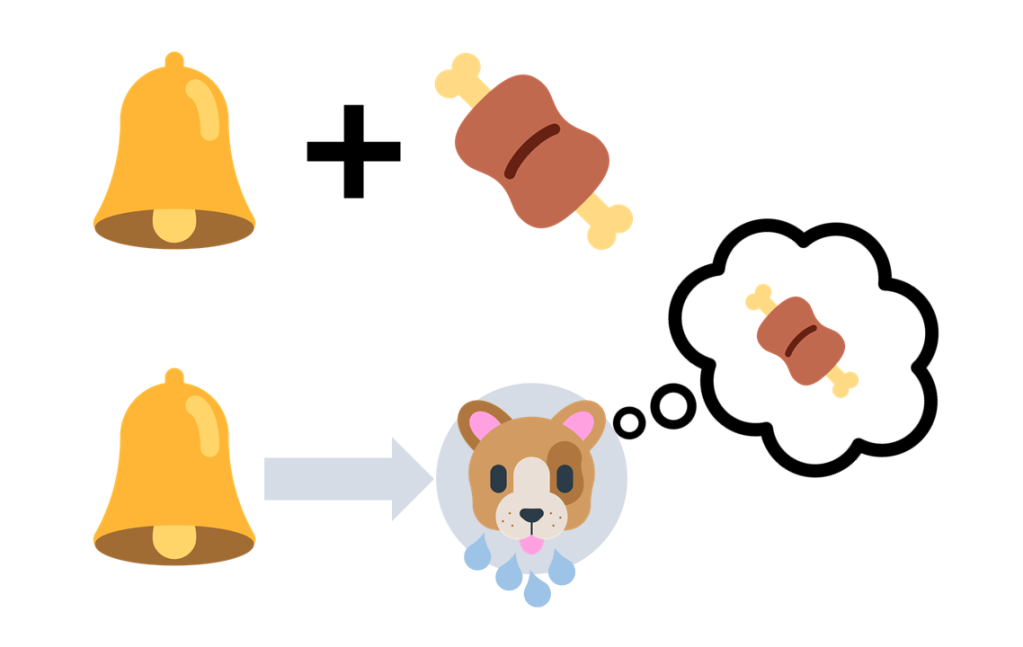
Este proceso se conoce como adquisición. Una vez ahí, podríamos extinguir el aprendizaje previo. Para ello, presentaríamos la campana (EC) sin ir seguida de la comida (EI), y paulatinamente veríamos cómo la respuesta de salivación iría desapareciendo. Este segundo procedimiento, la extinción, es muy relevante para muchos tipos de terapia.
Muy bien, pues ya hemos descrito dos fenómenos básicos en el aprendizaje: adquisición y extinción. Ahora, ¿cuál es el mecanismo que los hace funcionar? Inicialmente, podríamos pensar que basta con la mera contigüidad entre los estímulos. El perro aprende a “conectar” el sonido y la comida porque estos se presentan juntos en el tiempo, repetidamente. ¿Os sirve como explicación?
Pues va a ser que no. Aunque en los procedimientos descritos no lo podemos ver, hay otros que nos dan a entender claramente que la contigüidad es insuficiente. En concreto, vamos a hablar de Bloqueo:
Un diseño de Bloqueo (Kamin, 1968) tiene dos fases, y dos estímulos condicionados diferentes (por ejemplo, el sonido de la campana, A y una luz, B). En la primera fase, el estímulo A (el sonido,) se empareja con la comida como en el caso de la asociación: A –> EI. Al final de la Fase 1, el perro será capaz de anticipar la comida al oír la campana.
En la Fase 2, continuamos con este entrenamiento, pero le añadimos el otro estímulo, B (la luz): A+B –> EI. Si ahora hacemos una prueba y le ponemos al perro la luz (B) en solitario, el resultado habitual es que el animal no va mostrar mucha respuesta. ¿Por qué (aparentemente) no está aprendiendo sobre la luz?
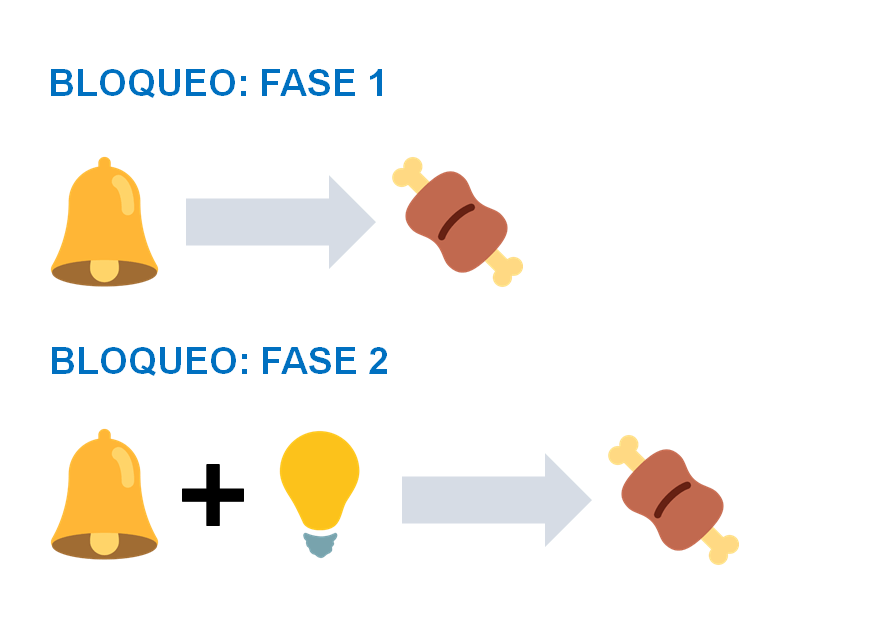
No puede ser un problema de contigüidad: la luz va seguida de la comida en repetidas ocasiones. Tiene que haber algo más. La respuesta está en la contingencia: aunque A y B son contiguos con la comida, A es más contingente con la comida que B. Y es que nunca hemos presentado la comida sin que esté presente A, pero en toda la primera fase hemos presentado la comida sin que esté B.
Entonces, ya tenemos un posible candidato a mecanismo de aprendizaje: los animales aprendemos las contingencias que se nos presentan, dejando la contigüidad en un segundo plano. ¿Cómo formalizar (es decir, expresar matemáticamente) esta intuición, para diseñar una teoría que lo refleje?
Eran principios de los 70 del siglo pasado, y la idea estaba ya presente en un campo recién inaugurado, el de la inteligencia artificial. Sí, aunque nunca se les da crédito en los manuales sobre aprendizaje (creo que yo no lo he visto en ninguno), Widrow y Hoff (1969) habían descrito la llamada “regla delta“, un algoritmo iterativo de optimización de funciones basado en la corrección progresiva de un error de predicción mediante el máximo gradiente (¡uf! qué lío), y que luego se volvería omnipresente para entrenar redes neuronales artificiales del estilo del Perceptrón. Los psicólogos Rescorla y Wagner hicieron suya la idea intuitiva tras esta regla, para diseñar su famoso modelo sensible a la contingencia. Y yo os lo cuento a continuación.
El concepto detrás del modelo de Rescorla-Wagner
La lógica que subyace al modelo es tremendamente simple: el combustible del aprendizaje es la “sorpresa”. Cuanto más aprendemos, menos nos sorprende lo que vemos, y seguiremos aprendiendo mientras algo nos sorprenda.
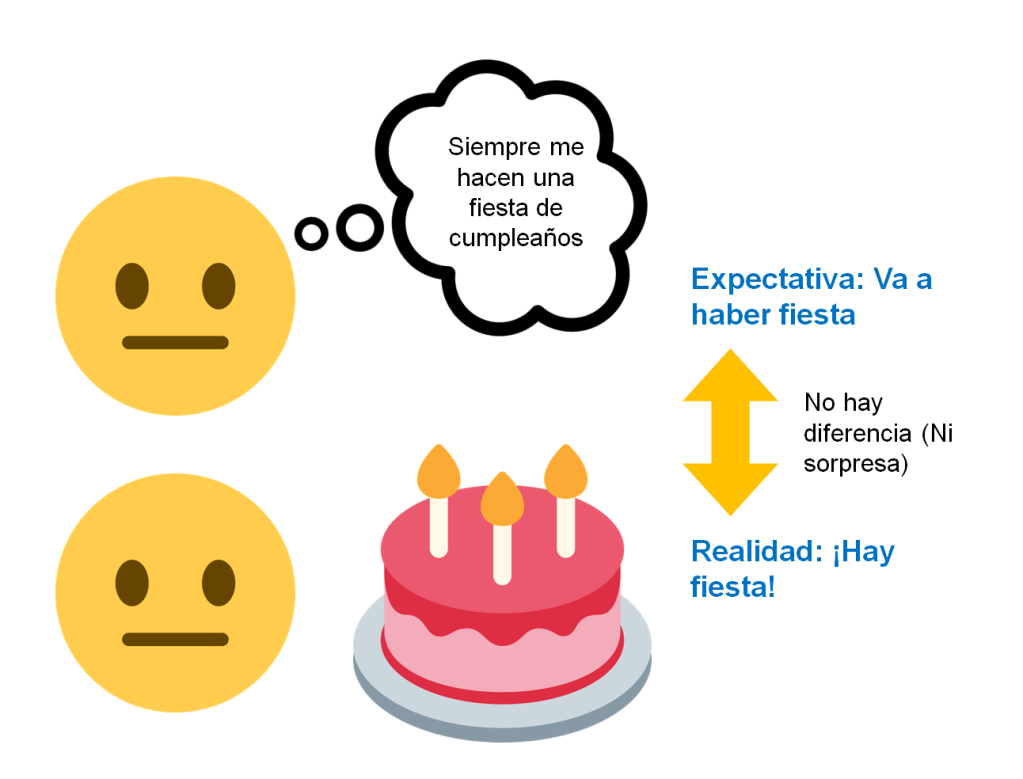
Lo vemos con un ejemplo. Vamos a definir “sorpresa” como la diferencia entre mi expectativa y la realidad. Imaginemos que es mi cumpleaños, y que no es habitual que lo celebre con los compañeros de trabajo. Por lo tanto, mi expectativa de encontrarme una fiesta es nula, o sea, tiene valor 0. Entonces llego al trabajo y descubro que, contra mi creencia previa, me tienen preparada una fiesta con pasteles y globos. Supongo que estaría muy sorprendido, ¿verdad? Lo sé porque hay una diferencia enorme entre la realidad (ha habido fiesta, por lo tanto fiesta = 1) y mi expectativa previa (mi expectativa era que no iba a haber ninguna fiesta, o sea, fiesta = 0).
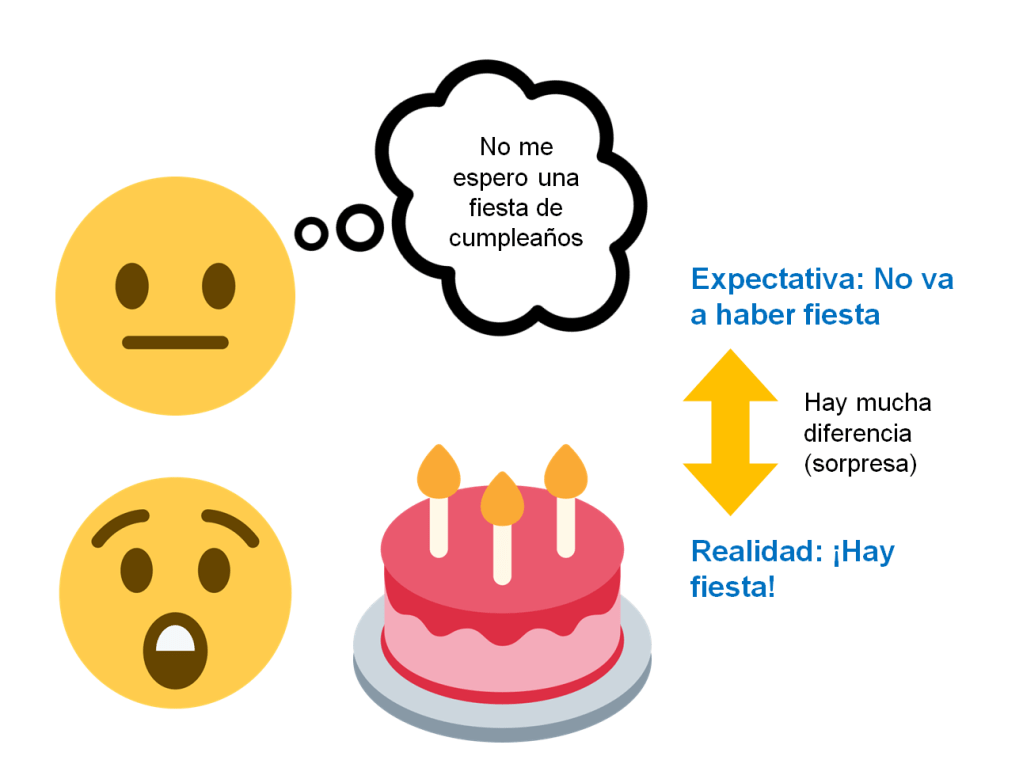
¿Qué ocurriría si, a partir de entonces, se instaura una tradición en la empresa y todos los años celebramos una fiesta por mi cumpleaños? Pues que entonces, al acercarse el día, mi expectativa de fiesta sería máxima (expectativa: fiesta = 1). Por otro lado, como efectivamente estamos haciendo la fiesta (realidad: fiesta = 1), la diferencia entre mi expectativa y la realidad es mínima (1 – 1 = 0), y por lo tanto no estoy sorprendido.
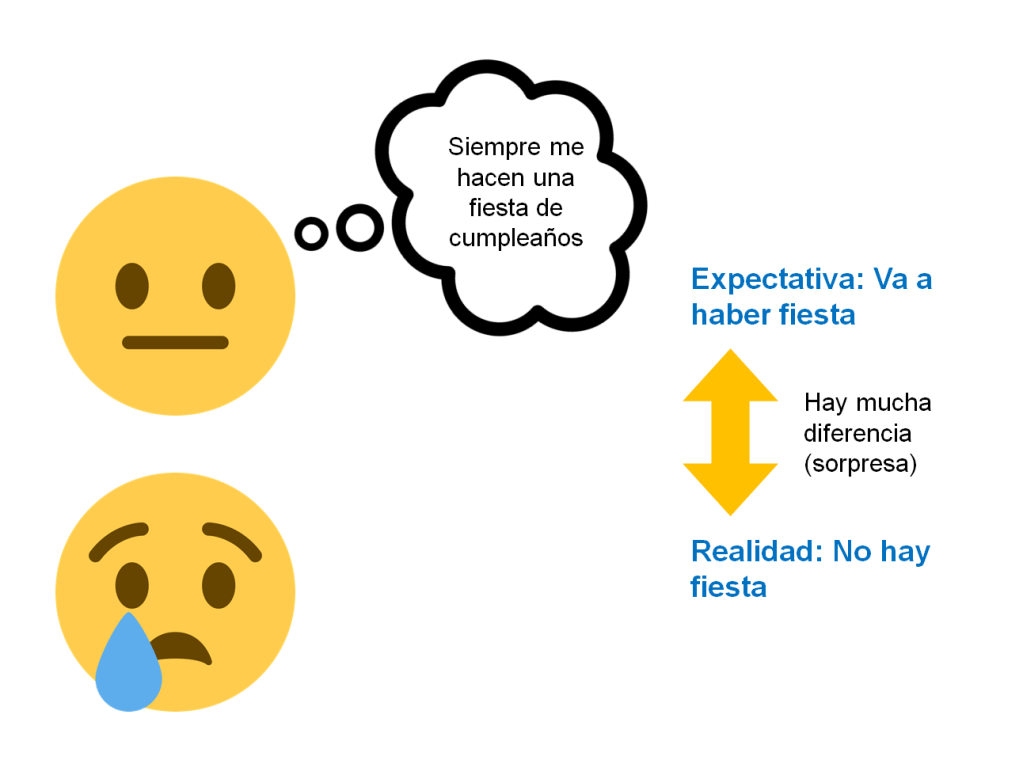
Sería posible también llevarse una sorpresa “negativa”: si, tras varios años en los que hacemos una fiesta por mi cumpleaños (expectativa: fiesta = 1), de pronto resulta que este año nadie ha organizado nada (realidad: fiesta = 0), mi expectativa de fiesta será muy diferente de la realidad, pero esta vez en negativo (0 – 1 = -1), es decir, una sorpresa desagradable, o una decepción.
De este ejemplo podemos ir sacando algunas conclusiones:
- La sorpresa es la diferencia entre mi expectativa y la realidad que me encuentro.
- Cuando un evento (que me hagan una fiesta) ocurre una y otra vez de forma regular o predecible, deja de ser tan sorprendente, porque he aprendido a predecirlo.
- Y es que aprendo en la medida en que me sorprendo. Cuando una situación es muy sorprendente, puedo aprender sobre ella. Pero cuanto más capaz soy de predecir lo que va a pasar, menos me sorprende, y menos tengo por aprender.
Ahora podemos formalizar estas intuiciones en forma de un algoritmo de aprendizaje.
El algoritmo de Rescorla-Wagner.
La mítica ecuación que tanto miedo causa en primero de psicología no hace más que concretar estas ideas de forma matemática:
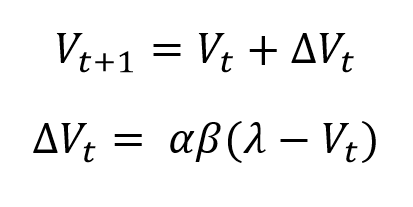
Ya puedo oler el terror en más de un estudiante de primer curso: “Madre mía, qué miedo da. Con todas esas letras griegas y sus subíndices”. Vamos a hacerlo más fácil definiendo las variables una a una.
Bien, el elemento principal en esta ecuación es V, la “fuerza asociativa”, que se traduciría como “la intensidad de mi expectativa” (*) de que va a ocurrir un evento, en este caso el EI. Si V es muy grande (cercana a 1), es que estoy casi seguro de que se va a presentar el EI.
Para entenderlo, imaginad que tenemos una representación mental de cada estímulo (el EC y el EI, o la campana y la comida). Cada representación se activa cuando se detecta el estímulo correspondiente. Cuando las dos representaciones están activas a la vez (y es justo lo que ocurre durante el entrenamiento de adquisición), se fortalece una “conexión” o asociación entre ambas, y V sería la medida de la fuerza de esa asociación.
La fuerza asociativa va a cambiar en cada ensayo, por eso le ponemos el subíndice “t” (de “tiempo”, o de “trial“, ensayo en inglés). Las ecuaciones de arriba describen la regla de actualización de V en cada ensayo. Así, en el ensayo 4, por ejemplo, la fuerza asociativa V4 será igual a la que teníamos en el ensayo anterior (V3) más una cantidad añadida, ΔV3 (**). La segunda ecuación nos explica cómo se calcula esta cantidad.
El corazón de la regla delta está en el paréntesis de la segunda ecuación: “λ – V”. Y es que esta diferencia encierra el concepto de “error de predicción” o de “sorpresa” del que hemos estado hablando. Ya sabemos que V codifica nuestra expectativa. Ahora bien, la letra griega lambda (λ) representa el estado de la realidad: ¿ha ocurrido el EI (la comida)? Entonces lambda vale 1. ¿No ha ocurrido? Entonces vale 0. Por lo tanto, ” λ – V ” es la diferencia entre la realidad y la expectativa, como en los ejemplos anteriores. Como veremos en las simulaciones, la regla de Rescorla-Wagner se alimenta de esta diferencia para ir corrigiendo el valor de V progresivamente. Cuanto mayor es la diferencia entre expectativa y realidad, más se incrementa la fuerza asociativa V en el próximo ensayo. Podéis pensar en la sorpresa como el “combustible” de Rescorla-Wagner: mientras haya combustible, siempre vas a seguir aprendiendo hasta agotarlo, es decir, hasta igualar V y lambda.
Ya solo nos quedan dos parámetros por mencionar, alfa y beta (α y β), que a veces, por simplificar, se unifican en un sólo parámetro (k). Son los parámetros que fijan la velocidad del aprendizaje, así que no hay mucho que decir al respecto.
Simulaciones: Adquisición y Extinción
¡Ya estamos preparados/as para ver el modelo en acción! He preparado esta pequeña función en R que podéis emplear para hacer pruebas por vuestra cuenta. Si no os apetece meteros con R, ignorad los trocitos de código, que el post se va a entender igualmente.
RW <- function() {
VA <- c(rep(0, length(CueA)+1))
VB <- c(rep(0, length(CueA)+1))
for(i in 1:length(CueA)){
VA[i+1] <- VA[i]+CueA[i]*((alphaA*beta)*(Lambda[i]-(VA[i]+VB[i])))
VB[i+1] <- VB[i]+CueB[i]*((alphaB*beta)*(Lambda[i]-(VA[i]+VB[i])))
}
return(cbind(VA, VB))
}
Vamos a comenzar simulando el proceso de adquisición y extinción que describimos antes: haremos diez ensayos en los que el EC irá seguido del EI (sonido –> comida), y otros diez ensayos de extinción en los que el EC no irá seguido del EI. Usaremos como parámetros de velocidad de aprendizaje dos valores altos (α = 0.8, β = 0.8). El resultado lo tenéis aquí:
CueA <- rep(1, 20) #Secuencia de valores del EC (1 si está presente, 0 si no)
CueB <- rep(0, 10)
Lambda <- c(rep(1, 10), rep(0, 10)) #10 ensayos de aquisición, 10 de extinción
V <- rep(0, 20+1)
alphaA <- 0.8 #Parámetros de velocidad de aprendizaje
alphaB <- 0.1
beta <- 0.8
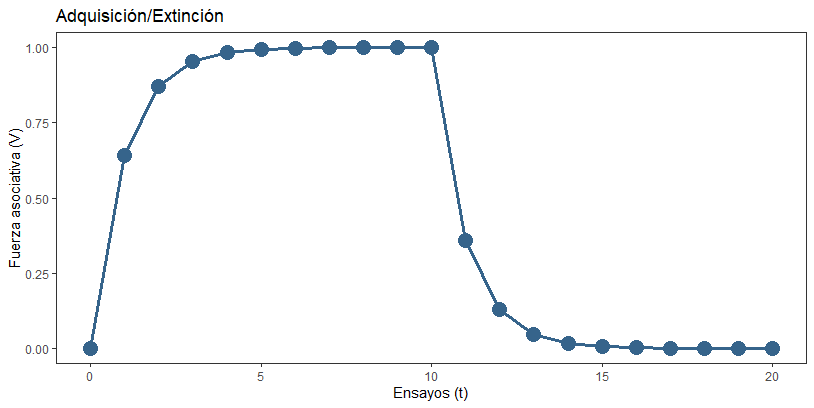
Vamos a examinar la figura. Lo que vemos aquí es una curva de aprendizaje, una descripción de cómo va cambiando la fuerza asociativa a lo largo de los ensayos. En los primeros 10 ensayos, habíamos presentado el EC y el EI conjuntamente. En nuestro ejemplo, esto serían 10 años celebrando la fiesta de cumpleaños en el trabajo.
Al principio (t=0), mi expectativa de que me iban a hacer una fiesta de cumpleaños era nula (V0 = 0). Por eso, mi sorpresa en el primer año es mayúscula: 1 – 0 = 1. ¿Cuánto debería cambiar mi expectativa para el año que viene? Usemos la ecuación:

Ahora se entiende bien cómo funcionan los parámetros de velocidad de aprendizaje: aunque la sorpresa era máxima (1), no incrementamos la fuerza asociativa en toda esa magnitud, sino que depende de alfa y beta.
¿Y qué pasaría el segundo año? De nuevo, yo tenía una determinada expectativa de fiesta de cumpleaños, y me encuentro con que efectivamente hay fiesta (lambda = 1). ¿Cómo cambia mi expectativa para el tercer año? Vamos a las ecuaciones:
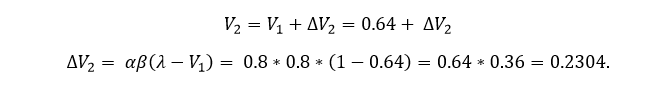
Es decir, tengo que incrementar mi expectativa en 0.23 puntos, por lo que mi expectativa para el tercer año será de V = 0.64 + 0.23 = 0.87. El cálculo es sencillo. Podría seguir así indefinidamente.
Vamos a fijarnos en una serie de datos interesantes. Primero, la fuerza asociativa va creciendo progresivamente para acercarse a su valor objetivo, lambda (en este caso, 1). Este crecimiento es negativamente acelerado. ¿Qué quiere decir esto? Como hemos comprobado, la sorpresa fue mayor en el primer ensayo que en el segundo. Y aunque no lo hemos calculado directamente, podéis creerme si os digo que la sorpresa fue mayor en el segundo que en el tercero, y en el tercero mayor que en el cuarto, etc. Conforme se reduce la sorpresa, el aprendizaje da pasos más pequeñitos, y por eso la forma de la curva es como estáis viendo. Esto se debe a que cada vez la sorpresa va siendo más pequeña: menos combustible = aprendizaje más lento.
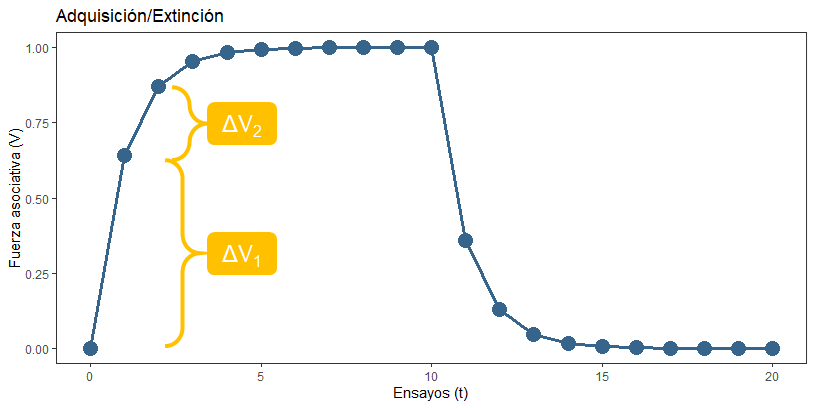
En segundo lugar, fijaos en que la adquisición y la extinción son simétricas: son exactamente el mismo proceso, sólo que al pasar de lambda = 1 a lambda = 0 estamos trabajando con una sorpresa (y por tanto ΔV) negativa.
¿Podríamos reducir V hasta que fuera negativa, bajando por debajo de 0? Podríamos, pero no con este procedimiento. Harían falta técnicas de inhibición condicionada. Lo importante es entender que cuando V es negativa el condicionamiento es inhibitorio, y esencialmente sigue siendo lo mismo: el resultado de un aprendizaje basado en la reducción de la sorpresa.
Bien, ¿y si cambiamos un poco la simulación? Como decía antes, hay estímulos que permiten aprender más rápido que otros, y eso lo reflejamos en el modelo por medio de los parámetros alfa y beta. Imaginemos qué pasaría si el estímulo EC del que estoy aprendiendo es muy poco saliente, es decir, produce poco aprendizaje, y por lo tanto su alfa es muy pequeña, pongamos de 0.2:
alphaA <- 0.2
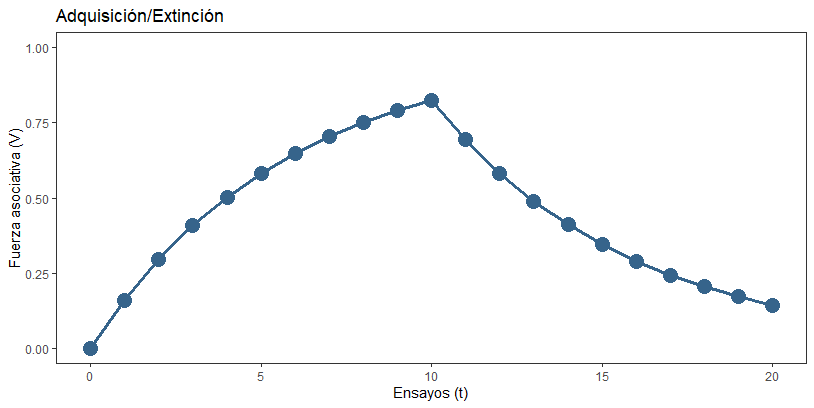
Ahí lo estáis viendo: al reducir el alfa, ahora el aprendizaje se vuelve más lento, y ni siquiera llegamos a alcanzar el valor objetivo de lambda = 1 en los diez ensayos de adquisición. Moraleja: podemos prodecir curvas con distintas formas y ritmos sólo cambiando estos parámetros de velocidad de aprendizaje, alfa y beta.
Simulaciones: Bloqueo
Y no podía faltar en esta fiesta el fenómeno de competición de claves más famoso, el bloqueo. Ya he explicado antes que fue uno de los resultados que motivó la necesidad de crear un modelo como Rescorla-Wagner, ya que implica que aprendemos sobre algo más que la mera contigüidad. Para explicar el bloqueo, Rescorla-Wagner asume que en la Fase 2 no aprendemos mucho sobre el segundo EC, B, porque ya hemos aprendido mucho con A, y por lo tanto no queda mucha sorpresa (de nuevo, recordad que la sorpresa es el combustible del modelo: si para la Fase 2 ya lo hemos gastado todo, no queda nada que aprender).
Tenemos que introducir un pequeño matiz en el modelo, porque ahora tenemos dos ECs, A y B, y cada uno tiene su propia fuerza asociativa. Hay que actualizar las dos fuerzas asociativas en cada ensayo, así que cambiamos un poco la ecuación:
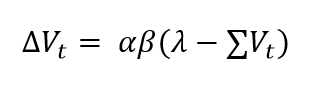
¿Veis ese símbolo griego (∑) justo delante de V en el cálculo de la sorpresa? En matemáticas, ese símbolo se lee como “sumatorio“, y quiere decir que, si hay más de un estímulo predictor (o EC) en este ensayo, vamos a sumar todas las fuerzas asociativas de los estímulos presentes. O sea, que si en este ensayo tenemos una luz y un sonido, la sorpresa se calcula como la diferencia entre lo que ha ocurrido realmente (lambda) y lo que yo esperaba, que es la suma de las expectativas producidas por ambos estímulos.
Vamos con las simulaciones del Bloqueo. Necesito especificar los vectores de entrenamiento de los dos estímulos (recordemos, 0 significa que el estímulo no está presente, 1 que sí está presente):
CueA <- c(rep(1, 20)) #El EC A está presente en todos los ensayos.
CueB <- c(rep(0, 10), rep(1, 10)) #El EC B está presente sólo a partir de la Fase 2.
Lambda <- c(rep(1, 20)) #El EI está en todos los ensayos.
alphaA <- 0.4
alphaB <- 0.4
beta <- 0.2
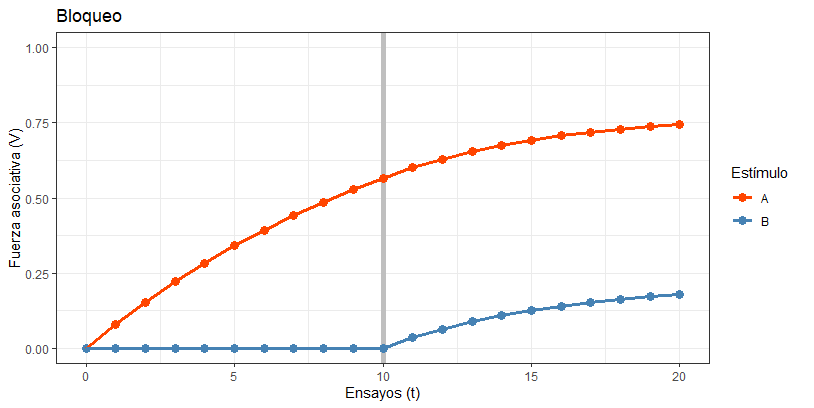
¡TACHAAAN! Como podéis ver, en la Fase 1 estamos aprendiendo de A, a buen ritmo (llegamos a predecir el EI con una fuerza de más de 0.50). Entonces llega la Fase 2 e introducimos el nuevo estímulo, B, en combinación con A. Dado que A se ha gastado buena parte de la sorpresa (el “combustible”), no queda mucho para B, así que llegamos a aprender muy poquito sobre este estímulo al final de los veinte ensayos. Así explica Rescorla-Wagner el bloqueo: dado que los dos estímulos están repartiéndose la capacidad de predecir el EI, se aprende poco sobre B, porque aparece más tarde.
Conclusiones
Vamos terminando con este post, que ya está quedando demasiado largo, y tengo que recapitular hasta dónde hemos llegado. El modelo de Rescorla-Wagner es probablemente el más famoso y exitoso de los modelos formales de aprendizaje, y a sus más de 40 años ya podemos hacer balance de qué cosas hace bien y qué cosas no hace tan bien (Siegel & Allan, 1996).
En el lado positivo de la balanza, lo primero que reseñamos es que es un modelo súper sencillo, muy intuitivo y fácil de comprender (como espero que hayáis comprobado). También es muy fácil de implementar en cualquier ordenador. Ya veis que en R se puede hacer en un par de líneas de código. Por otro lado, yo siempre llamo a la precaución ante los modelos que “parecen” sencillos, porque al final estamos haciendo predicciones dinámicas y es fácil dejarse engañar por la aparente simplicidad, así que, ante la duda, lo mejor es simular la situación de aprendizaje para ver cómo se comporta el modelo.
El segundo punto fuerte ha sido su valor heurístico, a la hora de generar hipótesis que luego se han puesto a prueba experimentalmente. Y es que el modelo de Rescorla-Wagner (como todos los modelos) tiene supuestos: el aprendizaje es gradual, las fuerzas asociativas de los estímulos se suman linealmente, la extinción es el espejo de la adquisición… Y esos supuestos inspiran experimentos que los pueden poner a prueba, permitiéndonos avanzar en el conocimiento. Pocos modelos habrán generado tal cantidad de datos empíricos, predicciones, y debate teórico.
El tercer punto fuerte es que, efectivamente, el modelo explica muchos fenómenos de aprendizaje (Miller, Barnet, & Grahame, 1995; Siegel & Allan, 1996). Explica el bloqueo, por ejemplo, razonablemente bien. Hoy en día sigue siendo el “banco de pruebas” en el que se contrasta cualquier resultado experimental en el mundo del aprendizaje.
Vamos con los puntos débiles, con los problemas del modelo.
El principal problema es que, siendo cierto que explica muchos fenómenos satisfactoriamente, está bastante claro que no puede con muchos otros resultados que sí vemos en la literatura empírica. Voy a citar algunos ejemplos:
Primero, ya he dicho que para Rescorla-Wagner la extinción es esencialmente lo mismo que la adquisición, pero al revés, y por lo tanto es una especie de “desaprendizaje“. Hoy sabemos que esto tiene que ser incorrecto, puesto que, como bien saben los terapeutas que usan técnicas de exposición, el aprendizaje que ocurre durante la extinción no “sobrescribe” o elimina lo aprendido previamente. Otro fenómeno aparentemente inexplicable por el modelo (sin añadirle supuestos extra) es el bloqueo hacia atrás.
Otra limitación es que el modelo es lo que se conoce como “cadena de Markov“. Es decir, en cada ensayo, la fuerza asociativa V depende de la fuerza asociativa del ensayo inmediatamente precedente. Por lo tanto, no permite “reconstruir” cuál ha sido la historia de reforzamiento previa. Si dos estímulos idénticos han sido entrenados de formas diferentes, pero en el ensayo t tienen la misma fuerza asociativa, se van a comportar de manera idéntica a partir de ese momento. Hay resultados en la literatura que sugieren que los animales sí somos sensibles a la historia anterior de reforzamiento.
Más limitaciones: el modelo de Rescorla-Wagner no distingue entre aprendizaje y ejecución. Es decir, si dos estímulos A y B tienen fuerza asociativa VA = 0.3 y VB = 0.9, respectivamente, la predicción es que B va a mostrar una respuesta tres veces mayor que A. La idea es que se traduce directamente la fuerza asociativa a intensidad de la respuesta. Este supuesto se ha mostrado incorrecto en multitud de escenarios y situaciones. Hoy por hoy, se entiende que el modelo está incompleto sin una buena regla de respuesta, que haga esta traducción de manera más sofisticada.
Otra limitación, para mí de las más serias, es que el modelo, siendo sensible a las contingencias, es incapaz de capturar nada más que eso, meras correlaciones entre estímulos. Sin embargo, las personas (y también otros animales) podemos guiar nuestra conducta con algo más que simples correlaciones. Por ejemplo: todos sabemos que el canto del gallo correlaciona perfectamente con el amanecer (todos los días escuchamos al gallo cantar, y justo entonces se hace de día), pero a nadie se le ocurriría el maléfico plan de obligar a cantar al gallo para adelantar la salida del sol. En otras palabras: entendemos que no es lo mismo correlación y causalidad. Esto está totalmente fuera del alcance de Rescorla-Wagner, como discuto en este artículo (Matute et al., 2019).
Me dejo la limitación más jugosa (para mí) para el final. Es un tema que me cabrea un poco. Y es que este modelo, tal vez por su posición prominente en el área del aprendizaje, por lo bien asentado que está entre los investigadores, o por lo que sea, tiene la consistencia de un chicle. Se estira, se estira, y puede acomodarse a cualquier forma. Esto significa que, en realidad, Rescorla-Wagner puede explicarlo TODO (o casi), y por lo tanto pierde su capacidad discriminativa y se vuelve casi inútil. Veréis por qué.

Primero, tenemos los parámetros de velocidad de aprendizaje, alfa y beta. Generalmente estos valores no son conocidos, y pocas veces podemos predecir si un estímulo va a ser más saliente (tener un alfa mayor) que otro. Son parámetros libres. Si en mi experimento el animal ha aprendido muy rápido, diré que alfa es muy grande, y el modelo lo predice. Pero si ha aprendido muy despacio (el resultado contrario), diré que alfa es pequeña, y el modelo también lo predice. WIN-WIN. Recordemos que modificaciones posteriores del modelo (Van Hamme y Wasserman) permiten todavía más flexibilidad jugando con estos parámetros de velocidad de aprendizaje. Más aún: modelos similares a Rescorla-Wagner como el de Pearce y Hall proponen que los parámetros de aprendizaje no están fijos durante el entrenamiento, sino que van cambiando en función de lo que se aprende. Estiramos el chicle un poco más.
Además, podemos añadir supuestos extra al modelo. ¿Que no se puede explicar un resultado raro? Pues propón, por ejemplo, que se forman asociaciones “intra-compuesto” entre los elementos de un compuesto de estímulos. O que existe una tendencia hacia considerar los estímulos compuestos como agrupaciones estimulares o como elementos libres, y que eso depende de otros factores… Buf. El chicle permite alargarse, alargarse, hasta explicar cualquier conjunto de datos, sean reales o inventados.
Si os ponéis a revisar la literatura, veréis ejemplos de esto que estoy diciendo. Prácticamente no hay resultado contrario a las predicciones de Rescorla-Wagner que no se pueda acomodar a posteriori por medio de la inclusión de nuevos supuestos o de la tortura de los parámetros libres. Lo que me fastidia de esta habilidad que tienen mis colegas para estirar el chicle de Rescorla-Wagner es que, mientras tanto, están obviando otras propuestas teóricas diferentes que están ahí, que explican el resultado sin tanta pirueta, y que por cuestiones de tradición (cuando no directamente por una cuestión emocional) pasan a segundo o tercer plano. Una pena. Pero bueno, esto era un comentario personal.
Hasta aquí por hoy, que este ha sido un post muy largo. ¡Espero que os sirva para estudiar!
(*) Nota: Si me lee algún conductista, es posible que le entren ganas de colgarme por los pulgares por emplear tan profusamente un término mentalista como “expectativa”. Pues bien, sí, tiene razón, lo admito, pero me importa poco ahora mismo: yo escribo para que me entienda el común de los mortales (o la mayoría). Evidentemente se puede traducir el concepto en términos menos “esotéricos”, por ejemplo como una tendencia a ejecutar respuestas de anticipación del EI. También me podría ahorrar los globitos con verbalizaciones de “lo que piensa un perrito” y otras inexactitudes que estoy cometiendo. Pero en aras de facilitar que se entienda el mensaje principal, prefiero sacrificar un poquito de rigor. ¿Me lo permitís por hoy? 🙂
(**) Nota: la letra griega delta (Δ) se suele emplear en matemáticas y en otras ciencias para indicar un incremento en una variable. Así, podéis leer ΔV como “incremento en V”. Eso sí, tened la precaución de recordar que a veces este incremento es negativo (o sea, un decremento).
Referencias
- Kamin, L. (1968). “Attention-like” processes in classical conditioning. In M. R. Jone (Ed.), Miami Symposium on the Prediction ofBehavior, 1967: Aversive Stimulation (pp. 9–31). Coral Gables (Florida): University of Miami Press.
- Matute, H., Blanco, F., & Díaz-Lago, M. (2019). Learning mechanisms underlying accurate and biased contingency judgments. Journal of Experimental Psychology: Animal Learning and Cognition, 45(4), 373–389. https://doi.org/10.1037/xan0000222
- Miller, R. R., Barnet, R. C., & Grahame, N. J. (1995). Assessment of the Rescorla-Wagner model. Psychological Bulletin, 117(3), 363–386. https://doi.org/10.1037/0033-2909.117.3.363
- Pearce, J. M., & Bouton, M. E. (2001). Theories of associative learning in animals. Annual Review of Psychology, 52, 111–139. https://doi.org/10.1146/annurev.psych.52.1.111
- Rescorla, R. A., & Wagner, A. R. (1972). A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. In A. H. Black & W. F. Prokasy (Eds.), Classical Conditioning II: current research and theory (pp. 64–99). New York: Appleton-Century-Crofts.
- Siegel, S., & Allan, L. G. (1996). The widespread influence of the Rescorla-Wagner model. Psychonomic Bulletin & Review, 3(3), 314–321. https://doi.org/10.3758/BF03210755
- Widrow, B., & Hoff, M. E. (1960). Adaptive switching circuits. IRE Western Electric Show and Convention Record, Part 4, 96–104.

Pingback: Apuntes Psicología del Aprendizaje - Kibbutz Psicología
Gracias por el post y por explicarlo paso a paso, me ha servido muchísimo para entender mejor 😀 !!
LikeLike
muchas gracias! tus explicaciones “mundanas” son realmente útiles y fáciles de entender para las personas que no estamos habituadas a estas teorías y fórmulas. Haces fácil lo complejo. gracias! 😀
LikeLike
muchas gracias! tus explicaciones hacen fácil lo complejo y ayudan a entender conceptos y fórmulas que para el 99% de mortales son difíciles de asimilar 😀
LikeLike
Muy top! mil gracias!
LikeLike
Muchas gracias por este post, de verdad! He visto la luz. Es aclaratorio, dinámico e incluso divertido.
Una estudiante de primero de psicologia!
LikeLike