Según mi experiencia, primero como alumno, y segundo como docente, no hay materia que más miedo meta en el cuerpo de los estudiantes de Psicología que la fatídica estadística. Seguro que más de uno tiene flashbacks de cuando estudiaba la carrera que son dignos de un veterano del Vietnam.
Por otro lado, la misma experiencia me dice que en gran parte este miedo nace del desconocimiento inicial, y en muchos casos se acentúa porque tanto los profesores como los manuales son muy dados a entrar de lleno en las ecuaciones, cuando aún no estamos dotados del conocimiento básico para desentrañarlas. Al final, muchos estudiantes acaban por resignarse y limitarse a repetir las mismas formulitas y operaciones sin entenderlas, como si fueran el perro de Pavlov… Al igual que los investigadores novatos nos acostumbramos a confiar en software engañosamente sencillo (SPSS, estoy pensando en ti), repitiendo clics con el ratón como un ritual y sin comprender lo que está haciendo la máquina entre bambalinas.
Por suerte, en un momento dado de mi vida conté con el apoyo y la cabezonería necesarios para, por fin, ¡empezar a ver la luz! Y la clave estaba delante de mis narices. Las ecuaciones y fórmulas están bien, sirven para realizar operaciones y establecer analogías entre conceptos, pero habíamos olvidado un paso básico, anterior: ¡la estadística hay que visualizarla para comprenderla! Nada como una buena visualización para comprender (aunque sea intuitivamente) un concepto. Después podemos ir a las ecuaciones y profundizar, pero ese paso es, al menos para mí, fundamental para entender algo.
La segunda gran herramienta para entender la estadística llegó mucho más tarde, cuando aprendí un poco de programación: las simulaciones. ¿Te surge una duda de qué ocurriría en un escenario concreto? Bien, ¡simúlalo y responde tu pregunta! Hoy en día es una de los métodos que más utilizo para aprender (y el más divertido). Y os prometo que aprendo algo nuevo casi a diario.
En esta serie de posts que inauguro ahora, intentaré ilustrar un par de conceptos básicos de estadística mediante estas dos herramientas: visualizaciones y simulaciones con el programa R. Espero que, si estás estudiando psicología u otra carrera en la que se utilice el análisis de datos, te sirva para ver que la estadística no es tan complicada. ¡Vamos al lío!
La lógica del análisis
Seguramente ya conocéis la rutina de la estadística que usamos habitualmente en psicología (frecuentista, basada en el test de significación para la hipótesis nula, NHST), pero la vamos a repasar en este post antes de avanzar hacia temas más interesantes.
El primer paso es plantearse una pregunta de investigación. Por ejemplo, ¿quién gasta más dinero en champú y cosméticos para el cabello, los jugadores de fútbol, o los fans del heavy metal? Esta pregunta se puede resolver recolectando datos. En este caso, contactaríamos con una muestra de jugadores de fútbol y de aficionados a los Judas Priest, y les preguntaríamos cuánto dinero se dejan al mes en este tipo de productos. Para cada uno de los grupos tendríamos un gasto mensual promedio. ¡Pan comido!
Ahora nos debemos plantear dos posibles escenarios: o bien no hay diferencias entre los dos grupos (Hipótesis nula, H0), o bien sí las hay (Hipótesis alternativa, H1).
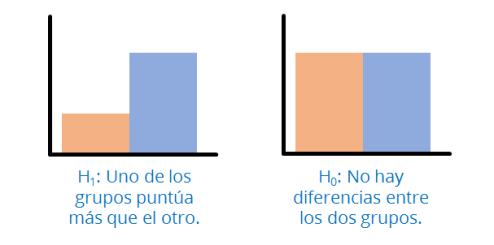
En nuestra muestra, seguramente las dos medias obtenidas no serán idénticas, es decir, habrá alguna diferencia entre los dos grupos. Por ejemplo, podría ser que los metaleros gastasen, de media, 3.53 euros más que los jugadores de fútbol. Esta diferencia observada en mi muestra es el tamaño del efecto observado. En este caso lo estamos expresando en las unidades de medida (euros), pero suele ser más conveniente convertirlo a una escala estandarizada. Por ejemplo, podría usar la d de Cohen, que se calcula usando las medias obtenidas, sus desviaciones típicas, y los tamaños de muestra. La ventaja de usar un tamaño del efecto estandarizado es que me permite comparar situaciones muy diversas.
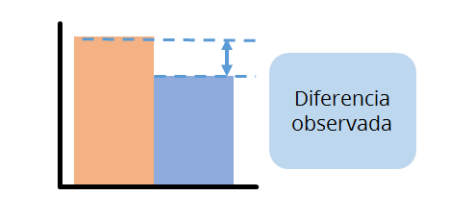
Ahora bien, que haya una diferencia en mi muestra no quiere decir que ésta sea extrapolable a la población. A mí no me interesa saber si en mi muestra gastan más o menos dinero unos que otros, porque eso es trivial. Lo que quiero saber es qué ocurre de manera general, ¿verdad? Tenemos que tener claro el concepto de error de muestreo. Mi muestra ha sido extraída aleatoriamente de la población, y por lo tanto los parámetros que yo mida en mi muestra no tienen por qué corresponderse con los de la población. Pensad en el siguiente ejemplo: imaginemos un bombo de la lotería, con cientos de números pares e impares. Si yo extrajera una muestra del bombo de, pongamos, 3 bolas, y comprobara que dos de ellas han salido pares… ¿quiere eso decir que el bombo contiene dos tercios de bolas pares? ¡Claro que no! La muestra está sujeta a un error aleatorio. Si repito la extracción, podría salirme un resultado completamente distinto, como por ejemplo las tres bolas impares, o las tres bolas pares… Extrapolar es siempre arriesgado, pues implica incertidumbre.
Bueno, entonces, ¿cómo damos el paso de la diferencia observada en mi muestra a la población general? Es para eso precisamente que usamos la estadística, para cuantificar esa incertidumbre y usarla para tomar decisiones. En este ejemplo, como estamos comparando dos medias, podríamos hacer una prueba t. El cálculo es sencillo, pero como decía antes, mejor visualicemos:
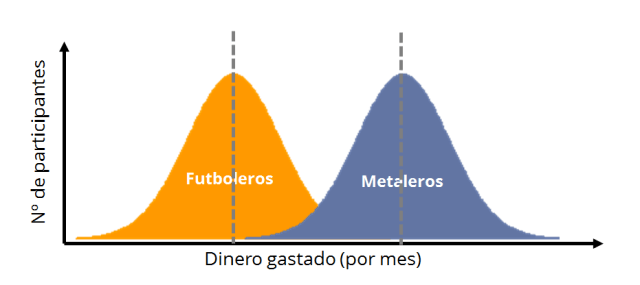
En la figura, he dibujado las distribuciones de los dos grupos, con su característica forma de campana (distribuciones normales o Gaussianas). Las líneas verticales representan las medias de cada grupo. En esta metáfora visual, nos interesa saber cuánto se solapan las dos distribuciones. Si se solapasen en gran medida, diríamos que no hay diferencias apreciables entre los grupos. Ahora bien: hay dos parámetros que nos van a indicar el grado de solapamiento. En primer lugar, la distancia entre las dos medias, que hemos llamado antes “tamaño del efecto”. Así es, cuanto más separadas estén las medias, menos solapamiento. El segundo parámetro de interés es la “anchura” de las distribuciones (su parámetro de dispersión, como por ejemplo la desviación típica). Si las distribuciones son anchas, ocuparán más espacio y por tanto se solaparán en mayor medida que si fueran estrechas (siguiente imagen).
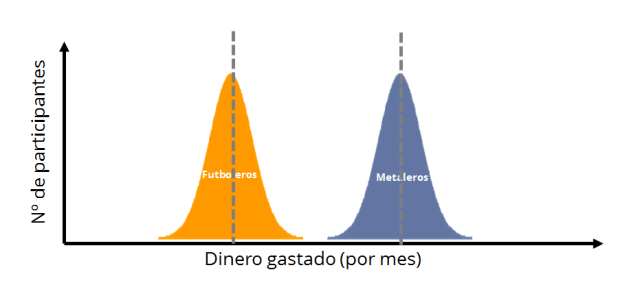
Simplificando bastante el concepto, diré que la prueba t consiste en calcular un estadístico (la t de Student) que utiliza estos dos parámetros para saber cuánto se solapan las distribuciones: cuando hay mucho solapamiento, t tendrá un valor pequeño, mientras que cuando las distribuciones están muy separadas, t adquirirá valores altos. Si vais a la ecuación del estadístico, comprobaréis cómo efectivamente es una función de la diferencia de medias, y que las desviaciones típicas aparecen en el denominador (a más anchura, mayor solapamiento, y menor valor de t).
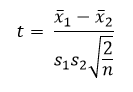
Este valor de t tiene otro estadístico asociado a él, que es el p-valor. ¿Qué significa? Imaginemos ahora por un momento que la hipótesis nula (H0) fuera correcta. Eso quiere decir que no hay diferencias reales (en la población) entre los dos grupos. Por lo tanto, cualquier diferencia que hubiéramos detectado en nuestra muestra se debería al azar, al error de muestreo. Pensemos ahora: ¿cómo de probable sería encontrarnos por puro azar con una diferencia como la que hemos hallado, de 3.53 euros? La lógica nos dice que una diferencia grande sería poco atribuible al azar, ¿verdad? Imaginad por un momento que la diferencia encontrada en nuestra muestra hubiera sido de 300 euros. ¡Sería muy improbable encontrar un valor tan alto por pura casualidad!
Pues bien, el p-valor es la probabilidad de encontrarnos por puro azar con una diferencia como la que hemos hallado, o mayor. Así, si el p-valor es muy pequeño, concluiremos que la diferencia encontrada es demasiado grande como para atribuirla al azar, y que probablemente habrá también diferencias en la población. Aquí es donde entra en juego el famoso umbral de significación, un valor arbitrario, escogido por convención, que nos permite tomar decisiones. Si p < 0.05, decimos que el resultado es estadísticamente significativo, y que podemos rechazar la hipótesis nula, porque la diferencia es demasiado improbable por azar. Por otro lado, si p > 0.05, el resultado no es significativo, y concluimos que las diferencias pueden explicarse por azar (provisionalmente retenemos la hipótesis nula porque no tenemos evidencia para rechazarla).
Hasta aquí hemos descrito el proceso que va desde la recogida de datos hasta la toma de decisión basada en los datos del estudio. De momento no ha habido simulaciones, pero estoy deseando enseñaros algunas en el próximo post, que espero llegue pronto (si el trabajo lo permite).

Muchas gracias, estuvo bastante claro y creo que ese es el objetivo cuando se escribe para informar
LikeLike
Fernando, qué buen resumen para comenzar a enseñar sobre una de las áreas de la matemática de la cual se habla mucho pero que se entiende muy poco.
Muy clara la idea de que lo que desconozco me da miedo. Y eso aplica a la estadística.
LikeLike
Excelente!!!! Gracias!!!
LikeLike