Ahora que todo el mundo está confinado en casa por culpa de un peligroso bicho, he pensado que era buen momento para recuperar el blog, sobre todo porque la ansiedad del momento no me permite concentrarme en otras cosas. Esta vez voy a hablar de algo un poco diferente. Mi plan es demostraros, con un par de simulaciones de R, por qué no podemos creer una parte apreciable de la literatura científica publicada. ¿Quiere esto decir que los científicos/as están mintiendo? No exactamente, como veremos. Vamos allá.
Cuatro tipos de resultado
Para hacer nuestras simulaciones, voy a tener que crear un modelo que represente el proceso que estamos intentando describir, en este caso, el de publicación de un artículo científico. Lo primero que tenemos que hacer es considerar que cuando los investigadores/as realizamos un estudio, generalmente estamos poniendo a prueba una hipótesis. Por ejemplo: ¿Correlacionarán la ansiedad académica y el estrés en los estudiantes? ¿Funcionará este nuevo fármaco para tratar la diabetes? En cualquiera de estos casos, los investigadores hacen una predicción (la correlación entre ansiedad y estrés es mayor de cero, el fármaco reduce los síntomas de la enfermedad con respecto a un control…) que es puesta a prueba en el estudio, mediante un conjunto de técnicas que llamamos “contraste de hipótesis”, o “contraste de significación para la hipótesis nula” (NHST, por sus siglas en inglés). La lógica del NHST la hemos cubierto ya en un post previo, que tenéis aquí.
Por abreviar, en el estudio se obtiene un estadístico, llamado “p-valor”, que nos indica cómo de improbable es el resultado observado si asumimos que la hipótesis nula es cierta, es decir, que el resultado se debe únicamente al azar. Si el resultado del estudio es significativo (generalmente, p < 0.05), rechazaremos provisionalmente la hipótesis nula. Si el resultado no es significativo (p > 0.05), diremos que no podemos descartar que la hipótesis nula sea cierta, es decir, que no podemos decir que el resultado no se deba enteramente al azar. Fijaos en un detalle curioso: en este proceso, en ningún momento se habla directamente de la hipótesis que tenía el investigador en mente, conocida como la hipótesis alternativa. Simplemente se toma una decisión sobre si descartar o no la hipótesis nula para un estudio concreto.
Lo que pasa es que, como vimos en un post previo, el error de muestreo es bastante traicionero, y puede conseguir que, por puro azar, observemos resultados en nuestra muestra que no se corresponden con la realidad (con la población). Así que la situación quedaría recogida en una tabla como esta:
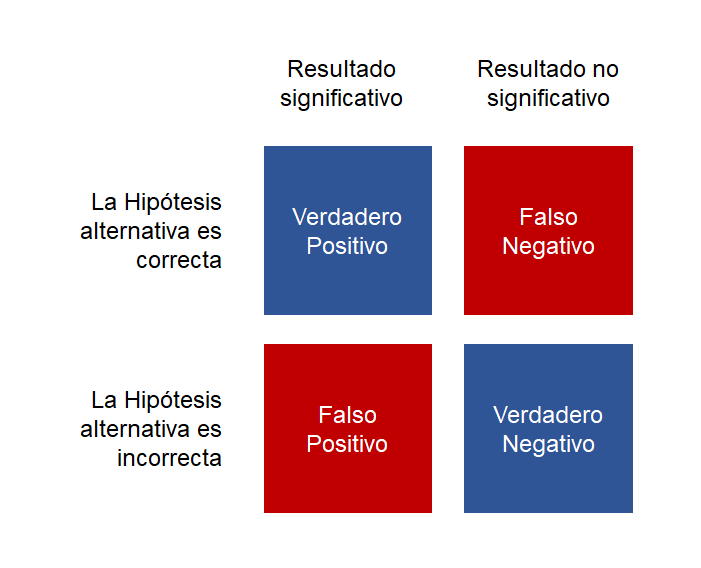
Dado que la hipótesis que plantea el investigador puede ser correcta o incorrecta, tenemos dos formas de acertar y dos formas de equivocarnos: si la hipótesis alternativa era correcta y el p-valor significativo, estamos ante un “verdadero positivo”. Por el contrario, si la hipótesis alternativa era correcta, pero el p-valor no era significativo, estamos ante un “falso negativo”, o “error Tipo II”. Un “falso positivo”, también conocido como “error Tipo I”, aparecerá cuando nuestra hipótesis de partida era incorrecta, pero nuestro resultado es significativo. Por último, si nuestra hipótesis era incorrecta y el p-valor es no significativo, habremos dado con un verdadero negativo. En total, cuatro tipos de resultado que nos podemos encontrar en cualquier estudio que emplee contraste de hipótesis.
Ahora vamos a plantearnos en qué proporciones se distribuyen en la literatura publicada estos cuatro tipos de resultado. Idealmente, para que fuera plenamente fiable, querríamos que la literatura contuviese cuantos más verdaderos positivos y negativos mejor, y nos gustaría que no tuviera mucha representación de falsos resultados, ¿verdad? En otras palabras, querríamos que el proceso de publicación actuase como un filtro que dejase pasar solo los resultados verdaderos. Ya veremos que eso entra en el terreno de la utopía…
El proceso de publicación en un mundo ideal
Vamos a empezar a simular el proceso de publicación con R. Para ello, tenemos que definir un modelo que nos permita saber qué estudios se van a publicar y qué estudios no. Evidentemente, el modelo será una simplificación muy burda de la realidad, mucho más compleja, pero estamos aquí para aprender y reflexionar…
Comencemos planteándonos qué porcentaje de las hipótesis que los científicos y científicas se plantean son correctas. Podría ser razonable asumir que en algunas áreas los expertos tienen una capacidad predictiva con alta precisión, de forma que prácticamente sólo plantean hipótesis correctas. Sin embargo, en el contexto de la psicología, donde no tenemos teorías bien desarrolladas y aún discrepamos en asuntos fundamentales (como el de la medición, o incluso el objeto de estudio), creo que es más sensato admitir que, muy a menudo, los investigadores plantean hipótesis que no se corresponden con la realidad. En principio esto no tiene nada de malo, puesto que así también se puede avanzar: basta con hacer estudios y comprobar que estas hipótesis incorrectas no acumulan evidencia a su favor.
En resumen, y siendo generosos, vamos a asumir que la probabilidad de atinar con una hipótesis correcta es de 0.6 (es decir, el 60% de las veces que planteamos una nueva hipótesis, esta es cierta).
A continuación, ¿cuál será la probabilidad de obtener un resultado significativo? Dependerá, lógicamente, de si la hipótesis planteada es cierta o no. Si es cierta, debería ser más fácil encontrar un p-valor que la sostenga. En concreto, si la hipótesis en cierta, la probabilidad de obtener un resultado significativo se llama potencia estadística. Si necesitas refrescar este concepto, no te preocupes, repasa este post previo. Por convención, se dice que un valor aceptable de potencia estadística no debe ser inferior a 0.8. Es decir, deberíamos diseñar nuestros estudios de manera que, si de verdad el efecto que buscamos existe, lo encontremos el 80% de las veces.
¿Cuál es la probabilidad de obtener un falso positivo? En este caso es también una cantidad conocida. Cuando planteamos una hipótesis incorrecta (es decir, un efecto que no existe realmente), imponemos un criterio para que el error Tipo I (falso positivo) no ocurra más del 5% de las veces (revísalo en este post si te hace falta). Por lo tanto, la probabilidad de este tipo de resultado es 0.05, ó 5%.
Ahora continuamos. El estudio está realizado, y el análisis ha sido significativo o no. Queda la tarea de escribirlo e intentar publicarlo en una revista. Es bien conocido que este proceso no es del todo neutral, pues se ha documentado la presencia de sesgos de publicación. Fundamentalmente, existe un sesgo a favor de los resultados significativos. Es decir, a las editoriales no les gusta publicar resultados no concluyentes, o no significativos. Esto quiere decir que es más fácil publicar un resultado significativo (sea auténtico o falso) que uno resultado no significativo. Así nace también el concepto del “cajón de los fracasos”, conocido como “the file drawer problem”: una buena parte de los resultados, sea por no ser significativos o por otros motivos, acaban sin publicarse. Esto quiere decir que echamos a perder muchísima información que podría ser valiosa, junto con otra que no.
Para modelar este sesgo de publicación, vamos a asumir que el 50% de los resultados significativos se publican, pero solo el 1% de los resultados no significativos, independientemente de que sean resultados verdaderos o falsos. En este caso, los números me los he inventado, pero podrían ser una opción razonable (agradecería comentarios, es fácil rehacer la simulación con otros valores de partida).
Ya tenemos todos los elementos que componen nuestro proceso (simulado) de publicación, de forma que podemos averiguar cómo de probable es que cada uno de los cuatro tipos de resultado de la tabla acabe publicado en la literatura.
Aquí tenéis el código de R que permite hacer la simulación completa. En cada paso del proceso, utilizamos una distribución binomial para decidir si el estudio sale significativo o no, o se publica o no:
H <- 0.6 #probabilidad de proponer una H correcta.
power <- 0.8 #probabilidad de detectar un efecto que existe.
alpha <- 0.05 #probabilidad de detectar un efecto que no existe.
PubPos <- 0.5 #Probabilidad de publicar un resultado significativo.
PubNull <- 0.01 #Probabilidad de publicar un resultado no significativo.
nSims <- 10000 #Número de simulaciones.
sims <- data.frame(H = rbinom(nSims, 1, H))
sims<-
sims %>%
mutate(PSig = (H*power)+((1-H)*alpha)) %>%
mutate(Sig = rbinom(nSims, 1, PSig)) %>%
mutate(tipo =
ifelse((H==1)&(Sig==1), "True Positive",
ifelse((H==1)&(Sig==0), "False Negative",
ifelse((H==0)&(Sig==1), "False Positive",
ifelse((H==0)&(Sig==0), "True Negative", NA
))))) %>%
mutate(Publish = rbinom(nSims, 1, ((Sig*PubPos)+((1-Sig)*PubNull))))
El resultado de la simulación es el siguiente:

Así es la disección de la literatura científica en un mundo ideal. En la literatura publicada (derecha) proliferan los resultados significativos (un 94%), por efecto del sesgo de publicación. Sólo una mínima parte de los resultados publicados son nulos (no significativos). La probabilidad de encontrarse con un falso positivo es incluso algo menor a la probabilidad nominal del error Tipo I (4%). Sólo es una pena que tengamos en el cajón (izquierda) un montón de resultados aparentemente válidos: verdaderos positivos, y sobre todo verdaderos negativos. Pero no es algo muy grave, y por lo menos el proceso ha filtrado correctamente los falsos negativos, que es lo que más nos interesaba.
Bah… Contened la emoción. No os creáis nada de esto. Como suelen decir de los modelos matemáticos, “garbage in, garbage out”. Y es que el modelo es simplista, pero además hemos partido de unos supuestos que en la realidad sabemos que no se sostienen. Vamos a ver por qué.
Disección de la literatura en el mundo real
Es que vamos a ver. La simulación anterior se ha basado en números óptimos, increíbles. La realidad va a ser muy distinta. A continuación voy a repetir la simulación con otros valores que creo más cercanos a la realidad.
Para empezar, ¿es sensato asumir que más de la mitad de las veces que plantemos una hipótesis ésta sea correcta? A mí ya de entrada me parece una exageración, especialmente en psicología. Aun así, como no quiero que sea el foco de este argumento, voy a dar el supuesto por bueno: seguiremos asumiendo que el 60% de las hipótesis son, a priori, correctas.
Hemos dicho que la potencia mínima recomendable a la hora de diseñar un estudio es del 80%. Algunos autores proponen más, un 90%. Esto requiere muestras muy grandes de participantes, y en principio garantizaría que no hacemos estudios faltos de potencia que pasen por alto los efectos que estamos buscando. Sin embargo, hacer un estudio con buena potencia es muy caro. Casi nadie sigue la recomendación del 90%, ni del 80% siquiera. Yo sigo encontrándome con artículos en revistas de alto impacto con muestras de 10 participantes por celda. ¿Cuál sería un valor más realista de la potencia en psicología? Esto depende muchísimo del área de estudio (no es lo mismo el área de personalidad que la de social o la de neurociencia), pero algunas estimaciones nos dejan bastante mal. Por ejemplo, hay estudios que nos asignan una potencia promedio del 50%, que es como lanzar una moneda al aire, e incluso todavía peores, rondando el 30%.
Treinta. Por. Ciento.
En fin, que sí, que tenemos un problema serio de potencia. Actualizaremos la simulación con este dato.
Más problemas que nos impone la dura realidad. Hemos dicho que la tasa de error Tipo I debería mantenerse por debajo del 5%, ¿verdad? Bien, pues tampoco es así en la vida real. ¿Habéis oído hablar del p-hacking? Se trata de un conjunto de técnicas, algunas de ellas muuuuy extendidas, que consisten en alterar el proceso de análisis de datos para obtener un p-valor significativo. Por ejemplo, es habitual que la gente pruebe distintos tipos de análisis hasta dar con el que mejores resultados produce, o excluya participantes sin un plan previo… Debo aclarar que, aunque el p-hacking se considere una práctica cuestionable, no siempre es premeditado, ni se hace con la intención de engañar. De hecho, puede ser muy sutil. En cualquier caso, y juicios aparte, ahora nos interesa tener una estimación de cómo de grave es el problema, es decir, cómo de fácil es conseguir mediante el p-hacking que un resultado no significativo se vuelva significativo. Pues bien, agarraos a la silla, porque un estudio se dedicó a calcularlo y…
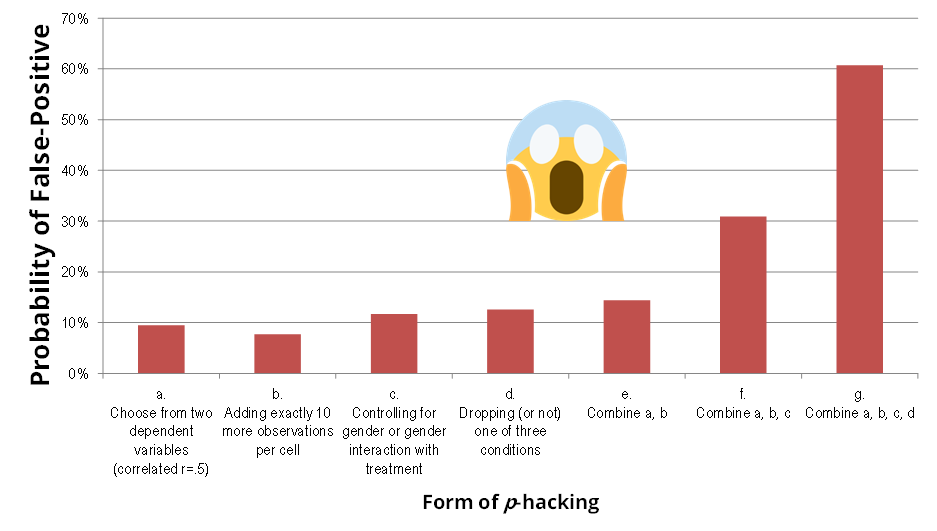
Eso es, ¡puede llegar al 60%! Es una barbaridad. Por supuesto, esto no quiere decir que todos los estudios se hayan p-hackeado en tal grado. Siendo conservador, para la nueva simulación voy a asumir que, al tener en cuenta que hay algunos estudios p-hackeados, la probabilidad del falso positivo se incrementa desde un 5% hasta un 25%.
En cuanto al sesgo de publicación, lo vamos a dejar como estaba, que bastante grave era en la primera simulación.
Con estos nuevos datos, he rehecho las simulaciones y obtengo el siguiente patrón:

¡Hay más de un 30% de la literatura que son falsos positivos! Es decir, son resultados significativos que se usan para apoyar la existencia un efecto que no existe realmente. La pena es que el sesgo de publicación, esa preferencia por publicar los resultados significativos, impide que pasen a la literatura gran parte de los negativos verdaderos, que podrían compensar a los falsos positivos.
Conclusiones
No puedo afirmar con rigor que los resultados de la segunda simulación se acercan más a la realidad que la primera figura. No puedo, pero vamos, que lo creo. Por desgracia. La consecuencia es que hay una porción nada desdeñable de la literatura científica que presenta conclusiones falsas. ¿Tal vez estoy siendo demasiado pesimista? Hay quien iría más lejos todavía, o si no leed a Ioannidis.
¿Cómo separar el grano de la paja? Esto es lo más complicado. Muchas veces no lo podemos saber. En ocasiones, los falsos positivos se delatan por sus números imposibles: muestras pequeñas, abundancia de resultados significativos, análisis de muchas variables dependientes o indicadores a la vez… Pero admito que en el resto de los casos, es imposible diferenciar a simple vista los resultados poco fiables. Creo que las revistas podrían dar un paso al frente y ayudarnos un poco, simplemente relajando sus criterios para permitir la publicación de resultados nulos con más frecuencia. Esto tendría la consecuencia directa de que podríamos confrontar un falso positivo (obtenido por azar) con otros estudios que no encuentren el mismo efecto. A la vez, al no exigir un umbral de significación para la publicación, seguramente descendería la incidencia de algunas formas de p-hacking, al perder incentivos.
