
¡Estamos de vuelta! Vamos a seguir con esta serie de posts analizando todas esas prácticas estadísticas que, queramos o no, acabamos haciendo mal. Hoy vamos a recuperar dos conceptos ya tratados, la falta de potencia estadística y el sesgo de publicación, para preguntarnos: ¿podrían estos dos factores, conspirando juntos, cargarse completamente la literatura publicada? ¿Deberíamos poner toda nuestra confianza y fe en los famosos meta-análisis (combinaciones de múltiples estudios)? Os lo cuento.
Simulando una literatura con baja potencia
El primero de los conceptos que tenemos que refrescar es el de potencia estadística. Lo hemos comentado ya en un par de post anteriores en la serie sobre estadística visual (aquí y aquí), pero os lo recuerdo: la potencia estadística es la probabilidad de que mi estudio encuentre un resultado significativo, sabiendo que el efecto que busco es real. Es decir, si por ejemplo asumo que las mascarillas de tela pueden reducir la tasa de infección por el SARS-COV19, un estudio con una potencia del 0.50 (50%) sólo podría detectar un resultado significativo la mitad de las veces. Por eso generalmente queremos potencias altas, lo que implica, entre otras cosas, trabajar con muestras grandes. El beneficio añadido de tener muestras grandes es que reducimos el impacto del error de muestreo (como vimos en este otro post), mejorando la precisión de nuestras estimaciones.
Además, la potencia debe ir en consonancia con el tamaño del efecto que estoy buscando, como ya expliqué. Si busco un efecto pequeño, necesito que el estudio tenga mucha potencia (muestras grandes, mediciones precisas), o de lo contrario no podré detectarlo, es decir, no tendré resultados significativos, a pesar de que el efecto sea real.
Lo lógico sería, entonces, que los investigadores diseñáramos experimentos de alta potencia, para asegurarnos de captar los efectos que buscamos aunque sean pequeños, y de paso mejorar nuestras estimaciones. Lo que pasa es que un estudio grande y potente es también costoso. Como resultado, en algunas áreas de la ciencia tenemos un déficit sistemático de potencia. Por poner un ejemplo, usar muestras de unas pocas docenas de participantes sigue siendo relativamente habitual en campos como la nutrición deportiva o la neuroimagen. Esto implica que la gran mayoría de los estudios que se hacen en estas áreas producen (en principio) resultados nulos, no significativos. Pero, ¿qué consecuencias tiene esto para ti, que estás documentándote y leyendo papers para preparar tu TFG o TFM? ¿Cómo puede la baja potencia contaminar la literatura e impedir que tus conclusiones sean correctas?
Ya sabéis que una de las técnicas que más me gustan para aprender de estadística es la simulación: utilizar programas informáticos para representar escenarios posibles, cambiar sus parámetros, y ver cómo esto les va afectando. De modo que voy a reciclar un código de R que vimos en un post anterior para imaginar qué pasaría si, en un área concreta de la investigación, hubiera un déficit de potencia sistemático como el que he descrito. Vamos al lío.
He simulado 10.000 estudios aleatorios que investigan un mismo efecto. Este efecto es real, y tiene un tamaño del efecto poblacional de d=0.3, es decir, un efecto pequeño a moderado. Os recuerdo que en la realidad no podríamos conocer este dato, ¡es lo bueno que tienen las simulaciones, que me lo puedo inventar! Cada estudio tiene una muestra que a priori es poco potente: N = 20 (comparamos dos grupos de 10 personas).

Este gráfico, como ya os he contado otras veces, es la distribución de los 10.000 p-valores que he calculado. Solamente una porción de los estudios, marcada en naranja, ha producido un resultado significativo (p < 0.05). En este caso, alrededor un 10% de los resultados son significativos, lo que implica que en esta simulación hemos encontrado una potencia de aproximadamente el 10%, o 0.1. ¡Una birria! ¡Un derroche!
Primera moraleja: Si leéis un estudio donde dicen que el tamaño del efecto es de d=0.3 o menor, y la muestra es de N=20 o menor… O bien han tenido una suerte increíble (solo un 10% de los estudios deberían dar resultado significativo), o bien se están callando los otros 9 estudios donde el resultado no era significativo. O bien… hay algo raro.
Bueno, alguno estará pensando, ¿y qué si se están derrochando los recursos en hacer estudios poco potentes? Siguen siendo estudios válidos, pueden aportar información. Sí, claro, es cierto. Pero con matices. En primer lugar, antes os comenté que los estudios con baja potencia también producen estimaciones poco precisas de los efectos. Por ejemplo, en nuestras simulaciones sabemos que el efecto real es d=0.3, y efectivamente, el efecto promedio observado en los 10.000 estudios se acerca mucho a ese valor, ¡pero con mucha dispersión! Veis que hay muchos estudios con estimaciones del tamaño del efecto de d>1, o incluso cercanos a d=2… Y también un número nada despreciable de estudios que se equivocan en el signo, es decir, estiman efectos negativos, que indicarían una diferencia entre grupos, pero en la dirección contraria, como por ejemplo, encontrar que usar la mascarilla facilita la propagación del virus. ¿Lo veis?

De nuevo, podemos tener a algún escéptico moviendo la cabeza, pensando “¿Y qué más da? Lo importante es que los estudios no están sesgados, simplemente carecen de precisión por tener muestras pequeñas”. Y es cierto, tiene razón: el promedio del efecto que hemos observado en nuestros 10.000 estudios (punto blanco en la figura) se acerca mucho al valor real (línea vertical). Además, contamos con una herramienta que nos permite agregar múltiples estudios en uno solo, para estimar el tamaño del efecto combinado, la técnica conocida como “meta-análisis”. Podríamos hacer meta-análisis y simplemente no confiar demasiado en los estudios aislados. ¡Caso cerrado!
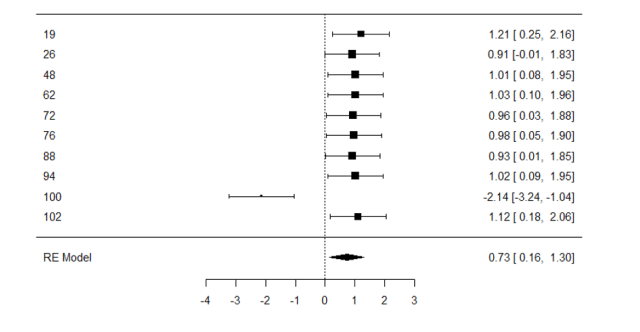
De hecho, a modo de experimento, aquí tenemos un meta-análisis con los primeros 10 estudios de esta simulación. La estimación del efecto, que se representa con ese diamante que veis ahí, se acerca mucho a la d=0.3, que sabemos que es el valor correcto. Lo que pasa es que hay tanto ruido en los datos, tan poca precisión, que ni agregando 10 estudios conseguimos que sea significativo.

Pero incluso este escenario peca de optimista. Y lo es porque la literatura publicada no tiene el aspecto que os estoy enseñando en estas figuras, debido a un proceso conocido como publicación selectiva, o sesgo de publicación, del que ya hablé en el anterior post. En pocas palabras: el sesgo de publicación consiste en que determinados resultados tienen más facilidad que otros de verse publicados. Por ejemplo, los estudios con resultados significativos o que encajan con las teorías y expectativas actuales se publican más fácilmente que los estudios no concluyentes o que no producen resultados significativos.
Entonces, ¿qué pasa si tenemos un montón de estudios de baja potencia, y ahora seleccionamos sólo los positivos para que se publiquen? ¿Puede eso sesgar, y por lo tanto contaminar la literatura? ¡Claramente sí!
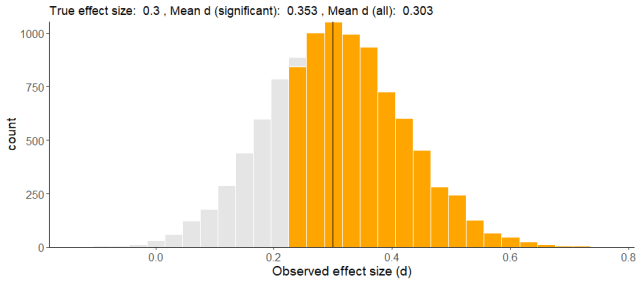
En esta figura, volvemos a representar los tamaños del efecto observados en nuestras simulaciones, sólo que ahora he marcado en amarillo los resultados significativos y que van en la dirección esperada (positivos). Como podéis comprobar, aunque el promedio de efectos observados de *todos* los estudios sea bastante correcto, cuando sólo consideramos los significativos estamos inflando enormemente nuestra estimación: nos da una d promedio de casi 1.2, que es un tamaño INMENSO. Para que os hagáis una idea, la diferencia de estatura promedio entre hombres y mujeres viene a ser de d=1, así que este efecto que hemos detectado es más grande, y a todas luces falso.

¿Cuáles son las consecuencias de tener una literatura repleta de efectos inflados? La primera ya la hemos dicho: los meta-análisis van a dejar de ser tan útiles para poner algo de orden. Ved lo que ocurre cuando aplicamos el meta-análisis a lo loco y sin pensar sobre algunos de los estudios que han sido significativos. Ahora el meta-análisis es significativo, y ofrece un tamaño del efecto exagerado, que duplica con creces el valor real. Por eso nunca os creáis un meta-análisis que no incorpore algún tipo de corrección para el sesgo de publicación. Agregar docenas, o incluso cientos, de efectos sesgados solo produce conclusiones también sesgadas. Cuidadín.
Sigamos con el escepticismo: ¿es tan grave que los tamaños del efecto estén sobrestimados? Quiero decir, leyendo esta literatura, me queda claro que el efecto existe, o sea, que usar mascarillas reduce la propagación del virus. Simplemente tengo que ignorar la magnitud del efecto, porque por culpa de la baja potencia y del sesgo de publicación, este no es fiable. ¿Podría valer así?
Bueno, pues de nuevo, no es una opción muy recomendable en la práctica. ¿Recordáis que os hablé del “análisis de potencia a priori”? En teoría, los investigadores diseñamos nuestros estudios para que tengan potencia óptima, y esto implica basarse en la literatura para tener una idea de cuál puede ser el tamaño del efecto que estoy buscando. Pero claro, si la literatura me ofrece efectos inflados, multiplicados varias veces por su tamaño real, me está condenando a diseñar sistemáticamente estudios de baja potencia, en la creencia de que las muestras pequeñas son suficientes. O sea, que la situación nos mete en un círculo vicioso: como los estudios son de baja potencia y sólo publicamos los que exageran la estimación, seguiremos haciendo estudios con muestras insuficientes.
Arreglando el mundo: potencia aceptable
Otro aspecto bueno que tienen las simulaciones es que, con ellas, es muy fácil “arreglar el mundo” y ver qué pasaría si hiciéramos las cosas bien. Ojalá en la vida real fuera tan sencillo. Vamos a ver qué ocurre cuando los estudios tienen buena potencia, muestras grandes, mediciones precisas…
Repetimos las simulaciones: de nuevo, 10.000 estudios sobre un efecto pequeño, d=0.3, pero ahora con muestras grandes, N = 300 (150 en cada grupo).

¡Cómo ha cambiado la cosa! Ahora un 75% de los estudios tienen resultados significativos, es decir, hemos incrementado la potencia al 75%, que ya empieza a ser un valor aceptable.
Bueno, y las estimaciones del tamaño del efecto, ¿habrán mejorado en precisión? Pues claro que sí: como veis, ahora el rango de valores es bastante más estrecho. No se ven muchos estudios sobrestimando groseramente el efecto, como antes:

¿Y qué pasa con el sesgo de publicación? ¿Seguirá estropeando las estimaciones? Podemos ver que ahora su efecto es bastante menos pernicioso: el efecto se “hincha” un poco cuando sólo miramos los resultados significativos, pero mucho menos que en el escenario de baja potencia que habíamos visto antes.
El motivo es que, cuando la muestra es pequeña (baja potencia), hace falta observar un efecto muy grande para que el resultado salga significativo. Así que, si solo se publican los resultados significativos, estamos basando nuestras conclusiones en esos pocos estudios con observaciones más extremas y exageradas.
Conclusiones
Si has acabado este post, enhorabuena por tu paciencia. Con un poco de suerte, habrás llegado a la conclusión de que, una vez más, tenemos que ser críticos con la literatura publicada. Generalmente, los efectos que se publican en áreas donde las muestras son poco potentes (ya sabéis, N = 15, N = 20…) están hinchados y no hay que tomarlos muy en serio, ni siquiera en un meta-análisis. Afortunadamente, hoy en día existen técnicas para estimar la magnitud de la distorsión introducida por el sesgo de publicación. Si lees un meta-análisis y no dice cómo ha tomado en cuenta la publicación selectiva de resultados… mala cosa.
¡Otro día seguimos!
