
En un post anterior os conté brevemente cómo funciona la lógica del contraste de hipótesis en estadística, intentando hacer hincapié en visualizar los conceptos. Supongo que todos acabamos entendiendo que, al final, esta forma de usar estadística se basa en tomar una decisión (“¿rechazo la hipótesis nula o no?”) mediante la interpretación del p-valor. Por supuesto, esta aproximación no está exenta de problemas y limitaciones (de hecho, hay críticas para dar y tomar), pero lo crucial es que este p-valor nos permite hacer algo muy importante: mantener a raya nuestros errores para que no aparezcan demasiado a menudo. Vamos a ver cómo lo hace, y de paso también comprenderemos por qué ese umbral arbitrario de significación que tantos dolores de cabeza nos ha provocado a los investigadores (me refiero al infame p < 0.05) 😦
Lo primero que vamos a hacer es colocarnos en el escenario de la hipótesis nula, como hicimos en el primer post de esta serie. Es decir, vamos a asumir que no hay diferencias entre dos grupos de personas, o lo que es lo mismo: que todas las diferencias que encontremos se deberán al error de muestreo.
Esta situación aparece claramente cuando planteamos un estudio basado en una hipótesis totalmente absurda, así que vamos a inventarnos una. La tipografía Comic Sans despierta un odio cruel y visceral entre muchos diseñadores gráficos, informáticos, y en general entre toda la gente de bien. Uno de los motivos es que esta tipografía genera en el lector una sensación de infantilidad (más que de diversión) que acaba siendo desagradable. “¿Qué pasa? ¿Me han tomado por un crío de 13 años?” Bueno, imaginemos que alguien plantea un estudio con un objetivo totalmente absurdo, y propone que basta ver unos minutos de dibujos animados infantiles para que, inadvertidamente, tu antipatía hacia la Comic Sans se reduzca notablemente. ¿Tiene sentido? Ninguno (1). Aun así imaginad el experimento: a la mitad de mis participantes, el grupo experimental, les hago ver un par de capítulos de Dora la Exploradora, mientras en el grupo control están viendo el telediario. Después, todos los participantes deben evaluar cuánto les gusta el mismo texto escrito en Comic Sans. Nuestra descabellada hipótesis predice que en el grupo experimental se rebajarán las evaluaciones negativas con respecto al control.
¿Es lo bastante absurdo? Sigamos. Ahora imaginemos que llevamos a cabo este estudio, y como decíamos el otro día calculamos el estadístico t para comparar las medias, obteniendo un p-valor. Este p-valor servirá para tomar una decisión: si es significativo (menor de 0.05), diremos que el tratamiento de Dora la Exploradora ha funcionado para rebajar el odio a la Comic Sans. Hemos planteado una situación absurda, una hipótesis que seguramente es falsa. Por lo tanto, probablemente la hipótesis nula es “verdadera” en este caso. ¿Qué p-valor creéis que obtendremos con mayor probabilidad? ¿Uno muy grande, no significativo, como por ejemplo p = 0.823? ¿O uno muy pequeño, significativo, como p = 0.002? Venga, os doy un minuto para contestar y luego seguís leyendo.
¿Ya lo habéis pensado?
Bien, si habéis respondido que bajo la hipótesis nula (recordemos, no hay diferencias reales en la población) el p-valor sería grande, no significativo, ¡enhorabuena! Habéis participado usando la intuición. Tendría su lógica, ¿no? Efecto nulo, p-valor no significativo; efecto grande, p-valor significativo… Pero lamentablemente esto es incorrecto.
Vaya palo. Vale, ya lo iréis comprobando: la estadística está llena de situaciones que van contra toda intuición, como nos pasaba el otro día con los intervalos de confianza. Así que en vez de dejarnos llevar por las intuiciones, vamos a hacer algo incluso más divertido. ¡Vamos a hacer simulaciones! Para ello, utilizaré el software R, como siempre.
En la siguiente imagen, he simulado nada menos que 10.000 muestras aleatorias de una población en la que no hay diferencias entre grupos (por lo tanto, en este caso la hipótesis nula está en lo cierto). Es un escenario como el de nuestro ejemplo con el estudio de la Comic Sans.
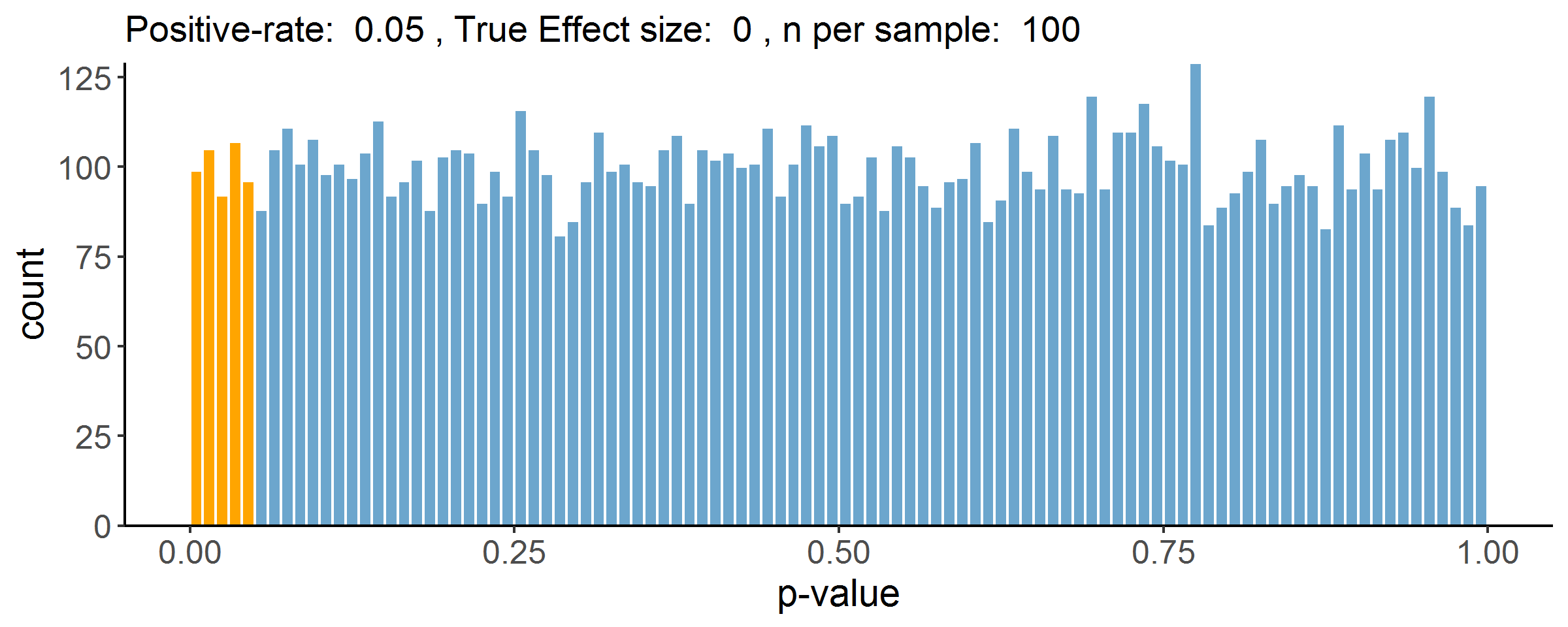
Para cada una de esas muestras he calculado su estadístico t y su p-valor correspondiente. A continuación, he representado la frecuencia de cada valor para p. Cuanto más alta es la barra, más frecuente es ese valor de p en las simulaciones. Los p-valores significativos (es decir, menores de 0.05) están resaltados en naranja. Recordemos que estamos bajo la hipótesis nula, así que ahora podremos saber si es más habitual encontrar un p-valor pequeño que uno grande, sólo mirando la altura de las barras.
¿Qué es lo que descubrimos? Que si examinamos las 10.000 muestras, no son particularmente más habituales los p-valores grandes que los pequeños. La distribución es uniforme (quiere decir que todos los valores entre 0 y 1 son igual de probables).
Pues vaya chasco, diréis: el p-valor no es nada informativo cuando la hipótesis nula es cierta. Y es verdad. Pero sí podemos usar el p-valor como herramienta de control de error.
Hay varios errores que podemos cometer en la estadística inferencial. Entre ellos tenemos el error tipo I, también llamado “falso positivo”, que consiste en afirmar que algo existe cuando no es así. Si yo proclamo que he visto un unicornio rosa entrar en mi habitación, en seguida me diréis que habrán sido mis imaginaciones o que debería irme a la cama de una vez. En nuestro ejemplo de hoy, equivaldría a decir que el tratamiento de Dora la Exploradora ha funcionado, aunque realmente no sea así. Este tipo de error es particularmente dañino en ciencia. ¡Imaginad que concluyo que un medicamento está funcionando para tratar una enfermedad grave, pero en realidad esto no es cierto! Por eso hemos decidido mantener a raya este tipo de error, el falso positivo, de forma que no ocurra muy frecuentemente. Concretamente, nos gustaría que este error sólo tuviera lugar en el 5% de las ocasiones.
Volved a mirar la figura anterior. Hemos dicho que, bajo la hipótesis nula, todos los p-valores (entre 0 y 1) son igual de probables. Los valores que están por debajo de 0.05 (los marcados en naranja) representan, por tanto, el 5% del total de p-valores posibles en esta situación (0.05 es el 5% de 1). Esto significa que, si sólo nos permitimos afirmar que un efecto existe (o sea, rechazar la hipótesis nula) cuando p < 0.05, ¡estamos efectivamente reduciendo la tasa de error tipo I al 5%! Así es como el p-valor controla los falsos positivos.
De hecho lo podemos comprobar en la propia simulación: en la parte superior os he incluido la proporción de estudios simulados que son significativos, y en este caso se acerca mucho a 0.05, justo como estaba previsto.
Y es que esta idea funciona casi siempre, en teoría. En la práctica, como quizá veamos algún día en otro post, se dan ciertas situaciones que hacen que inflemos enormemente la tasa de error tipo I hasta límites insospechados, muy por encima del 5% (ved la siguiente figura, adaptada de un trabajo de Simmons et al., 2011, y pasad miedo).

Por otro lado, la misma simulación que hemos hecho para ver cómo se distribuyen los p-valores nos puede servir para aprender otras cosas. Esto os lo cuento en el próximo post. Hasta entonces, ¡creo que hay material para pensar de sobra!
(1) Nota: ¿quién sabe? En estos locos días, a lo mejor hay alguien que ha investigado exactamente esto, con la misma premisa. ¯\_(ツ)_/¯
Referencias
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant. Psychological Science, 22(11), 1359-1366.
