
Continuamos con nuestro repaso a esas prácticas estadísticas que están tan extendidas, pero que a menudo nos llevan a cometer errores serios. Hoy me apetece abordar uno de los temas que más me saca de quicio. Ya habréis comprobado que tengo pasión por la “visualización” de los conceptos estadísticos y de los datos. Una (buena) imagen vale más que mil palabras, dicen, y yo lo suscribo sin reservas. Sin embargo, parece que hay una tradición bien instaurada en psicología, y es la de presentar los resultados en formato de tabla. Una tabla para las medias, los descriptivos, y también una para las correlaciones, los p-valores, los tamaños del efecto… Casi todos los TFGs, TFMs, tesis doctorales, y gran parte de los artículos que leo optan por representar los datos a través de tablas.

A ver cómo lo digo para no despertar las iras de los fanboys de las tablas. Las tablas tienen sus ventajas, claro. Para empezar, permiten precisión, porque puedes poner el número exacto. Pero tienen otros factores en su contra. Primero, ocupan espacio. No es raro que me encuentre tablas de dos o tres páginas en un TFG (reza para que las celdas no salgan cortadas entre páginas, creando una confusión insufrible). Segundo, especialmente si hablamos de tablas grandes, son difíciles de leer y de recordar. Por eso, si queréis un consejo de propina, os diré que, por favor, no utilicéis tablas en una presentación. Ay, esas tablas que te ocupan la diapositiva entera, con los números raquíticos y apretados, y tan rellenas de valores que te quedas confuso sin saber dónde tienes que mirar, mientras dejas de escuchar a la persona que está exponiendo… En fin.
La alternativa para los que amamos las visualizaciones es clara: hacer una buena figura. Pero aquí entra otro conflicto, y es que determinados tipos de visualización, aunque puedan trasmitir la información de forma más eficiente y atractiva que una tabla, al final acaban cayendo en una de las limitaciones clave de estas: sólo pueden representar estadísticos resumen. Es decir, en las tablas y en cierto tipo de figuras me tengo que conformar con escoger UNA pieza de información que represente a toda la muestra: la media, la mediana, el coeficiente de correlación… Esto puede ser un problema. Por eso voy a dedicar el post a convenceros de los peligros de las tablas y de otras visualizaciones basadas en estadísticos resumen. Empecemos.
Los peligros de los estadísticos resumen
Como decía antes, es muy habitual que empleemos un estadístico resumen para describir nuestros datos. Por ejemplo, para indicar que el sueldo de un grupo de empleados es bajo, calcularé la media o la mediana, y tomaré decisiones basándome en ese valor. Todo bien, todo correcto, siempre que sea consciente de que estoy obviando información relevante. En el caso del sueldo, tener una media alta no nos debe hacer olvidar que suele haber bastante desigualdad y asimetría en la distribución (muchas personas cobrando poco, pocas personas cobrando mucho), lo que hace que la media deje de ser representativa. Vamos a demostrarlo con este simple ejercicio en R que podéis repetir en casa.
Pongámonos en situación. Imaginemos que cuatro estudiantes de psicología están interesados en comprobar si la cafeína afecta la capacidad de concentración. Para ello, diseñan un estudio en el que preguntarán a los participantes cuántos cafés toman por semana (variable x), y después les pedirán que realicen una prueba de concentración, grabando la puntuación resultante (variable y). El objetivo sería calcular una correlación entre las dos variables, como vimos en un post anterior. Ahora bien, los cuatro estudiantes deciden repartirse el trabajo: cada uno de ellos reclutará una muestra de 11 participantes, siguiendo un procedimiento idéntico.
Vámonos a R para introducir los datos obtenidos por los estudiantes: recordad, cuatro estudios idénticos, con un total de 44 participantes.
#Cargo las bibliotecas importantes:
library(tidyverse)
#Y creo el conjunto de datos:
data<-data.frame(
id=seq(1:44),
x=c(10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5, 10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5, 10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5, 8, 8, 8, 8, 8, 8, 8, 19, 8, 8, 8),
y=c(8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68, 9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74, 7.46, 6.77, 12.74, 7.11, 7.81, 8.84, 6.08, 5.39, 8.15, 6.42, 5.73, 6.58, 5.76, 7.71, 8.84, 8.47, 7.04, 5.25, 12.50, 5.56, 7.91, 6.89),
dataset=c(rep("Estudiante 01", 11), rep("Estudiante 02", 11), rep("Estudiante 03", 11), rep("Estudiante 04", 11)))
Bien, con el código anterior he creado una matriz de datos (en R se conoce como “dataframe“) que contiene cuatro sets de datos distintos (uno para cada estudiante). Cada set de datos únicamente contiene los valores de dos variables, x e y (cafés semanales y puntuación de concentración, respectivamente). Ahora los estudiantes deben poner en común su trabajo, así que cada uno elabora una tabla con los estadísticos resumen, como es costumbre: medias, desviaciones típicas, coeficiente de correlación… En R (con tidyverse) lo haríamos así:
datasummary <- data %>%
mutate(x=as.numeric(x), y=as.numeric(y)) %>%
group_by(dataset) %>%
summarise(x.mean=mean(x), y.mean=mean(y), x.sd=sd(x), y.sd=sd(y), count=n(), r= round(cor.test(x,y)$estimate, 4), p= round(cor.test(x,y)$p.value, 4))
datasummary
…Y el resultado obtenido sería una tabla como esta:

WTF!! ¿Notais algo raro? Qué casualidad. ¡Los cuatro sets de datos son idénticos! Bueno, o eso parece a simple vista. Tienen la misma media, desviación típica, tamaño muestral, coeficiente de correlación, y p-valor. Tiene que ser un error.
Bueno, tal vez estemos prestando atención al lugar equivocado. Hasta ahora solo hemos examinado los estadísticos resumen, y esos claramente son idénticos en los cuatro conjuntos de datos. ¿Qué tal si dejamos a un lado la tabla y representamos los datos con un gráfico? Podría ser que, aunque la media y otros estadísticos resumen fueran idénticos entre dos grupos de datos, la distribución de los datos fuese muy distinta, así que vamos a elaborar una figura que me permita vislumbrar esas distribuciones. Por eso empezaremos con unos histogramas para ver la distribución de las dos variables:
histxy<-
data %>%
pivot_longer(c(x,y), names_to = "variable", values_to = "value") %>%
ggplot(aes(x=value, fill=variable))+
geom_histogram(bins = 10, color="gray90")+
scale_fill_manual(values = c("steelblue", "tomato3"))+
facet_grid(variable~dataset)+
theme_bw()
histxy

Ya tenemos la primera pista que nos permite descubrir que los cuatro sets de datos NO son idénticos, a pesar de tener exactamente los mismos estadísticos resumen: media, desviación típica, n, correlación y p-valor. De hecho, las distribuciones de las dos variables x e y son completamente diferentes de un set de datos a otro. Por ejemplo, mirad la fila de arriba, que contiene los histogramas para la variable y: en la muestra del Estudiante 4, parece que 10 participantes han afirmado tomar 8 cafés por semana, y un solo participante dice tomarse un número mucho mayor, 19. Es una distribución un tanto extrema, con solo dos valores, y diferente a la obtenida por los otros estudiantes.
He aquí un problema grave de los estadísticos resumen: nos dicen poco acerca de nuestros datos en concreto, ya que hay una variedad inmensa de conjuntos de datos que tienen idéntica media, desviación típica, n… y que por lo tanto son indistinguibles si miramos únicamente estas medidas resumen.
¿Y qué hay de los coeficientes de correlación? ¿Cómo es posible que estos cuatro sets de datos tengan la misma correlación entre las dos variables? Vamos a examinar este asunto a través de un scatter plot o gráfico de dispersión, que nos indicará cómo se relacionan las dos variables entre sí:
scatterplots<-
data %>%
ggplot(aes(x, y))+
geom_point(size=2, color="orange")+
geom_smooth(method = "lm", se=FALSE, color="black")+
scale_x_continuous(limits = c(0, 20))+
facet_grid(~dataset)+
theme_bw()
scatterplots
El resultado de este código es el siguiente gráfico:

Oh, vaya, parece que no damos una: cada conjunto de datos, a pesar de tener exactamente el mismo coeficiente de correlación (y su correspondiente p-valor), muestra una relación entre las variables completamente distinta:
- En el caso del Estudiante 1, la figura no tiene mal aspecto, los datos se distribuyen con cierta aleatoriedad, pero mostrando una tendencia ascendente clara, y de ahí el coeficiente de correlación positivo y significativo. Cuanta más cafeína (x), mejor rendimiento (y).
- El Estudiante 2 ha obtenido unos datos que claramente se distribuyen de forma no lineal, sino cuadrática: ¿veis cómo están dispuestos formando una curva? Esto nos sugiere que las dosis intermedias de cafeína mejoran la concentración, pero que una dosis muy alta reduce esta capacidad (una especie de “u invertida”).
- El caso del Estudiante 3 nos recuerda lo comentado en el post sobre los outliers. La línea de ajuste está afectada por una única observación que tiene una puntuación de concentración particularmente elevada. Si no estuviera ese caso concreto, la línea estaría menos inclinada y por lo tanto el coeficiente sería más pequeño, quizá no significativo.
- El Estudiante 4 ha tenido muy mala suerte. Todos los participantes han coincidido en la misma cantidad de cafés semanales (ocho), salvo por uno, que se toma la friolera de 19. En este caso, la correlación observada es en realidad un artefacto producido por esta observación un tanto anómala. Si la excluyésemos, ni siquiera podríamos calcular un coeficiente de correlación, puesto que la variable x en este set de datos sería una constante.
Bien, creo que ahora se ilustra más claramente el problema. Cuatro sets de datos que cuentan cuatro historias totalmente diferentes. En algunas de las historias, la relación encontrada parece un artefacto, en otras realmente existe, pero es no lineal… Pero los cuatro conjuntos de datos comparten una tabla con medidas resumen idénticas. Si no nos hubiéramos molestado en representar los gráficos anteriores, tendríamos la conclusión (incorrecta) de que los resultados de los cuatro estudiantes son equivalentes.
Este set de cuatro conjuntos de datos es ya famoso, se conoce como “cuarteto de Anscombe“, y se emplea para ilustrar justo lo que acabo de decir, que hay que desconfiar de los estadísticos resumen. Así que, moraleja: No te conformes con hacer una tabla con los estadísticos resumen. Haz un buen gráfico. Y como lector, exígelo. No cuesta nada.
Por cierto, si el cuarteto de Anscombe os parece intrigante, que sepáis que la cosa se puede complicar mucho, mucho más. Os presento a un descendiente moderno del cuarteto de Anscombre, conocido como “Datasaurus” (Smith, 2017). Como véis en el gif, podemos tener datos con casi cualquier distribución y tipo de relación, y no cambiar apenas los estadísticos resumen:

Gráficos de barras: la opción simple pero engañosa
Aunque creo que el punto ya se ha entendido bien, voy a continuar un poco más para demostrar que, en realidad, el problema no es inherente a las tablas, sino al uso de los estadísticos resumen, que solo dan información parcial. Efectivamente, hay tipos de gráficos muy extendidos que se basan también en medidas resumen, y por lo tanto tienen el mismo problema que hemos comentado. Un ejemplo habitual son los gráficos de barras para expresar promedios u otros estadísticos de centralidad. Vamos a comprobarlo:
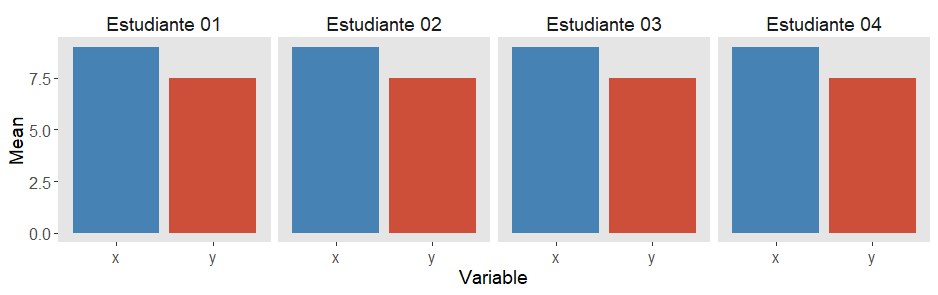
Como ya habíamos comprobado previamente, los cuatro sets de datos comparten idénticas medias para las variables x e y. Por eso este tipo de representación gráfica no nos ayuda precisamente a descubrir la historia real detrás de cada conjunto de datos, haciéndonos creer que son equivalentes. Los gráficos de barras no nos muestran nada de las distribuciones de los datos. (Son, sin embargo, buenos y sencillos de entender para transmitir información de proporciones).
Dado que los gráficos de barras son prácticamente omnipresentes en las publicaciones científicas, un grupo de jóvenes investigadores lanzó hace unos años una campaña de crowdfunding llamada “#barbarplots“, dirigida a desterrar este tipo de gráficos para la mayoría de las aplicaciones habituales. Aquí podéis ver su video promocional.
Otras alternativas gráficas
Os estaréis preguntando: si no debo utilizar tablas ni gráficos de barras, ¿qué otras formas tengo de representar mis resultados? Voy a mencionar unas cuantas alternativas, pero mejor ved alguno de los papers donde se discuten los motivos, como Weissgerber et al. (2015).
Boxplots y Violin plots
Los gráficos de caja (boxplots) que comentamos en un post anterior son una buena forma de visualizar las distribuciones. Apliquémoslo a los datos del cuarteto de Anscombe:
boxplots<-
data %>%
pivot_longer(c(x,y), names_to = "variable", values_to = "value") %>%
ggplot(aes(x=dataset, y=value, fill=variable))+
geom_boxplot()+
scale_fill_manual(values = c("steelblue", "tomato3"))+
theme_bw()
boxplots
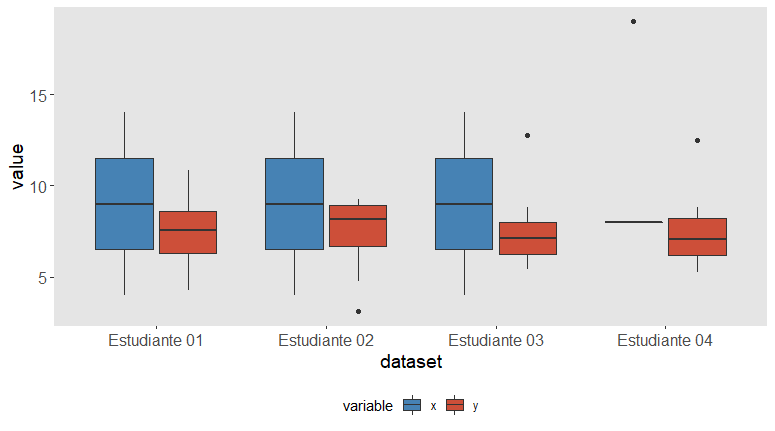
Aunque este gráfico sería en todo caso un complemento a los gráficos de dispersión de más arriba, ya nos sirve para detectar diferencias claras entre las distribuciones: el outlier en la variable y del Estudiante 3, la distribución totalmente descuajaringada en la variable x del Estudiante 4…
El problema habitual con los gráficos de caja es que requieren un poco de entrenamiento para poder interpretarlos (así que sí, es normal que no los entiendas bien a la primera). Afortunadamente hay otras alternativas. Con sólo cambiar una línea de código, podemos pasar de los boxplots a los “violin plots“, o incluso combinar ambos, como en la siguiente figura:
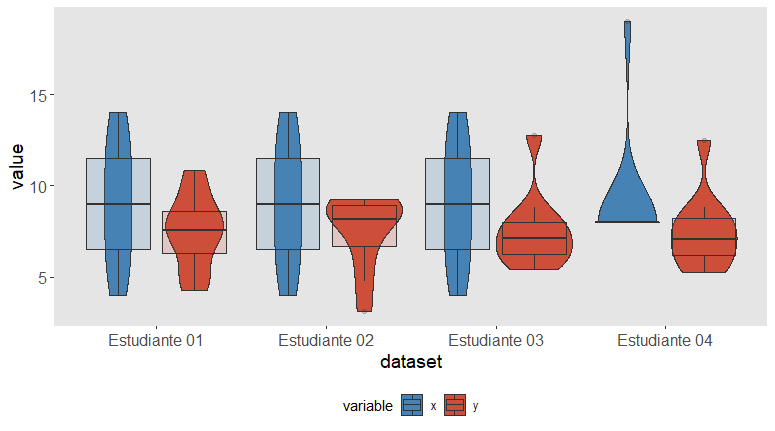
La gracia del componente “violín” de este gráfico es que transmite la forma de la distribución de una manera bastante intuitiva que no requiere un ojo entrenado. Esa forma curvada con aspecto de “vasija” es en realidad una aproximación de la densidad de la distribución: allí donde se hace más estrecha hay menos datos. Así podemos detectar asimetrías, outliers…
Dotplots
¿Le damos otra vuelta de tuerca a los violin plots? En vez de dibujar las densidades aproximadas, cuando el número de datos no es grande podemos representar cada punto de datos individual. Es justo lo que hacen los siguientes dotplots.

Ahora es mucho más fácil darse cuenta de que, por ejemplo, la variable x en el set del Estudiante 4 no tiene más que dos valores.
Otra utilidad interesante de este tipo de gráficos es que nos permite descubrir posibles problemas como por ejemplo la comparación de grupos con tamaños muy diferentes, presencia de outliers, varianzas no homogéneas, etc. Os pongo como muestra esta figura de Weissgerber et al (2015), en la que el mismo gráfico de barras puede estar ocultando sets de datos muy diferentes:
Combinando visualizaciones
En general estamos tan acostumbrados a los estadísticos resumen que, incluso si empleamos este tipo de visualizaciones más modernas vamos a tener que combinarlas con algún tipo de representación de la media, de la mediana… Además suelen ser estos estadísticos resumen los que empleamos en la inferencia, así que necesitamos verlos de alguna manera en el gráfico. Suerte que hoy en día no tenemos que limitarnos a un tipo de visualización, sino que podemos mezclarlas. Por ejemplo, podemos usar los márgenes de un gráfico de dispersión para dibujar los histogramas:

A mí me gusta particularmente la idea de dibujar los datos reales por encima del gráfico de barras, añadiendo un pequeño desplazamiento aleatorio en el eje horizontal (jitter):

Esta figura combina lo mejor de los dos mundos: tenemos las medias de las dos variables, pero también una idea aproximada de la distribución, y de la n de cada variable…
Conclusiones
Terminamos ya este post que ha tratado sobre uno de los problemas clásicos a la hora de transmitir la información estadística: confiar demasiado en los estadísticos resumen (media, mediana…). Hemos comprobado cómo los estadísticos resumen pueden ser engañosos, lo cual convierte a las tablas en una opción un tanto ineficiente para comunicar resultados. Pero este problema se extiende a otro tipo de visualizaciones que también confían en los mismos estadísticos, como los gráficos de barras.
Así que si quieres un consejo para tu próximo trabajo de investigación, es el siguiente: merece la pena buscar una buena manera de visualizar los datos y transmitir toda la información relevante. No hurtes al lector la información de las distribuciones, ni te fíes de las “tradiciones”. ¡No es obligatorio hacer una tabla, o un gráfico de tarta! Arriesga, que ahora el software te lo pone fácil.
Por cierto, si alguien lo pregunta: todas las figuras las he elaborado en R con ayuda del paquete ggplot2 (bueno, en general me he hecho fan de las mecánicas tidyverse). Pero hay aplicaciones gratuitas que hacen figuras más que decentes, y si no las conocéis preguntadme en los comentarios. ¡Hasta la próxima entrega!
Referencias
- Smith, D. (2017). The Datasaurus Dozen. Revolution Analytics. https://blog.revolutionanalytics.com/2017/05/the-datasaurus-dozen.html
- Weissgerber, T.L., Milic, N.M., Winham, S.J., & Garovic, V.D. (2015). Beyond Bar and Line Graphs: Time for a New Data Presentation Paradigm. PLoS Biology, 13(4), e1002128.

Fernando, muchísimas gracias por tu post y por la detallada explicación.
Ya que lo indicas al final, a mí sí me interesaría una lista o descripción de herramientas adicionales para representar visualmente información. Por cierto, ¿hay alguna de ellas que pueda combinarse con SPSS?
Muchas gracias.
LikeLike
Hola,
En este post he usado R con el paquete tidyverse.
Si no quieres usar R, hay opciones muy dignas como Jamovi (si vienes de SPSS lo encontrarás muy cómodo).
Otra opción, si no quieres instalarte nada, es statscloud (análisis en la nube, desde el navegador).
LikeLike