Vamos a aprovechar el verano para repasar algunos conceptos clave de estadística, que sé que algunos/as ya estáis dándole al temario del PIR, o bien simplemente os va la marcha como a mí y no os importa leer de estos temas desde la playa. Esta vez vamos a avanzar un poco con respecto al último post, para tratar otro de esos temas que ojalá me hubieran explicado en clase cuando empecé a estudiar estadística: el tamaño del efecto.
¿Cómo de bien funciona un tratamiento?
Comenzaremos con un ejemplo para ponernos en situación. Imaginad que he descubierto un tónico crecepelo y quiero ponerlo a prueba. ¡Yo estoy convencido de que funciona! La pregunta es: sí, pero ¿cómo de bien funciona?
Para saberlo, como de costumbre, haremos un experimento. En este caso, basta con reclutar una muestra de pacientes con calvicie (¡ay!), y asignarlos al azar a uno de dos grupos: en el grupo Tratamiento, beberán mi tónico milagroso, mientras que en el grupo Control tomarán un placebo (un jarabe sin propiedades especiales más allá de su alegre sabor a fresa). Al cabo de un mes, examinaré la calvorota de todos los participantes, contando el número de cabellos nuevos que han crecido en este periodo. En resumen, obtendré dos cantidades: el número promedio de cabellos nuevos en el grupo Tratamiento, y el número promedio de cabellos en el grupo Control. Si mi tónico crecepelo funciona, la media del grupo Tratamiento será significativamente mayor que la del grupo Control. ¿Hasta aquí bien?
Imaginemos que hago mi estudio y el resultado es el siguiente: En el grupo Tratamiento, de media han crecido unos 4000 cabellos nuevos por cada participante, mientras que en el grupo Control apenas llegamos a un pírrico promedio de 2 cabellos nuevos. Esta diferencia es evidentemente significativa (si calculamos el p-valor, será inferior a 0.05).
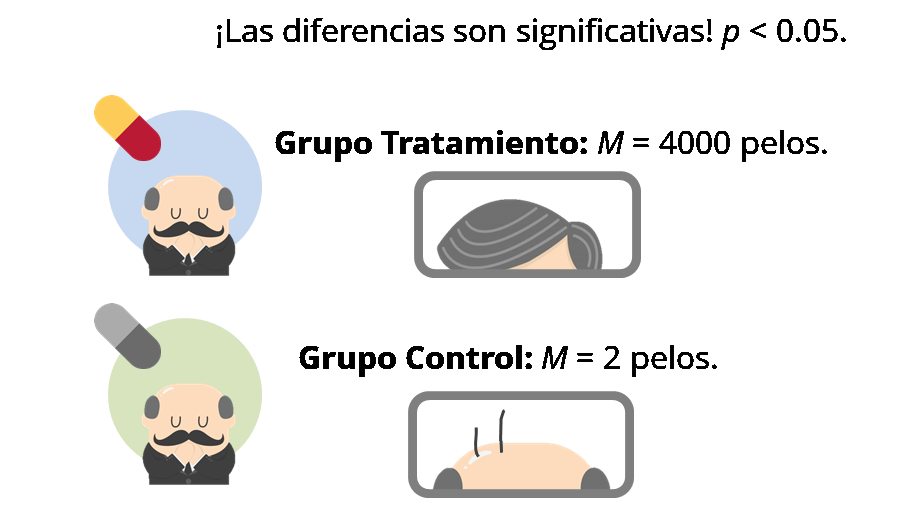
Está claro que, si obtuviera un resultado como este, ya me estaría apareciendo el símbolo del dólar en las pupilas y me habría puesto a meditar sobre si prefiero comprarme un yate con 50 metros de eslora o una mansión de lujo, porque ciertamente el tónico está funcionando de maravilla. Pero antes de dejarnos llevar por la fantasía, pensemos en otra situación bastante diferente que podría haberme encontrado:
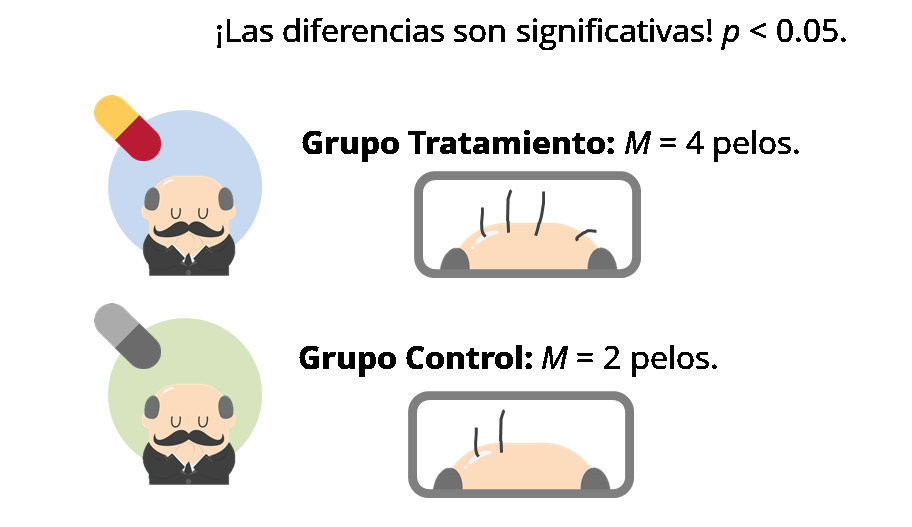
Imaginad que el resultado hubiera sido que, en promedio, los cabellos nuevos en el grupo Tratamiento fueran 4, frente a sólo 2 en el grupo Control. Esta diferencia es significativa (p < 0.05), de lo cual puedo concluir que efectivamente el tónico funciona. Por otro lado, la ventaja de utilizarlo es claramente insuficiente. Sí, estamos duplicando el número de cabellos con respecto al control, pero no creo que nadie en su sano juicio vaya a pagar un pastizal por esos dos cabellos extra en la calva. Habrá que cambiar de proyecto, que este no parece muy provechoso.
¿Qué enseñanza extraemos de esta historia? En primer lugar, que no basta con preguntarse si un tratamiento funciona o no, sino que también hay que plantearse cómo de bien funciona. Imaginad que el tónico tuviera efectos adversos, o fuera muy caro: merecería la pena tal vez si a cambio nos proporciona una mata de pelo como la de El Puma, pero claramente nadie lo utilizaría si la ventaja fuese casi inapreciable. O si queréis llevaros el ejemplo a la psicología: ¿deberían los pacientes acudir a un terapeuta que, en promedio, sólo mejora sus niveles de ansiedad el equivalente a un punto en un test como el STAI?
En términos estadísticos, el p-valor nos dice si el tratamiento funciona o no, es decir, si esa diferencia entre los dos grupos es lo bastante grande como para que sea muy improbable observarla por puro azar. Por otro lado, la diferencia entre las medias de los dos grupos (en este caso, 4000 – 2 = 3998 cabellos nuevos, o bien 4 -2 = 2 cabellos nuevos) es lo que vamos a llamar “tamaño del efecto”, una medida de cómo de bien funciona un tratamiento, es decir, una cuantificación aproximada de la diferencia entre las poblaciones. Sobre este último concepto vamos a profundizar hoy.
Visualizando el tamaño del efecto
Para entender mejor qué es el tamaño del efecto, al menos en un diseño de este tipo (dos grupos en los que queremos comprar las medias), vamos a jugar con unas simulaciones en R. Por si acaso, si alguien prefiere empezar desde el principio, la lógica de todo el análisis se explica en este post previo.
mean.G1 <- 55 #media en el grupo 1
mean.G2 <- 50 #media en el grupo 2
sd <- 10 #desviación típica (vamos a asumir que es idéntica en ambos grupos)
#Dibujamos las dos muestras:
plot(x=seq(1: 100),
dnorm(seq(1:100), mean.G1, sd),
type="l", xlab = "", ylab="", col="red",
main=paste("Diferencia: ", mean.G1-mean.G2, ", SD = ", sd))
lines(x=seq(1: 100),
dnorm(seq(1:100), mean.G2, sd),
type="l", col="blue")
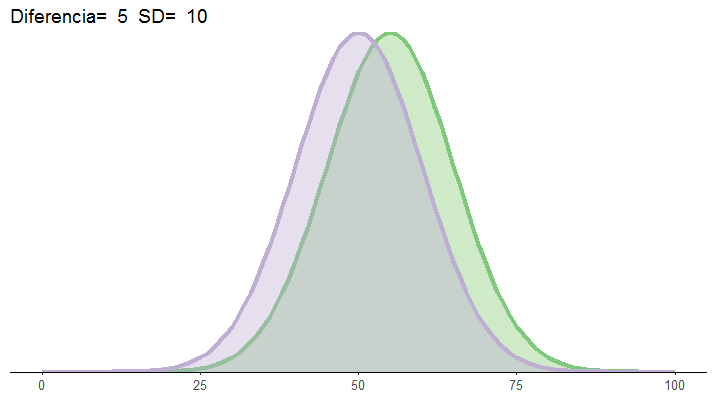
Como siempre, podéis probar y cambiar el código en esta web sin necesidad de instalar R ni nada (https://rextester.com/l/r_online_compiler). Este trozo de código dibuja las distribuciones normales con los parámetros (media y desviación típica) de las dos poblaciones de interés: quienes toman el tónico crecepelo y quienes toman el jarabe placebo. En este caso, hemos supuesto que las dos poblaciones van a diferir de forma que en el grupo Tratamiento han crecido, de media, 55 pelos nuevos, mientras que en el grupo Control han crecido 50. Esta diferencia puede producir un resultado estadísticamente significativo siempre que la muestra empleada sea suficiente. Podéis comprobarlo, por ejemplo, para una N de 30 participantes por grupo:
t.test(rnorm(30, mean.G1, sd), rnorm(20, mean.G2, sd))
Tened en cuenta que este resultado no va a ser significativo siempre, debido a que estamos generando una muestra aleatoria cada vez que ejecutamos el código y por lo tanto estamos a merced del error de muestreo, como vimos en post anteriores (probad a ejecutar esta misma línea cuatro o cinco veces, y ved cómo cambia el p-valor). Como estaba diciendo, la manera de “asegurar el tiro” y garantizar que obtendremos un resultado significativo en la mayoría de las ocasiones es tener muestras grandes. En cualquier caso, está claro que hay una diferencia entre las dos poblaciones. En concreto, la diferencia es de 55-50=5 unidades (en este caso, 5 cabellos). Las pruebas estadísticas, con suficiente muestra, pueden detectar esta diferencia, como acabamos de comprobar. Ahora bien, ¿es una diferencia grande o pequeña? Lo sabremos al examinar la figura. Como podéis ver, hay un alto grado de solapamiento entre las dos poblaciones:
Repetid ahora la simulación, cambiando sólo los valores de partida. Vamos a imaginar que la diferencia entre las poblaciones es más grande, por ejemplo, 70-50=20 cabellos nuevos. Sería un crecepelo mucho mejor que el del caso anterior. O podéis probar lo contrario, una diferencia más pequeña, como 51-50=1 cabello de diferencia. La conclusión evidente es que la diferencia de medias afecta al grado de solapamiento entre las distribuciones. Cuanto más parecidas son las medias, más cercanas las distribuciones y mayor solapamiento entre ellas:

Dijimos el otro día que una de las maneras de luchar contra el error de muestreo es tener medidas precisas. Una medida precisa es aquella que, entre otras propiedades, va a producir valores similares si medimos el mismo objeto varias veces. La manera de introducir este factor en nuestra simulación es cambiar el parámetro de desviación típica (“sd”). Cuando la desviación típica es pequeña, la distribución “adelgaza”, y ocupa menos espacio, porque casi todos sus valores se aglutinan muy cerca de la media. Cuando la desviación típica es grande, por el contrario, los valores están más dispersos. Probad con valores grandes o pequeños para el parámetro “sd” de las simulaciones, y ved cómo esto también afecta al solapamiento de las distribuciones:
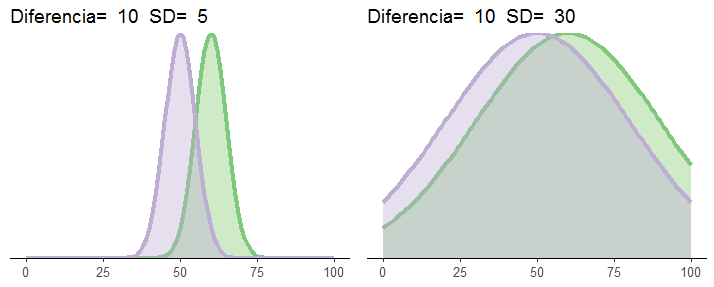
En esta última imagen, por ejemplo, tenemos exactamente la misma diferencia de medias (60-50=10 cabellos), pero la desviación típica de las distribuciones hace que varíe el grado de solapamiento.
¿Y qué importa el grado de solapamiento entre las poblaciones? Bueno, pues es una manera de “imaginar visualmente” el tamaño del efecto: las distribuciones muy solapadas están indicando un tamaño del efecto más pequeño. Intuitivamente, esto puede entenderse como que las dos poblaciones cuyas diferencias quiero investigar son, en esencia, muy similares.
Una medida estándar: la d de Cohen
Hasta ahora, cuando hablamos de diferencias de medias, las estamos expresando en términos brutos, en las unidades de medida (por ejemplo, número de cabellos nuevos). Esto puede a veces no ser lo más conveniente. ¿Y si quiero establecer algún tipo de comparación entre estudios que utilizan medidas diferentes? Por ejemplo, un estudio puede medir el éxito de una dieta en términos de peso perdido, y otro en términos de reducción de volumen de cintura. Lógicamente cada uno va a expresar la diferencia de medias en sus propias unidades, lo que me impide compararlas directamente. Regla básica en razonamiento estadístico: no se pueden comparar cosas que no son comparables. ¿Tiene sentido decir que 5 kilogramos es mayor que tres centímetros? ¿A que no?
Por suerte, en estadística tenemos nuestros “truquillos” para permitir estas comparaciones, y generalmente consisten en alguna forma de estandarización (la diferencia entre dos valores de tendencia central se divide por su dispersión). Así, cuando hablamos de tamaño del efecto, en vez de hablar de diferencias brutas en las unidades de medida (número de cabellos nuevos, número de kilos perdidos, centímetros de reducción de cintura…), habitualmente usamos una medida estandarizada. En este caso, la más famosa sería la d de Cohen, que se calcula así:
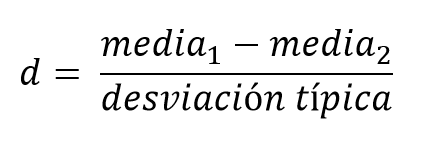
En realidad, hay que andarse con ojo porque hay varias fórmulas ligeramente distintas para hacer este cálculo, pero esta sería la más sencilla. Si la aplicamos a cualquiera de nuestros ejemplos anteriores, podemos calcular la diferencia en unidades estándar entre las dos poblaciones. Por ejemplo, en el primer caso, la diferencia de medias era 55-50=5 cabellos, y dado que la desviación típica era de 10, nos dejaba una d = 0.50.
Cuando enseño estadística en clase, suelo evitar entrar de lleno con las ecuaciones y las fórmulas, optando en su lugar por las visualizaciones. Sin embargo, una vez que hemos intuido el concepto visualmente, la fórmula nos puede ser de ayuda para asentarlo. Como podéis comprobar, la d de Cohen es sensible a las propiedades que habíamos mencionado en las simulaciones: en primer lugar, la distancia entre las distribuciones es la diferencia de medias, y está en el numerador de la fórmula, de modo que a mayor diferencia de medias, mayor d. En segundo lugar, la dispersión (que hemos expresado como la desviación típica) de la distribución está en el denominador de la fórmula, lo que indica que a mayor desviación típica, menor el valor del tamaño del efecto, d. En otras palabras, d está expresando el grado de solapamiento entre las distribuciones. Esto era fácil de extraer de la fórmula, pero es todavía más sencillo entender ese paso después de haber visto las simulaciones previas.
¿Es la d de Cohen el único estadístico para el tamaño del efecto? Evidentemente no, aquí estamos usando el ejemplo más sencillo que se me ocurre, pero no siempre nos va a interesar comparar dos medias de dos grupos. A veces el tamaño del efecto se va a expresar como el grado de asociación entre dos variables numéricas (r de Pearson), o de porcentaje de varianza que predice una variable predictora (R2)… De momento nos quedamos con la d de Cohen, sabiendo que es sólo un caso.
Ahora podéis volver a las simulaciones anteriores y comprobar cómo el tamaño del efecto, medido con la d de Cohen, es efectivamente una expresión del grado de solapamiento entre las distribuciones. A más solapamiento, menor la d de Cohen. Para calcularla en cada caso, usad este código que incluye una línea con el cómputo necesario:
mean.G1 <- 55 #media en el grupo 1
mean.G2 <- 50 #media en el grupo 2
sd <- 10 #desviación típica (vamos a asumir que es idéntica en ambos grupos)
d <- (mean.G1-mean.G2)/sd #d de Cohen para la población con los parámetros indicados.
#Dibujamos las dos muestras:
plot(x=seq(1: 100),
dnorm(seq(1:100), mean.G1, sd),
type="l", xlab = "", ylab="", col="red",
main=paste("Diferencia: ", mean.G1-mean.G2, ", SD = ", sd, “, d: ”, d))
lines(x=seq(1: 100),
dnorm(seq(1:100), mean.G2, sd),
type="l", col="blue")
Para comprender mejor este tipo de conceptos, nada como simularlos de primera mano y ver cómo cambian dinámicamente. En este sentido, os puede ayudar esta app online que es una maravilla: https://rpsychologist.com/d3/cohend/
Un aspecto en el que conviene fijarse al jugar con estas visualizaciones: incluso cuando el efecto poblacional es real, y podría ser significativo en un estudio, siempre hay un grado relativamente grande de solapamiento entre las distribuciones. Si, por ejemplo, usáis la app online para examinar un efecto con tamaño d=0.10, veréis que las dos poblaciones van a ser casi idénticas.
Hasta ahora, estamos hablando del tamaño del efecto en la población, pero recordad que generalmente los parámetros de la población son desconocidos (salvo en este caso, porque los estamos simulando). En su lugar, lo que tenemos son estadísticos calculados a partir de la muestra que sirven para estimar estos parámetros, y que están como siempre sujetos al error de muestreo. Esto quiere decir que, si hacemos un estudio, podemos calcular el tamaño del efecto muestral con la d de Cohen usando la misma fórmula que tenéis arriba. En este caso sería el tamaño del efecto “observado”, que es el que generalmente nos cuentan en los artículos. Lo que ocurre es que, como pasa con todos los estadísticos obtenidos a partir de una muestra, si repetimos el estudio el resultado va a ser diferente. Lo mismo que las medias, las desviaciones típicas y los p-valores. Otro día volveremos sobre este punto.
Efectos grandes, efectos pequeños
¿Cuál es la ventaja de tener un estadístico estandarizado como la d de Cohen? En primer lugar, como decía antes, nos permite comparar entre estudios con medidas diferentes. Así, si un estudio mide el éxito de la dieta en términos de kilos perdidos y me da una d = 0.3, y otro estudio lo mide en términos de centímetros de cintura, y me da una d = 0.10, ya puedo afirmar que, en principio, parece que el primer estudio indica un efecto más grande que el segundo, independientemente de las unidades de medida.
La otra ventaja de las medidas estandarizadas es que nos permiten elaborar guías o pautas para saber cuándo un efecto es “grande”. Bueno, aunque esto requiere mucha cautela y nunca debe tomarse al pie de la letra. Orientativamente, en psicología decimos que un efecto es “pequeño” si d = 0.20, “mediano” si d = 0.50, y “grande” si d = 0.80. En ocasiones vais a ver papers y artículos donde indican tamaños del efecto inmensos, como d = 3.20, ó d = 5.79. Por lo general, recomiendo cautela al interpretarlos, ya que un efecto tan gigantesco estará seguramente sobrestimado. Pensad que la diferencia de estatura entre hombres y mujeres, que es uno de los efectos más grandes que podemos observar, tiene una d de “sólo” 1.20. Cuesta pensar que un efecto psicológico, que generalmente son mucho más sutiles, pueda tener un tamaño dos o tres veces mayor.
Por aquí lo vamos a dejar de momento, aunque queda un paso esencial, que es el de unir los conceptos de tamaño del efecto y de potencia (que vimos en el anterior post), ya que en realidad están íntimamente ligados. Esto lo dejamos para el próximo día. Seguid con vuestros chapuzones veraniegos mientras tanto.

Buen artículo con trabajo empírico puro y duro
LikeLike
Muchas gracias por tus artículos, me han ayudado muchísimo. Saludos desde Chile
LikeLike