
Después de dos posts suavecitos, sin meteros mucha caña, creo que ya podemos empezar a tratar temas más específicos (y más prácticos). Si habéis hecho alguna investigación empírica con recogida de datos, seguro que la historia de hoy os va a sonar muy, muy familiar. Acabas tu trabajo de campo y te dispones a hacer los análisis. Los datos parecen ir en la línea que habías previsto… hasta que te fijas bien y te das cuenta de que hay dos puñeteros participantes que hacen justo lo contrario de lo que tendrían que hacer, y que te estropean el resultado del estudio entero. ¡Malditos!

Esas dos o tres observaciones que se salen de la escala y que nos atormentan se conocen popularmente como “outliers” (MacClelland, 2000). Se trata de casos con valores muy extremos, diferentes al resto de su grupo, que pueden dar al traste con tu estimación. Estas observaciones pueden ser fruto de un error al introducir los datos (por ejemplo, si me baila el dedo y puntúo un examen de 0 a 10 con un “90”, en vez de un 9), pero también pueden ser valores perfectamente válidos, sólo que muy infrecuentes. Nuestro objetivo es detectar los outliers, evaluar el riesgo de que malogren el estudio, y tomar alguna decisión al respecto. ¡Ya veremos cuál!
[AVISO para lectores ya curtidos con la estadística: en este post sólo vamos a hablar de outliers univariados, que son el caso más sencillo. Hay otras técnicas de detección de outliers multivariados, pero no las vamos a tratar hoy]
Los outliers te destrozan la estimación (pero pueden ser interesantes)
Vamos a comenzar intentando comprender por qué los outliers son tan peligrosos a través de un ejemplo sencillo. Supongamos que me interesa averiguar cuál es el tamaño promedio de los perros de una determinada población. Esta información podría ser interesante a la hora de adoptar determinadas políticas, como por ejemplo el tamaño que tienen que tener los parques y lugares comunes. Entonces, contrato a un ayudante para que se dedique a visitar algunas viviendas de la ciudad, cargando con una báscula para pesar a los perros que se vaya encontrando.
Nuestro ayudante se percata en seguida de que, al menos en las afueras de este pueblo, donde las casas son grandes y están aisladas, a la gente le gustan los perros enormes que sirvan como guardián: ya lleva encuestados dos San Bernardos, unos cuantos mastines, varios pastores alemanes… En una primera muestra de unos 10 animales, el peso medio ha sido de nada menos que ¡82.54 kg! Podéis ver el gráfico resultante en el panel superior de la siguiente figura.
Sin embargo, al tercer día, nuestro aventurero investigador se adentra en las callejuelas del centro y da con una vivienda de pequeñas dimensiones, en la que una señora mayor cuidaba de un (bastante nervioso) perrito chihuahua, de solamente 1.5kg de peso. Este perrillo tiene un peso sensiblemente inferior al de todos los animales previamente encuestados, y por lo tanto lo podemos considerar un caso extremo, un outlier. Al calcular el nuevo promedio después de introducir este dato, observamos que la media ha bajado notablemente (hasta 73.53kg).

La figura anterior es una muestra del efecto que tienen los outliers sobre la estimación del promedio: con sólo añadir esa observación, la media se ha transformado radicalmente. Por otro lado, también podemos comprobar que otros estadísticos son más robustos a los outliers: en el gráfico tenéis representada la mediana, que apenas se ve afectada.
Este ejemplo ilustra también una de esas ocasiones en las que los outliers nos dan información valiosa. En este caso, nos está indicando que medir el peso de los perros, así en general, puede ser poco informativo, y que deberíamos tener en cuenta parámetros como la raza, o el lugar de residencia. No es lo mismo un dogo alemán que un caniche. No tienen el mismo tamaño los perros que viven en fincas grandes que los que viven en un apartamento en la ciudad. Aunque solemos hablar de los outliers en términos negativos porque pueden dar al traste con tus predicciones (no en vano, yo lo aprendí casi todo con un paper que se titulaba “nasty data“), lo cierto es que también pueden ser una fuente de conocimiento y descubrimiento. Hay programas de investigación enteros que se basan en la observación de individuos excepcionales.
Los outliers distorsionan tus resultados
Aprovechando que el otro día estuvimos hablando de las correlaciones, vamos a poner otro ejemplo del peligro de los outliers, quizá más práctico para quien esté trabajando con datos reales. Imaginad que estamos haciendo un estudio sobre el efecto de la cafeína en el rendimiento académico. Así que hemos reunido una muestra de estudiantes a los que hemos preguntado cuántos cafés toman durante la semana, y hemos calculado la correlación de ese número de cafés con la nota de un examen de matemáticas. …Pero resulta que el examen era bastante difícil (casi todo el mundo ha suspendido). Sin embargo, hay una persona que ha sacado un 10. Al ser una nota muy distinta a la del resto de la clase, podemos considerarla una observación extrema, o un outlier.
A la izquierda, podemos ver que justo esa persona que ha sacado un 10 es también particularmente aficionada a los cafés, puntuando por encima del resto (he marcado el punto en rojo). La correlación entre las dos variables es positiva, p < 0.05. ¡BUM! Ya tenemos resultado. Bueno, pero, ¿qué habría pasado si justo esa persona que ha sacado el 10 no fuera tan, tan, extremadamente aficionada a tomar cafés? El resultado lo tenéis a la derecha: la correlación desaparece. Porque esa correlación era, en realidad, un artefacto producido por un único caso extremo.

Moraleja: siempre que leas un artículo donde aparezcan coeficientes de correlación, ¡exige una figura con los datos! A veces hay una o dos observaciones que explican el resultado.
Casos demasiado influyentes
Este último ejemplo nos lleva al siguiente concepto que debemos conocer: el de influencia. Los parámetros de nuestro modelo estadístico (en este caso, sería el coeficiente de correlación) se estiman a partir de los datos. Por lo tanto, cada dato está “contribuyendo” con un poco de información al modelo. Pero puede ocurrir que unos casos tengan más peso que otros en la estimación. A ese peso lo llamamos “influencia“, y suele ocurrir que los outliers sean también casos más influyentes que el resto. La manera de darnos cuenta es eliminar ese dato de la muestra y observar cómo cambia el modelo. En la siguiente figura, tenemos los mismos datos que en los ejemplos anteriores, pero sin el outlier, y vemos que la recta de ajuste se queda plana (no detectamos ninguna correlación significativa).

De esto se deduce que, en principio, deberíamos protegernos frente a aquellos datos que tienen demasiada influencia en el modelo, porque nos van a distorsionar el resultado.
¿Cómo cuantificar la influencia de tus datos? Una posibilidad es calcular unos estadísticos llamados “las distancias de Cook” (la mayoría de los paquetes de software lo pueden hacer con un par de clics). Básicamente, estas distancias se obtienen eliminando cada dato uno por uno, y registrando cuánto cambian los parámetros del modelo (en este caso, la inclinación de la recta). Los casos con valores de influencia más altos (medidos con este procedimiento) generalmente están introduciendo una distorsión en los resultados, así que podríamos plantearnos hacer algo al respecto.
¿Cómo detectar los outliers?
La pregunta del millón: ¿cómo de “anómalo” o “extremo” tiene que ser un dato para que yo decida que tengo que tomar medidas? Existen varias técnicas, y por regla general es mejor combinar un par de ellas para asegurarnos de que convergen en la misma conclusión. Por un lado tenemos los métodos gráficos, y por el otro los criterios estadísticos (Aguinis, 2013).
En cuanto a los métodos gráficos, tenemos la opción socorrida del histograma. Un histograma ilustra la distribución de los datos mediante barras verticales que representan la cantidad de casos que tienen un valor determinado. Las barras más altas corresponden a los valores más frecuentes. Un outlier se revelaría como un dato alejado del resto de la muestra. En la siguiente figura, la mayoría de los valores oscilan entre 0 y 6, pero hay un valor mucho más alto:

De todas formas, se trata de un procedimiento algo rudimentario y que depende demasiado del buen ojo que tenga el observador. Por suerte tenemos una alternativa mucho más informativa, los llamados “gráficos de caja” (boxplots):
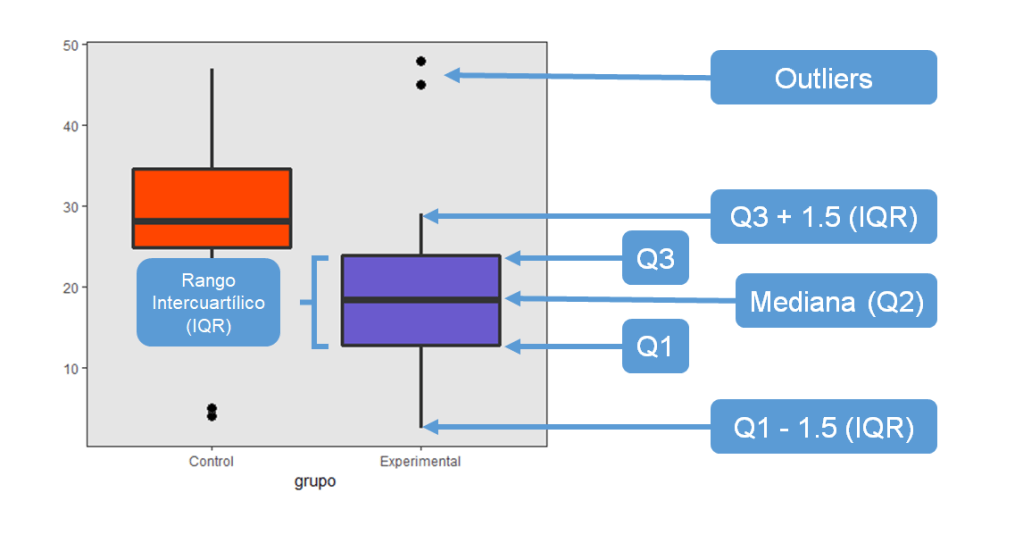
En este tipo de gráficos se representan las distribuciones de los datos de forma un poco diferente, porque se divide la muestra en cuatro porciones de tamaño similar: los cuartiles (primero, segundo, tercero y cuarto, o Q1, Q2, Q3 y Q4). La línea gruesa que queda aproximadamente en la mitad de la caja es la mediana, es decir, el punto de corte que divide a la muestra en dos mitades. A cada lado de la mediana, por arriba y por abajo, se extiende el “rango intercuartílico” (en inglés IQR), es decir, los cuartiles 1 a 3. Los outliers quedan fuera, y se representan en forma de puntos. Son valores extremos, muy improbables dada la distribución de la variable: están más de 1.5 veces el rango intercuartílico por encima del tercer cuartil (Q3), o por debajo del primer cuartil (Q1). Dependiendo del software que utilices, puede cambiar el punto de corte (entre 1.5 y 3 suele variar).
En cuanto a los métodos estadísticos para detectar outliers, tal vez el más conocido sea el método de Tukey. La idea es la siguiente: un outlier se define como un valor que está excesivamente alejado de la mediana, que es el punto medio de la distribución. Para descubrirlos, el primer paso que debemos dar es convertir nuestros datos a puntuaciones Z. Para ello, basta con restar a cada puntuación la media de todo el grupo, y dividir el resultado por la desviación típica. Al estandarizar los datos de esta manera, conseguimos que la media muestral de los datos así transformados sea igual a cero, y la desviación típica igual a 1. Ahora, los datos se expresan directamente como la distancia con respecto al centro de la distribución. Por ejemplo, una puntuación de 2.53 significa que esa observación es 2.53 desviaciones típicas mayor que la media, y una puntuación de -0.32 significa que ese caso está 0.32 desviaciones típicas por debajo de la media. Ya solo falta elegir un umbral, un punto de corte a partir del cual decidimos que la puntuación es un outlier porque está demasiado alejada del centro de la distribución. El punto de corte habitual suele ponerse en 1.5, 2, 2.5, ó 3. Si escogemos, por ejemplo, el 3 como punto de corte, consideraríamos un outlier a toda puntuación transformada por encima de 3 o por debajo de -3.
En este sentido, a veces uno está leyendo un artículo y descubre que han “expulsado a todos los outliers”, sin especificar cómo. Aquí sería importante que los autores nos dijeran cuál ha sido el punto de corte escogido para definir el caso como outlier. No es lo mismo un criterio estricto como “3 desviaciones típicas” que uno mucho más laxo, como “1.5 desviaciones típicas”.
¿Qué hacer con los outliers?
Llega el punto más delicado de todos, y el que produce un sinfín de malas prácticas y confusión. Imaginemos que he detectado unos cuantos casos extremos en mis datos. ¿Qué hago con ellos? ¿Los elimino o los dejo estar? Sobre este tema creo que no hay una opinión clara que se pueda generalizar a todas las situaciones. Realmente, por lo que voy leyendo, depende de a qué autores les preguntes, la recomendación es una u otra. Intentaré transmitir mi opinión sintetizando los argumentos que más me han convencido, pero estoy seguro de que otras personas podrán aportar otros puntos de vista. Allá voy.
PASO 1. ¿Es un error?
Lo primero que tenemos que decidir es si esa observación extrema que tenemos delante podría corresponder a un error de codificación. No sería tan raro, especialmente si utilizáis métodos de entrada de datos no automatizados. Suponed que estamos recopilando el peso de los perros de una ciudad, como en el ejemplo de arriba. Si de pronto me encuentro con un caso en el que un supuesto perro pesa 540 kg, seguramente concluiré que es un error. En estos casos, lo mejor será borrar ese dato erróneo.
PASO 2. ¿Afecta a las conclusiones?
Una vez descartado el error, tendríamos que investigar el grado de influencia de ese dato extremo en nuestros resultados, como he explicado antes. Si el outlier no produce cambios importantes (por ejemplo, afecta al valor del estadístico pero el p-valor sigue siendo significativo) ni supone una violación de los supuestos del análisis, entonces tal vez lo más cauto y transparente sea dejarlo ahí, pero indicar en el artículo que, de eliminar ese caso extremo, los resultados no cambiarían drásticamente. Esto además sería una señal de la robustez de las conclusiones.
Pero también podría ocurrir lo contrario, sobre todo si el outlier es además un caso influyente. Podría pasar, por ejemplo, que al eliminar ese caso extremo nuestra correlación se vuelva no significativa. ¿Y entonces qué hacemos? Contar el resultado sin más en un artículo no sería del todo honesto, pues sabemos que las conclusiones son muy dependientes de una sola observación. Ay, ay, ay…
Según indican algunos manuales y artículos sobre el tema (por ejemplo este), parece que en este tipo de situaciones (en las que el resultado cambia si quitamos el outlier), lo mejor es contar en el artículo los dos análisis: con y sin outlier. De esta forma no engañamos a los lectores.
La excepción vendría en aquellas situaciones en las que tenemos perfectamente claro que un resultado significativo se debe en realidad al outlier, como en el ejemplo que vimos más arriba y que os retomo a continuación:
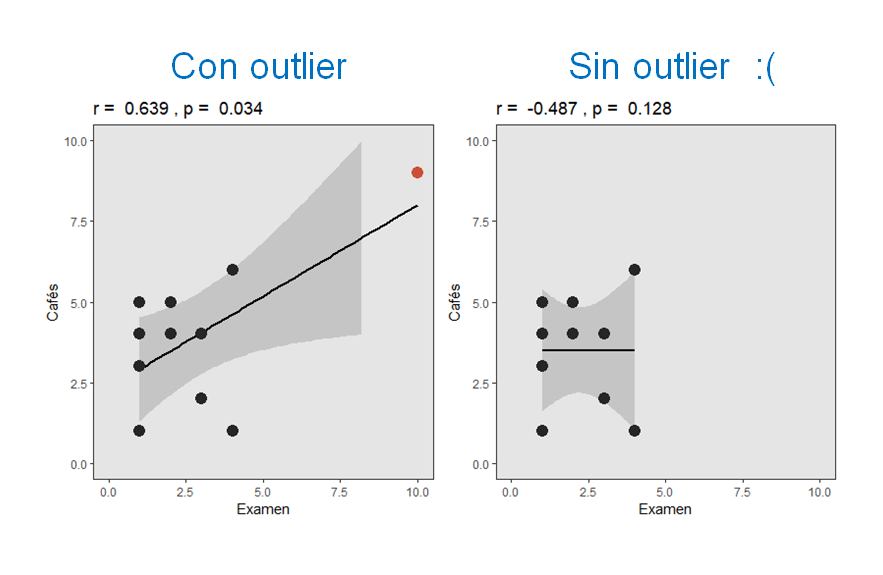
En estos casos, quizá lo mejor es quitar el outlier e interpretar que no existe una asociación significativa, ya que el coeficiente significativo (el de la izquierda, r = 0.639) no describe el efecto que tenemos realmente en los datos.
Por regla general, imagino que lo más importante es siempre justificar bien las decisiones que tomemos, sean las que sean. Por ejemplo, puede ser razonable pensar que si una observación distorsiona enormemente las conclusiones deberíamos eliminarla, ya que no está “contando la misma historia” que el resto de los datos. Pero lo que es menos razonable es eliminar a todos los participantes que tengan una puntuación extrema sin mayor análisis ni explicación, o incluso sin decir nada en el texto, ¿verdad? Pues justo esto es lo que se hace rutinariamente en muchos campos de investigación. Al loro con eso.
Otras opciones: no todo va a ser borrar datos
Y es que hay otras alternativas que conviene conocer y probar antes de ponerse a eliminar los outliers sin ton ni son. La primera opción es probar algún tipo de transformación de los datos que minimice el efecto distorsionador del caso extremo (Zimmerman, 1995). Si el outlier es un caso con una puntuación excesivamente alta, por ejemplo, una transformación logarítmica o una raíz cuadrada puede reducir la distancia entre las observaciones:

La segunda alternativa es elegir otro modelo estadístico que tenga supuestos diferentes. Por ejemplo, ya hemos comentado que las medias son muy sensibles a los casos extremos, mientras las medianas son bastante más resistentes. Por regla general, la estadística no paramétrica (que no exige los mismos supuestos sobre las distribuciones de los datos) puede ser una buena alternativa cuando tienes uno de esos molestos outliers. Lo mismo puede decirse de las técnicas de bootstrapping. En esta línea, también hay aproximaciones “robustas” para casi todos los tipos de análisis que empleamos comúnmente en psicología. Por ejemplo, podemos utilizar medias recortadas (“trimmed means”), que básicamente consisten en calcular la media después de haber eliminado la proporción más extrema de los datos. Una contrapartida: este tipo de análisis suelen tener una pérdida considerable de potencia, así que repasa este post sobre la potencia estadística y decide si te interesa.
Por último, acabo de aprender que hay quien recomienda imputar a los outliers valores que sí sean representativos de la muestra, como la media. Yo no tenía ni idea de que las técnicas de imputación podían emplearse en este contexto. ¡Las cosas que uno aprende cuando se prepara un post! Aun así, me parece un último recurso, y menos justificable que probar una transformación. Si alguien tiene una opinión diferente, soy todo orejas en los comentarios.
Referencias
- Aguinis, H., Gottfredson, R.K., & Joo, H. (2013). Best-Practice Recommendations for Defining Identifying and Handling Outliers. Organizational Research Methods. 16(2), 270–301. doi:10.1177/1094428112470848
- McClelland, G. H. (2000). Nasty Data: Unruly , ill-mannered observations can ruin your analysis. In H. T. Reis & C. M. Judd (Eds.), Handbook of Research Methods in Social and Personality Psychology (Vol. 0345, pp. 393–411). Cambridge, UK: Cambridge University Press.
- Zimmerman, D. W. (1995). Increasing the power of nonparametric tests by detecting and downweighting outliers. Journal of Experimental Education, 64, 71-78.

Muy buen post Fernando.
Te dejo el código que uso yo para calcular outliers con Mahalanobis y su aplicación en escalas y cuestionarios.
mahal = mahalanobis(data [,],
colMeans(data [,], na.rm = TRUE),
cov(data[,], use = “pairwise.complete.obs”))
#multivariante
cutoff = qchisq(0.999,ncol( data [,]))
ncol (filledin_missing [,)])##df
summary(mahal < cutoff)#cuantas personas están por debajo del punto de corte
#guardamos los sujetos que no son considerados outliers
data_noout = data [mahal < cutoff, ]#
dat_vo_fin =data_noout[ , ] #datos SIN OUTLIER!
Lo pego con el móvil espero que esté bien.
Espero el próximo post!
LikeLike
¡Gracias!
La verdad es que esto ya entraría en la detección de outliers multivariados, así que no se ha contado nada en el post.
Tengo que investigar más sobre qué técnica es más recomendable, porque las distancias de Cook son fáciles de entender para un post, pero luego he leído que no son muy eficaces, y que es mejor usar la que mencionas, las de Mahalanobis. Y aún así puede compensar aprender otras técnicas que se generalizan a cualquier distribución. ¿Sabes algo al respecto? Me interesa aprender.
¡Gracias también por compartir el código!
LikeLike
Saludos, muy interesante el post.
Tengo una duda, ¿si yo quisiera usar la metodología planteada (tanto univariada como en la respuesta multivarida) para determinar los puntos más cercanos si disponemos de las distancias de Mahalanobis, sería válido el planteamiento?
Me explico, en lugar de determinar el 5% de puntos más alejados, yo quiero determinar el 5% de puntos más proximos. O dicho de otra manera, usar por ejemplo un p-valor de 0.7 para determinar el 30% de valores más alejados (o el 30% de valores más proximos).?
Muchas gracias.
LikeLike
Hola, gracias por el mensaje.
La verdad es que no sé responder a tu pregunta porque nunca me lo había planteado y además no tengo suficiente conocimiento. Tal como lo has expresado me parece que tiene lógica, pero no sé si tiene algún problema que ahora mismo no pueda ver. La técnica no está pensada para eso, que yo sepa.
Buena suerte.
LikeLike
Maravilloso post! Gracias!!
LikeLike