Continúo con mi repaso sobre estadística básica para centrarme en un aspecto que hemos tocado muy de refilón. Imaginad que leemos en las noticias que se ha publicado un estudio con una conclusión que nos llama la atención, por ejemplo: “El 90% de los estudiantes de psicología prefieren la tortilla de patata sin cebolla”.

Leemos el titular, levantamos la ceja, y caemos en la cuenta de que el estudio se realizó con una muestra muy pequeña. Intuitivamente pensamos que el tamaño de la muestra es una amenaza a la capacidad de generalizar a toda la población los resultados obtenidos en la muestra. ¿Qué habría pasado si repetimos el estudio, otra vez con una muestra muy pequeña, pero al día siguiente? Es probable que el resultado cambie radicalmente (hay esperanza para los concebollistas).
El concepto que queremos ilustrar aquí se llama error de muestreo. La población real (a la que queremos generalizar nuestros resultados) tiene una distribución guiada por unos parámetros (como la media, μ, y la desviación típica, σ, en el caso de una distribución normal). Pero estos parámetros son generalmente desconocidos. ¡Nadie sabe cuál es la media “real” en la población! Para ello, tendría que encuestar a todas y cada una de las personas que forman parte de la población de interés, sin dejarnos ni una. En vez de eso, lo que hacemos es extraer una muestra de esa población, generalmente mediante un proceso aleatorio. La muestra tiene un tamaño mucho más pequeño y manejable, y nos permite calcular estadísticos como la media muestral, x, y la desviación típica muestral s. Estos estadísticos sí son conocidos porque se calculan a partir de la muestra. La gracia del asunto es que los estadísticos muestrales son una aproximación al parámetro de la población. Si en mi muestra la media es de 80, no sé cuál será la media poblacional porque nunca puedo estar seguro, pero mi estimación informada sería de “alrededor de 80”.
Eso sí, mi generalización tendrá que tener cierto margen de error, ya que cada muestra que extraiga de la población va a ser un poco diferente, debido a ese error de muestreo que habíamos explicado. En la siguiente figura, tenemos la representación de una distribución poblacional (arriba), y algunas muestras pequeñas (cada una con n=5) extraídas de la misma. Podemos ver cómo esas distribuciones no coinciden exactamente con la población: tendrán distintas medias, desviaciones típicas, y forma.
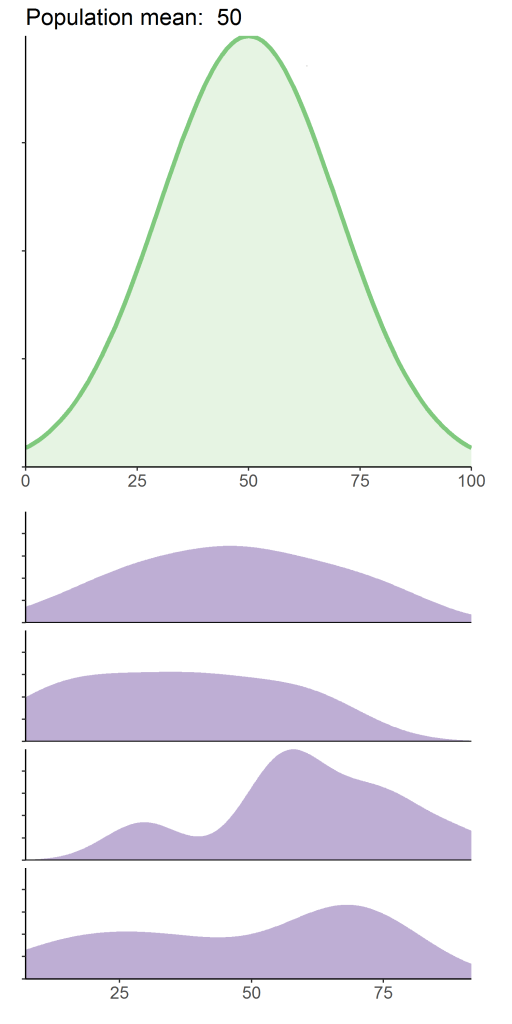
Como decía en el post anterior, podemos pensar en el proceso de muestreo como si consistiera en extraer bolas de un bombo de lotería. La población contiene una proporción determinada de bolas con un número par (por ejemplo, el 50%), que sería el parámetro poblacional. En cada muestra (extracción de un número pequeño de bolas) tendremos una proporción de bolas pares e impares ligeramente diferente (estadístico muestral), aunque si extrajésemos miles de muestras por este procedimiento, al final acabaríamos acercándonos mucho a ese 50%, ¿verdad?
¿Cuánto podría variar el valor del estadístico en cada muestreo? Buena pregunta, y depende de una serie de factores. Para comprobarlo, nada como echar mano de una herramienta fundamental para entender la estadística: vamos a simular el proceso de muestreo en R (por cierto: todo lo que programo es feo e incómodo, lo sé). La ventaja de ilustrar el concepto con simulaciones es que en estas, al contrario que en la vida real, sí podemos partir de un parámetro poblacional conocido.
En este ejemplo, he creado una “población imaginaria” con media 50 y desviación típica 10. Estos valores son arbitrarios y los he decidido yo, que es la gran ventaja de trabajar con simulaciones. Ahora vamos a extraer 20 muestras de esa población, cada una con un tamaño de 5 elementos:
trueMean <- 50 #Media poblacional
trueSD <- 10 #Desviación típica poblacional
numMuestras <- 20 #Número de muestras que queremos extraer
N <- 5 #Tamaño de cada muestra
meanSeq <- c() #Vector que contendrá las medias obtenidas.
for (i in 1:numMuestras){
currentData<-rnorm(N, trueMean, trueSD) #Extrae N datos de la población
meanSeq<-c(meanSeq, mean(currentData)) #Almacena la media de cada muestra
}
Ya sólo nos quedaría comprobar las medias que hemos obtenido en las 20 muestras, para ver cuánto se apartan del valor del parámetro conocido (la media poblacional era 50).
meanSeq
[1] 47.22 45.68 46.99 56.47 55.27 52.28 49.06 47.11 57.18 54.78 48.22 53.70 42.86 51.21 47.41 42.39 44.64 51.54 49.60 41.59
Aquí podemos ver que las medias se aproximan a 50, pero con variaciones aleatorias entre ellas: unas se pasan por mucho, otras se quedan cortas… Es el efecto del error de muestreo. Pero esto sólo lo sabemos porque es una simulación y nosotros hemos fijado los valores de los parámetros de antemano.
Entonces, si el parámetro poblacional es desconocido, y cada extracción muestral va a tener un resultado diferente por el error de muestreo, ¿estamos condenados a no poder hacer inferencias sobre la población? Claro que no, podemos hacerlas, pero siempre con un grado de incertidumbre.
Una cuestión de (Intervalos de) confianza
¡Y para trabajar con la incertidumbre es para lo que fue inventada la estadística! Vamos a repasar una herramienta básica, pero no siempre bien entendida, que nos ayuda a entender cómo de robusta es nuestra estimación a pesar del error de muestreo: los intervalos de confianza.
Un intervalo de confianza es un rango definido entre dos valores (límite inferior y límite superior), construido de forma que haya una cierta probabilidad de que contenga un valor desconocido (esa probabilidad es la confianza, generalmente fijada al 95%). En el centro del intervalo tenemos el valor de nuestro estadístico, la media muestral, que es nuestra mejor estimación para el parámetro poblacional desconocido. Los límites del intervalo se van a decidir en función de cómo de variable es la medición en la muestra (es decir, tendrán en cuenta su desviación típica, s, y su tamaño muestral, n). La idea es que, si repetimos un muestreo o un estudio muchas veces, el 95% de ellos van a contener el parámetro poblacional.
Esto significa también que el intervalo de confianza es un indicador de la precisión de nuestra muestra: si el intervalo es muy grande, significa que la medición no ha sido precisa (no nos informa mucho acerca del parámetro poblacional, ya que hay mucha variabilidad en la muestra); si el intervalo es pequeño, entonces nuestra estimación ha sido precisa.
Avancemos. ¿Qué factores pueden hacer que mis estimaciones sean más o menos precisas? Para simplificar, vamos a reducirlos a dos: el tamaño de la muestra y la dispersión.
En la siguiente figura, tenemos un ejemplo de todo lo que estoy contando. A partir de una población con media μ=50, hemos extraído 20 muestras. De arriba a abajo, los paneles difieren en el tamaño de esas muestras: pequeño (n=5), mediano (n=10), y grande (n=200). Los puntos representan la media obtenida en cada una de las muestras, con sus respectivos intervalos de confianza.
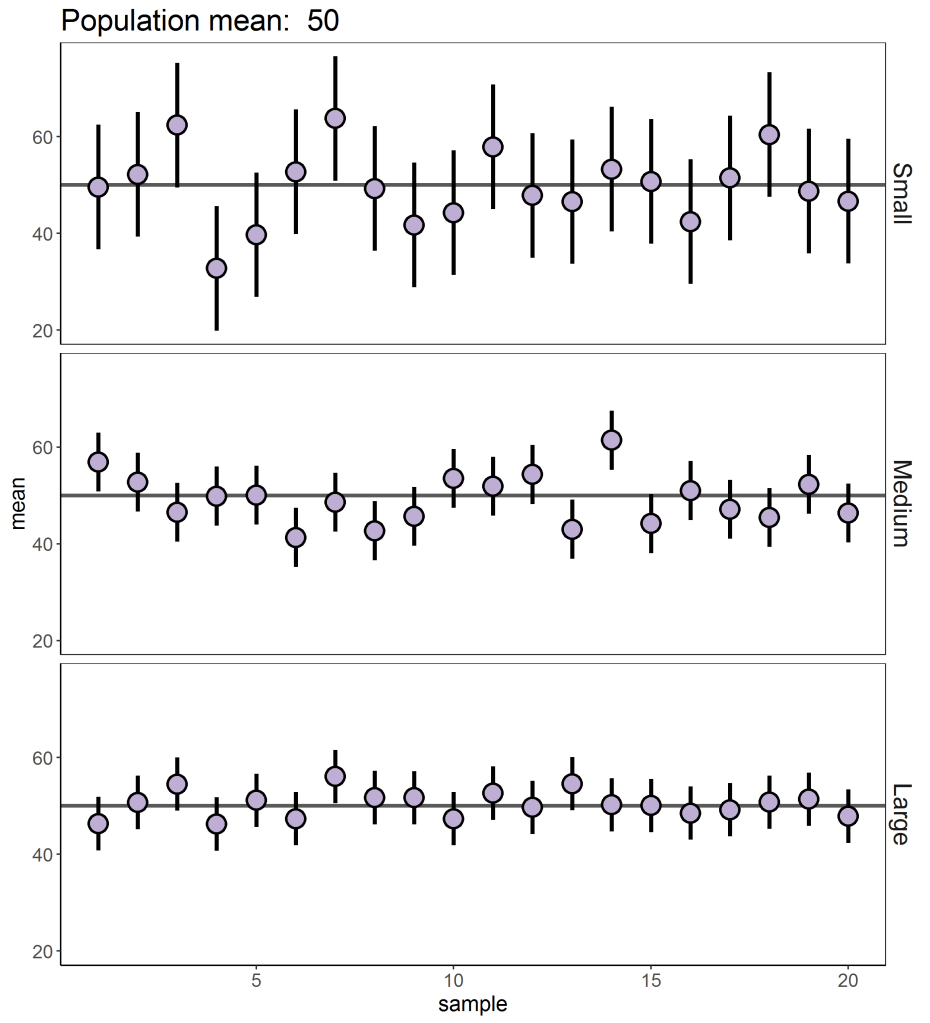
Fijaos en cómo cada muestra tiene una media ligeramente distinta, aunque en global todas oscilan en torno a la media poblacional. Las desviaciones con respecto a la media poblacional son más grandes cuanto más pequeño es el tamaño muestral. Por ejemplo, arriba podemos ver algunos valores para la media que están por encima de 60 o por debajo de 30, mientras que en el panel inferior se mueven entre los 42 y los 58 puntos, más cerca del valor real. Además de esto, mirad los intervalos de confianza: la mayoría de los intervalos contienen el valor real de la población (a la larga, serían el 95%). Ahora bien, los intervalos del panel inferior son los más pequeños, indicando mayor precisión en nuestras estimaciones. Así que ya sabéis: si queremos de verdad averiguar si a los estudiantes les gusta la tortilla con o sin cebolla, ¡necesitamos encuestar a una muestra cuanto más grande, mejor! (voy a obviar otros aspectos de un buen muestreo, como el que sea representativo, y me quedo en el plano del tamaño)
Otro factor que puede afectar a la precisión de nuestra estimación a partir de la muestra es la dispersión de la variable que estudiamos. Creo que se entenderá bien con este ejemplo. Imaginad que tengo un tanque con una solución de agua salada, y me interesa conocer la concentración de sal que hay dentro. Un procedimiento posible sería extraer una muestra pequeña del tanque con una jeringuilla, y medir la concentración de sal dentro de esa muestra. Sólo para estar seguros, repito la operación, y veo que el valor en la segunda muestra es el mismo. Una tercera vez, y obtengo el mismo valor. Apenas hay variación, ¿por qué? Una solución de agua salada suele tener una composición homogénea. Eso explica que las muestras sean muy similares entre sí, con apenas variaciones. Podemos imaginar que sus medias tienen intervalos de confianza muy pequeños, y que todas bailan muy cerca del valor real.
Pero la mayoría de los fenómenos en psicología son harina de otro costal. El equivalente, en este ejemplo, sería un tanque que no está lleno de agua salada (concentración homogénea), sino de pequeñas piedritas que se reparten de manera desigual. Esto va a crear diferencias grandes entre muestras sucesivas: unas veces la muestra pillará más piedritas, otras veces pillará menos.
El concepto que esta historia pretendía ilustrar es el de la desviación típica, la variabilidad que existe en la población (y que visualizamos como la “anchura” de la distribución poblacional), que nos dice cuánto se concentran los valores alrededor del parámetro μ. Mediante la siguiente simulación, vamos a ver cómo la desviación típica poblacional afecta a la robustez de las estimaciones muestrales, sobre todo si las muestras tienen tamaño pequeño:

De nuevo, fijaos en dos cosas: las medias muestrales se acercan al valor real (50) en ambos casos, pero están menos dispersas y son más consistentes cuando la desviación típica es pequeña (el equivalente a sacar una jeringa de un tanque de agua salada) que cuando la variabilidad es grande. En segundo lugar, ved cómo los intervalos de confianza también se hacen más pequeños en ese caso, indicando que las estimaciones serán más precisas.
Conclusiones
Hemos repasado un par de conceptos básicos: error de muestreo e intervalo de confianza. También hemos empezado a entender por qué las muestras grandes son mejores para hacer inferencias. Por otro lado, conviene recordar que el tamaño muestral no lo es todo, ya que aspectos más cualitativos del proceso de muestreo pueden ser vitales para que la muestra sea representativa. Por último, hemos visto un par de ejemplos de simulación con R que nos pueden ayudar a entender conceptos. Probad a cambiar los parámetros de la población, y ved cómo las muestras generadas van respondiendo a esos cambios.
ACTUALIZACiÓN (19/05/2019): He corregido una errata que había en el código, y he reemplazado uno de los gráficos por otro más evidente.
