Si hay un sentimiento constante que me acompaña desde que me propuse aprender estadística, es esa sensación por un lado estimulante y por otro un poco mortificadora de estar haciéndolo todo mal. O sea: ¿No compruebas los supuestos del análisis? MAL. ¿Interpretas un resultado no significativo como ausencia de efecto? MAL. Vale, ya sé que a palos se avanza, pero la experiencia es, como digo, a ratos un poco frustrante. Si te ves reflejado o reflejada en esto que estoy contando, entonces has llegado al lugar adecuado, porque esta serie de posts que estoy inaugurando la escribo para ti: sí, TÚ, que quieres usar la estadística para tu TFG, o para tu pequeña investigación, o simplemente para entender los papers, pero te has hartado de darte cabezazos contra la pared.
En este “curso” de estadística, voy a tratar uno por uno los errores más clásicos y frecuentes en el uso e interpretación de la misma. Espero que te guste.

Cuando no tienes un buen control.
Y voy a empezar hablando de uno de los problemas clásicos que me encuentro en los TFGs y TFMs, pero que también aparece con cierta frecuencia en artículos que han pasado revisión por pares (¡!). Me refiero a los estudios que no pueden concluir lo que dicen porque carecen de una buena condición de control. Y me diréis: ¿es tan grave el asunto? ¿y cómo se hace un buen control? Bueno, paso a paso. Vamos a ilustrarlo mediante ejemplos inspirados en artículos reales de diversas temáticas.
Ejemplo 1: Sin condición de control.
Poneos en situación. Un artículo en una revista sobre psicología educativa nos presenta una nueva técnica de adquisición de habilidades matemáticas. En vez de escuchar pasivamente al profesor y practicar los ejercicios de geometría (qué es una bisectriz, qué es un ángulo…), los autores proponen que, para aprender matemáticas, nada como echar una partida al DOOM en vez de ir a clase. Y tiene toda la lógica: jugando a DOOM, el estudiante se divierte, activa los circuitos cerebrales de recompensa [nota: inserte aquí el lector/a un poco más de jerga neuroeducativa, que no estoy inspirado], y sobre todo experimenta activamente con entornos tridimensionales y asimila la geometría casi sin darse cuenta. ¿Os convence la propuesta? No importa, sigo.
Los autores describen entonces su estudio. Primero, seleccionan a aquellos estudiantes de secundaria con la peor nota de la clase en matemáticas, los que más dificultades tienen. A continuación, para asegurarse, les hacen una prueba de conocimiento sobre geometría. Esta primera medición suele llamarse “línea base”, ya que se realiza antes del tratamiento, y nos permite ver cuál es el punto de partida. A continuación, los estudiantes tienen dispensa de clase de geometría para todo el curso, y en su lugar se dan una buena viciada matando cacodemonios. Por último, ya al final del curso, les vuelven a hacer un test de geometría para ver cómo han mejorado. Este diseño se conoce a veces como “pretest-posttest”, y seguro que si habéis estudiado psicología, pedagogía, o ciencias afines os va a sonar mucho. En contextos educativos, por ejemplo, no es nada raro encontrarse artículos como el que estoy describiendo (Knapp, 2016).
En cualquier caso, el resultado obtenido lo tenemos aquí:

¡Tiene buena pinta! Sin duda observamos una mejora en los estudiantes entre antes y después de hacerse unos expertos en asesinar marcianos. En concreto, la diferencia la evaluamos con una prueba t y es significativa: p = 0.021. ¡Genial! El tratamiento ha funcionado.
Bueno…
…Ya, imagino que os habéis dado cuenta. El estudio no demuestra que el tratamiento sirva para nada. ¿Dónde está el problema? En el diseño, que carece de un grupo de control, y por lo tanto no permite descartar otras posibles explicaciones para la mejora observada. Sólo por esta vez, vamos a enumerar unas cuantas explicaciones alternativas que se nos podrían ocurrir:
- Eventos no controlados y Maduración: la línea base se obtuvo a principios de curso, y la medición final al final del mismo. Entre tanto han pasado meses, con todo lo que conlleva, incluyendo la maduración del sistema nervioso (especialmente relevante en el caso de niños pequeños), y también la posible influencia de los contenidos de otras asignaturas. Imaginad por ejemplo que a mitad del estudio, en la asignatura de lengua les enseñaron a leer de forma ordenada los problemas de matemáticas, reduciendo por lo tanto la cantidad de “fallos tontos” al responder, y sin que el videojuego haya tenido nada que ver.
- Efecto de práctica: la segunda vez que se hace el test de geometría, no solo ha habido incontables horas de juego desde la última vez, sino que se da otra circunstancia. El test ya no es una experiencia nueva, incluso aunque cambiemos las preguntas. No es extraño que los estudiantes hayan adquirido cierta destreza con la práctica, que estén menos ansiosos, o incluso que hayan aprendido de sus errores.
- Regresión a la media: esta explicación la suele pasar por alto todo el mundo. Fijaos en que hemos seleccionado para el estudio aquellos niños que peor nota tenían en geometría. Por lo tanto, la próxima vez que los midamos, tienen más probabilidad de mejorar dicha nota. Pero esto no quiere decir que hayan aprendido nada, se trata de un conocido artefacto estadístico que tal vez requiera un post por sí mismo.
Me dejo muchas posibles explicaciones en el tintero, pero el mensaje creo que queda claro clarinete: necesitamos un grupo de control. La pregunta ahora es ¿qué tipo de control?
Ejemplo 2: Un mal control (controles pasivos).
Vamos a pensar otra situación, esta vez en el contexto clínico. En este ámbito, con frecuencia nos interesa saber si un tratamiento funciona, por ejemplo, para reducir la depresión de los pacientes. Todavía con cierta frecuencia me encuentro con estudios que emplean un control de tipo pasivo, cuyo exponente más conocido es el control “de lista de espera”. La idea es la siguiente. Reunimos un grupo de pacientes con depresión. A la mitad de ellos les aplicamos nuestro nuevo tratamiento (grupo “experimental”). A la otra mitad (grupo control) les diremos que están en lista de espera para recibir el tratamiento. Después (una vez completada la intervención en el grupo experimental) mediremos a los dos grupos en el mismo momento.
Al medir a todos los participantes a la vez estamos evitando algunos de los problemas del caso anterior. Imaginemos que el resultado es el siguiente:
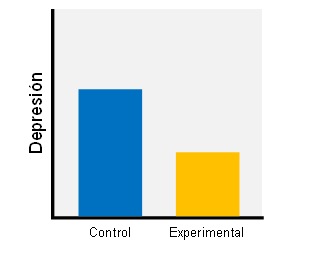
El análisis estadístico me indica que el grupo experimental tiene una puntuación de depresión significativamente menor que el grupo control, p = 0.03. A partir de ahí, podría concluir que el tratamiento ha funcionado.
Otra vez: no, no lo puedo concluir. ¿Por qué? Esta vez sí que tengo un grupo de control para comparar. Lo que pasa es que el grupo de control es muy malo. Pensadlo bien, mirando la figura: ¿me está diciendo la figura que el grupo experimental ha reducido la depresión? ¿o quizá es que el grupo control ha aumentado la suya?
Efectivamente. El control de lista de espera es muy mal control, y no sé por qué se sigue utilizando hoy en día (médicos y nutricionistas, daos por aludidos). El problema es que los pacientes que están en lista de espera son conscientes de que no se los está tratando, lo cual afecta a su salud percibida, calidad de vida, y otros parámetros relevantes. En el caso de la depresión, se ha documentado que las listas de espera tienen un efecto negativo, conocido como “efecto nocebo”, de forma que pueden observarse en los controles empeoramientos de hasta un 30% con respecto a la línea base (Furukawa et al., 2014). En definitiva, el gráfico de arriba podría interpretarse como que el tratamiento no funciona nada, ya que simplemente mantiene a raya el efecto perjudicial de la lista de espera.
¿Qué tipo de control podríamos utilizar en vez de la lista de espera? En muchos casos podríamos plantearnos un control con tratamiento de tipo “placebo”, es decir, un tratamiento que es realmente inactivo (no va a producir una mejoría sustancial), pero que el participante pueda pensar que es activo. Por ejemplo, cuando el tratamiento es farmacológico, el placebo puede ser una pastilla con el mismo aspecto y sabor, sólo que sin el principio activo. En el caso de una psicoterapia, podemos plantear alguna actividad que iguale al tratamiento en cuanto a sensación de estar siendo atendido y escuchado, pero que carezca del elemento principal al que teóricamente atribuimos la eficacia. Se ha comprobado cómo esa percepción y expectativa de estar siendo tratado pueden mejorar el estado de los pacientes, lo que se conoce como el “efecto placebo”.
De hecho, hoy en día todos los medicamentos comerciales se prueban (como mínimo, ¡minimísimo!) frente a un placebo, de forma que sólo se aprueban si demuestran ser más eficaces que el mero efecto psicológico que proporciona la expectativa de tratamiento. Sin embargo, incluso el placebo es un control poco exigente (es que es pedir muy poco, “curar más” que una pastillita de azúcar). Deberías plantearte alternativas mejores, más rigurosas. Por ejemplo, comparar tu nuevo tratamiento con el tratamiento de referencia de esa patología.
Ejemplo 3. Más efectos de las expectativas
El efecto placebo es un buen ejemplo de cómo las expectativas del paciente pueden afectar a su evolución. ¿Cabría pensar en la posibilidad de que también influyeran las expectativas del experimentador? ¡Por supuesto!
Veréis, en un artículo clásico, Bargh et al. (1996) demostraron un curioso efecto que podríamos llamar “facilitación viejuna” (elderly priming). Este tipo de efectos de priming o facilitación consisten en la exposición, de manera más o menos sutil, a unos estímulos que supuestamente “activan” en los participantes los esquemas conductuales con los que están conectados, produciendo así cambios en la conducta que son muchas veces inconscientes para el participante. En este experimento en concreto, Bargh y colaboradores citaban a los participantes en el laboratorio. Allí los entretenían realizando tareas mientras les leían una serie de palabras. En el grupo experimental, las palabras tenían que ver con la vejez, como por ejemplo “anciano”, “obsoleto”, “cansado”… En el grupo control, las palabras correspondían a otro campo semántico (“monitor”, “sediento”…). Al acabar la tarea, los participantes abandonaban el laboratorio, y el experimentador cronometraba cuánto tiempo tardaban en hacerlo. El resultado es que los participantes del grupo experimental, que habían sido expuestos a las palabras que tenían que ver con la vejez, salían caminando significativamente más despacio. Es decir, el esquema de “vejez” activado mediante las palabras se había transferido a sus movimientos corporales, haciendo que se muevan “como ancianos”.

Hasta aquí todo nos encaja: hay un grupo de control, el control no está pasivo sino que realiza una tarea de características muy similares… ¿dónde está el problema?
En 2012, Doyen et al. realizaron una serie de intentos de replicar este estudio, y llegaron a una conclusión muy interesante. El efecto de elderly priming sólo se replicaba cuando el experimentador que cronometraba a los participantes conocía la hipótesis del estudio, y a qué grupo correspondía cada participante. Cuando la medición se automatizaba por medio de un cronómetro electrónico, el efecto se desvanecía. La conclusión es que probablemente el efecto descrito inicialmente en el artículo de Bargh y colaboradores se debía (en parte) a una contaminación de las expectativas del experimentador. Sin proponérselo, incluso sin darse cuenta, el propio experimentador estaba sesgando las mediciones al retrasar inadvertidamente la pulsación del reloj en uno de los grupos con respecto al otro.
De modo más general, las expectativas del investigador pueden influir claramente en el resultado de un estudio. Por ejemplo, es casi inevitable que un fisioterapeuta que está tratando a un paciente especialmente grave le dedique algo de esfuerzo extra, mientras que se esmere menos en el grupo “placebo”, donde sabe que su intervención no debería producir un efecto.
Hoy en día se intenta prevenir este tipo de problemas mediante el uso de controles “doble ciego”. En un control de este tipo, ni el paciente ni el experimentador conocen a qué grupo corresponde cada participante, de modo que sus expectativas no pueden influir directamente en la medición (Holman et al., 2015).
Ejemplo 4. Controles incomparables
Saltamos a otro contexto habitual para hablar de otro de los problemas típicos con los controles. Sabéis que las personas que han sufrido un ictus o un accidente cerebrovascular pueden mostrar déficits serios en áreas como la coordinación de movimientos o el habla. Las secuelas pueden ser tanto físicas como cognitivas. Para tratar a estos pacientes, se han diseñado muchas intervenciones basadas en ejercicios de neuro-rehabilitación, que prometen bien recuperar parte de la función perdida, bien compensarla.
Vamos a imaginar que has diseñado un programa de rehabilitación neurológica para mejorar la agilidad mental en pacientes con ictus. Como eres una persona aplicada, has leído atentamente los ejemplos anteriores de este post, y estás dispuesto/a a evitar los errores comentados. Así, decides que vas a tener un grupo de control (¡bien hecho!), y que dicho control va a recibir un tratamiento en vez de quedarse sin hacer nada (¡chachi!). Incluso optas por un diseño un poco más sofisticado: vas a medir a los dos grupos en dos ocasiones, antes y después del tratamiento, de forma que podrás comparar el efecto de la intervención en ambos grupos. Así, realizas tu estudio aplicando tu técnica a una muestra de pacientes con ictus a la que has medido previamente, y lo comparas con un grupo de controles sanos que ha pasado por un tratamiento placebo que se asemeja en tiempo y forma, pero no contiene los ingredientes clave cuya eficacia quieres demostrar. El resultado quedaría tal que así:

A simple vista, parece que el tratamiento funciona, puesto que los pacientes mejoran notablemente, en mayor medida que los controles.
Sin embargo, el haber tomado las cautelas mencionadas no te libra de los problemas. Y es que reclutar pacientes con ictus es costoso, lento y caro. Así que tus controles han sido personas sanas. Observa con cuidado la diferencia de puntuaciones en el momento “pre”, antes de la intervención. ¿Empiezas a ver dónde está el fallo? ¡El estudio no te dice absolutamente nada sobre la eficacia del tratamiento!, porque tu condición de control no es comparable con la experimental. En el momento de la primera medición (línea base) los dos grupos ya son completamente diferentes.
En este caso, lo apropiado habría sido hacer un grupo de control con pacientes comparables a los del grupo experimental. En este tipo de estudios contamos con una dificultad añadida, y es que es muy difícil encontrar casos que sean realmente comparables. Por ejemplo, un ictus tiene secuelas que pueden ser de características y gravedad muy diferentes a otro, y el pronóstico del paciente está muy ligado a factores individuales como el sexo, la edad, o el nivel de salud general… Si quisiéramos hacer las cosas bien, tendríamos que emplear una muestra que controlase todos estos factores uno por uno. Habitualmente, se utilizan técnicas como el “apareamiento”: para cada participante del grupo experimental, se localiza otro para el grupo control que tenga valores similares en todos estos parámetros. Una labor complicada y tediosa.
Conclusiones
Vamos a terminar recapitulando. En primer lugar, ¿para qué queremos un grupo o una condición de control? Para descartar explicaciones alternativas a nuestros resultados. Esto significa que tenemos que: (1) identificar todas las posibles variables contaminadoras o fuentes de error, (2) igualar a los grupos en todas estas variables, o intentar que las diferencias se repartan aleatoriamente entre los grupos. Un buen grupo de control es idéntico al grupo experimental salvo en una cosa: justo la que es objeto de nuestra manipulación, o la que queremos investigar.
Esto no es tan fácil como parece. Es habitual que nos rompamos la cabeza decidiendo el mejor diseño, y que los revisores imaginen sin problema explicaciones alternativas que ni se nos habían pasado por la cabeza, que requieren controles adicionales. Por otra parte, a veces se publican artículos con controles muy defectuosos. Os aseguro que los ejemplos que he contado en este post están inspirados en diseños de estudios reales, la mayoría de ellos publicados, por increíble que parezca.

Muchas gracias por este curso Fernando. Se lo agradezco mucho, de verdad.
LikeLike