
Tras un descanso en el blog, aprovecho las vacaciones y retomo esta serie sobre estadística visual donde la dejamos, para progresar y entender un concepto sumamente importante en el diseño de estudios: la potencia estadística. Vamos a aprender por qué es importante reclutar muestras grandes para tus estudios, y qué ocurre cuando no cumplimos ese objetivo. Como siempre, echaré mano de simulaciones en R y de visualizaciones. ¡Al lío!
Recordemos que, al diseñar un estudio o experimento en psicología, generalmente obtenemos un estadístico que llamamos “p” o “p–valor”, y que toma valores entre 0 y 1. El p-valor nos va a decir la probabilidad de obtener unos datos como los que hemos conseguido (o más extremos) bajo la hipótesis nula. En otras palabras, es una cuantificación de “cómo de sorprendente” sería obtener nuestros datos por azar. Generalmente, usamos un umbral para interpretar el p-valor: si el p-valor es menor de 0.05, decimos que el resultado es significativo, pues los datos son muy “sorprendentes” (improbables bajo la hipótesis nula).
Ahora bien, hay ciertas intuiciones sobre los p-valores que están muy asentadas (como se ve en la imagen), pero que son incorrectas.

En el post anterior, comprobamos que el umbral del p-valor sirve para mantener a raya el error tipo I, o la tasa de “falso positivo”. ¿Cómo lo consigue? Vamos a simular en R unos cuantos experimentos al azar. En cada “experimento”, generamos dos muestras aleatorias de participantes, y las compararemos entre sí obteniendo un p-valor. Recordad que, si no tenéis R a mano, podéis copiapegar el código y jugar con él en esta web sin instalar nada: https://rextester.com/l/r_online_compiler
grupo1.n <- 10 #esto es el tamaño muestral de cada grupo
grupo2.n <- 10
grupo1.mean <- 50 #las medias de las poblaciones son idénticas (luego no hay diferencias)
grupo2.mean <- 50
grupo1.sd <- 10 #desviación típica de cada población.
grupo2.sd <- 10
numMuestras <- 10000
pvalue <-c()
for(i in 1:numMuestras){
grupo1.sample <- rnorm(grupo1.n, grupo1.mean, grupo1.sd)
grupo2.sample <- rnorm(grupo2.n, grupo2.mean, grupo2.sd)
pvalue <- c(pvalue, t.test(grupo1.sample, grupo2.sample)$p.value)
}
hist(pvalue) #esta línea produce un gráfico con la distribución de los valores.
En esta simulación, el efecto real que estamos buscando es cero (porque las dos medias poblacionales son idénticas, tienen el mismo valor, 50), es decir, la hipótesis nula es cierta. Sin embargo, cuando examinamos el gráfico con la distribución de los p-valores de los 10000 experimentos, vemos que, a pesar de lo que indica la intuición de los tuiteros de la encuesta que os cité arriba), todos los valores posibles son equiprobables, lo mismo los grandes que los pequeños. Y también vemos que es perfectamente posible encontrar por puro azar resultados significativos (están marcados en amarillo/naranja):

Esto nos ayuda a entender por qué el umbral de significación se ha fijado en 0.05. Daos cuenta de que, en esta figura, el 5% de los p-valores está por debajo de 0.05, dado que la distribución es uniforme: o sea, hay una probabilidad del 0.05, o 5%, de tener un p-valor igual o menor de 0.05, una probabilidad de 0.10, o 10%, de tener un p-valor igual o menor a 0.10, y así sucesivamente. El error tipo I, o “falso positivo”, implica que, aunque el efecto es realmente inexistente, por puro azar encontramos datos que parecen apoyarlo. Si queremos cometer este error no más de un 5% de las veces (es decir, con una probabilidad de 0.05), entonces tiene todo el sentido del mundo que pongamos justo ahí el umbral de significación: sólo afirmaremos que el resultado es significativo cuando p < 0,05, lo que solo ocurre por puro azar el 5% de las veces. Por otro lado, esto también implica que hay que ser cautelosos al interpretar los resultados de un estudio aislado, porque meramente por azar vamos a tener resultados significativos ¡como mínimo el 5% de las veces!
Hasta aquí habíamos llegado en el post anterior, aunque convenía repasar para tenerlo fresco antes de seguir. ¡Continuemos!
Cuando el efecto sí está ahí.
Ahora vamos a imaginar una situación distinta. Estamos probando un tratamiento para la depresión, y para ver si funciona realizamos un estudio conde comparamos la puntuación de depresión de un grupo tratado con la de un grupo control que no ha recibido ningún tratamiento. Aprovecho para señalar que este tipo de grupo de control es nefasto, porque los pacientes no tratados pueden experimentar un deterioro (producido en parte por el efecto nocebo), haciéndonos creer que el tratamiento sí funciona incluso cuando no sea así. Por eso siempre es mejor tener un control que reciba algún tipo de tratamiento (un placebo, o la terapia de referencia…). En cualquier caso, para el ejemplo nos da lo mismo, pues el diseño del estudio es sencillo: vamos a comparar dos grupos, y esperamos que la puntuación del grupo tratado sea menor que la del control. Es decir, estamos imaginando que sí hay un efecto, y queremos detectarlo.
Como en el caso anterior, simularemos 10000 estudios como el que he descrito, y obtendremos para cada uno un p-valor para poder examinar su distribución. El código es idéntico al de antes, solo que ahora fijaremos medias diferentes para las poblaciones que van a generar todos estos estudios. A modo de ejemplo, he usado los valores de media poblacional 50 y 53, lo que produce un tamaño del efecto poblacional de 3 puntos (53-50=3). Cambiad la siguiente línea en el código, y ejecutadlo igual que antes:
grupo1.mean <- 53 #las medias de los dos grupos son diferentes.
grupo2.mean <- 50
Si todo ha ido bien, la forma de la distribución habrá cambiado totalmente: ahora ya no es uniforme, sino exponencial. Los valores pequeños son más probables que los grandes, lo que crea esa asimetría que podéis observar.

La sección del gráfico que está en color amarillo/naranja corresponde a los p-valores significativos (por debajo de 0.05), igual que antes. Pero dado que ahora sabemos que sí que existe un efecto (es decir, las diferencias que encuentran estos 10000 experimentos no se deben únicamente al azar), hay que interpretarlos de otra manera. Ahora la parte resaltada de la distribución no representa resultados que han salido significativos por azar, sino estudios que han tenido éxito al capturar un efecto que sí existe: sabemos que hay diferencias entre las dos poblaciones, y esos son los estudios que han producido una p < 0.05 (significativo).
A esta porción resaltada la vamos a llamar “potencia estadística”: representa la probabilidad de que mi estudio vaya a capturar (obtener p < 0.05) un efecto que sí existe. En este caso, estábamos buscando un efecto relativamente pequeño (recordad, las medias poblacionales eran 50 y 53, una diferencia pequeña de sólo 3 puntos), así que no es de extrañar que la potencia obtenida haya sido un poco decepcionante: fijaos en que sólo un 10% de los resultados han sido significativos (os lo indico en la figura, arriba, donde dice “positive-rate” o “tasa de positivos”: 0.096, aproximadamente 10%). Es decir, que si realizo docenas, o cientos de experimentos como éste, incluso habiendo una diferencia real entre el tratamiento y el control… ¡sólo la voy a encontrar con éxito el 10% de las veces! Un despropósito.
Por suerte, podemos hacer algo para mejorar la potencia. En principio lo ideal sería usar mediciones más precisas, más exactas, lo que va a reducir el dichoso error de muestreo y a reducir las discrepancias entre estudios. Pero si no fuera posible (en psicología es generalmente una pesadilla desarrollar medidas precisas), recordad que hay otra forma de reducir este error de muestreo, que ya vimos en otros posts: aumentar la muestra.
Un consejo: no os creáis nada si no lo ven vuestros propios ojos. ¡Así que simuladlo! Coged el código del ejemplo anterior, y cambiad el tamaño muestral de los estudios, que yo había fijado en 10 por grupo. Subidlo a, por ejemplo, 50, y observad la distribución:
grupo1.n <- 50 #esto es el tamaño muestral de cada grupo
grupo2.n <- 50
¿A que va cambiando la cosa? Efectivamente, al aumentar el tamaño muestral, estamos conteniendo un poco el error de muestreo, y con ello aumentando nuestra potencia. Esto causa que una proporción mayor de estudios sean significativos (p < 0.05). Aquí os pongo algunos ejemplos para que lo visualicéis mejor:
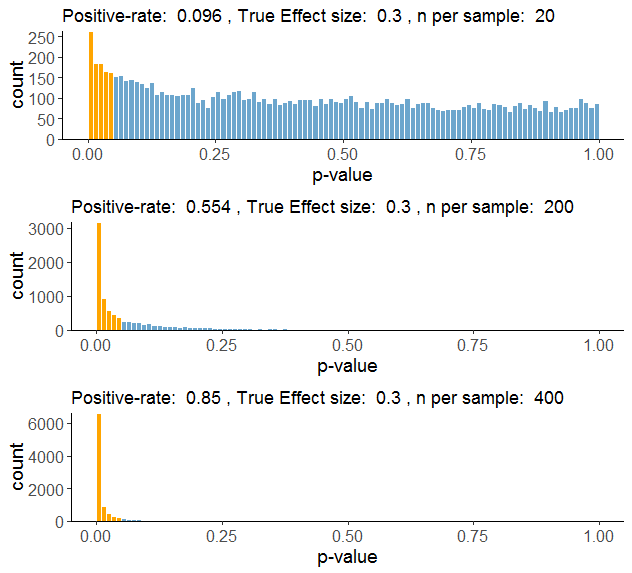
En estos tres ejemplos, lo único que está variando es la N, o tamaño muestral: en la fila de arriba, los grupos tienen 10 participantes, en la fila de en medio, 100, y en la de abajo, 200 participantes. Lo interesante es fijarse en cómo va aumentando la tasa de positivos, o potencia, al aumentar la muestra: hemos subido de un mísero y decepcionante 0.096 (aproximadamente 10% de los resultados son p < 0.05), a un más prometedor 0.85 (el 85% de los resultados son p < 0.05). En la fila de en medio, con una N de 100 participantes por grupo, la mitad de los estudios que hemos simulado producen el resultado esperado, y la otra mitad fallan. Es como lanzar una moneda al aire. Si repites el estudio, idéntico en todos los sentidos, podrías obtener un resultado diferente. Desde luego, esto no es lo que uno tenía en mente cuando decía que estaba haciendo ciencia.
Hay que tener en cuenta un detalle que no he mencionado: la potencia o “tasa de éxito” de los estudios también va a depender del tamaño del efecto real (es decir, de la magnitud de la diferencia entre las dos medias poblacionales, en este caso). Con una muestra de 100 participantes puede que tenga baja potencia para detectar una diferencia de 3 puntos (pequeña), pero podría ser una potencia aceptable para detectar efectos más grandes, de 20 puntos por ejemplo. Como siempre, probad a cambiar los números en la simulación (en este caso, dejando fija la N y cambiando las diferencias entre las medias) para aseguraros de que entendéis lo que está pasando.
La utilidad del concepto de potencia
¿Y para qué queremos saber esto? Bien, creo que una de las cosas que más me ha perjudicado en mi formación estadística es precisamente que no me hablasen de esto mucho antes, desde el principio. Sí, antes de meternos a prender ANOVAs y análisis complicados. Mirar y entender estas distribuciones que os he enseñado arriba es un antídoto contra el autoengaño: es relativamente fácil obtener un p-valor significativo por azar (como vimos en las primeras simulaciones), y es todavía más fácil hacer un estudio y que NO salga significativo por falta de potencia (mirad, si no, la segunda fila del gráfico anterior: el 50% de los estudios van a fallar). Por otro lado, ahora que sabemos cómo se comportan los p-valores en uno y otro caso, podemos planificar con la potencia en mente. Básicamente, la enseñanza que hay que extraer de todo esto es que, si no queremos estrellarnos una y otra vez con un resultado no significativo, necesitamos muestras grandes. Mucho más grandes de lo que solía ser habitual hace unos años en psicología.
Y ya que estamos con el tema, ¿cuál es la potencia habitual en psicología? ¿Estamos como en la primera fila del gráfico, o como en la de abajo? Pues bien, se han hecho unas cuantas estimaciones examinando los estudios publicados (ojo, esto supone un sesgo: no sabemos cuál podría ser la potencia de los estudios que no se han publicado), con resultados un tanto mezclados. Es cierto que hay grandes diferencias en función del área: en estudios sobre personalidad trabajan con muestras grandes, mientras que en ámbitos neuropsicológicos (debido a que estudian muestras de pacientes difíciles de conseguir, o bien usan técnicas de medición muy caras) ocurre lo contrario, y las muestras tienden a ser demasiado pequeñas. Para que os hagáis una idea, una estimación de la potencia en ámbitos de psicología clínica (Rossi, 1990) nos dice que, para detectar un efecto de tamaño pequeño o medio, los estudios publicados tienen una potencia de 0.17 y 0.57, respectivamente. O sea, que cuando las diferencias reales son pequeñas, hay campos de la psicología donde los estudios se diseñan de tal forma que entre un 17% y un 57% logran capturar el resultado, lo cual es desastroso. No podéis verme, pero mientras escribo estas líneas estoy haciendo facepalm muy fuerte.
Y otra enseñanza que habremos adquirido al entender el concepto de potencia es que hay que desconfiar cuando los resultados de un artículo son, digamos, demasiado bonitos…

Imaginad un artículo donde intentan demostrar el efecto negativo de los videojuegos sobre la concentración. Es uno de esos artículos donde se describen múltiples experimentos, pongamos por ejemplo, siete. Cada uno de ellos utiliza una manipulación ligeramente diferente, o tiene una medición o tipo de muestra algo distinta, y con ello pretenden ofrecer evidencia robusta de que el fenómeno existe en un rango de posibles situaciones. Hasta aquí bien. ¿Cuál es el problema? Que los siete experimentos aportan un resultado significativo. No cuatro, ni seis, no: los siete.
¿Y qué?, me diréis. Al fin y al cabo esto debería interpretarse como que el resultado es robusto y replicable: ¡se ha replicado nada menos que siete veces! ¿Por qué debería levantar mi ceja y sospechar? Pues porque es un resultado demasiado bonito para ser verdad. La clave está en que la potencia de cada estudio individual no es perfecta (no llega al 100%). Es decir, como hemos visto, siempre hay cierta probabilidad de que, incluso aunque el efecto esté ahí, el estudio no sea capaz de detectarlo y no produzca un resultado significativo. Ahora pensad en cómo esto afecta a la probabilidad de obtener una secuencia de experimentos con resultados perfectos.
Para hacerlo más fácil, pensadlo de la siguiente manera. Imaginemos que los siete estudios están realizados con una potencia media: 0.50. Es decir, asumiendo que el efecto es real y lo podemos ver, el 50% de los experimentos van a producir una p < 0.05. Es como lanzar una moneda al aire. Pero es que el artículo no está contando un experimento aislado, ¡sino una serie de siete! O sea: has lanzado la moneda siete veces, y las siete te ha salido cara, que es justo lo que predecías. ¿Sospechoso?
¡Podemos calcular exactamente cómo de sospechoso es el resultado! Si recordáis las clases de matemáticas del bachillerato, la probabilidad de obtener una secuencia de sucesos en experimentos independientes se calcula como la probabilidad conjunta de todos ellos. En este caso, sería así:
0.50 x 0.50 x 0.50 x 0.50 x 0.50 x 0.50 x 0.50 = 0.0078.
Traduciendo a porcentaje: si intento replicar la cadena de siete experimentos en idénticas circunstancias, sólo lo conseguiré el 0.78% de las veces. Menos del 1%. Es muy improbable. Tan improbable como obtener con una moneda siete caras seguidas de siete lanzamientos.
La cosa se pone todavía peor si recordamos que, en realidad, la potencia media en los estudios de psicología puede ser bastante menor de 50%. Imaginemos que es por ejemplo del 30%. La probabilidad de obtener siete resultados significativos sería de 0.00022, o sea, del 0.02%.
¿Cómo interpretar entonces esos artículos preciosos, fantásticos, que nos dan tanta envidia, en los que todo sale significativo y están repletos de asteriscos? En dos palabras: publicación selectiva. Quizá los autores realizaron no siete, sino veinte o treinta experimentos como los que describen, pero luego seleccionaron aquellos que salieron significativos para contarlos en el artículo, callándose el resto. De hecho, esto parece ser que ocurre de manera muy habitual en ciertos ámbitos y sobre todo en algunas revistas, como la prestigiosa Science (Francis et al., 2014). Cuando uno lee la literatura científica, urge mantener una mentalidad escéptica.
Con esta reflexión lo dejamos por hoy. Otro día seguimos, ¡prometido! Buen verano.
Referencias
- Francis, G., Tanzman, J., & Matthews, W.J. (2014). Excess Success for Psychology Articles in the Journal Science. PLoS One 9(12), e114255.
- Rossi, J. S. (1990). Statistical power of psychological research: What have we gained in 20 years? Journal of Consulting and Clinical Psychology, 58(5), 646-656.
Si quieres, también puedes aprender algo sobre la lógica del contraste de hipótesis y el error de muestreo en los posts anteriores de esta serie.
