Hola de nuevo. Ya tenía ganas de ir actualizando el blog, pero este año pandémico tan extraño nos está llevando a todo el mundo al borde del colapso, y atesoramos cada minuto de estar tumbado al sol como si fuera oro. Aun así, siempre me gratifica volver al mundo de la estadística y de las simulaciones, así que aquí llega este nuevo post de verano tardío.
En posts anteriores, aprendimos que los datos y resultados estadísticos se pueden presentar visualmente de distintas maneras: con tablas, y con figuras de distinto tipo. También dijimos que las figuras de barras, un clásico al que todos recurrimos frecuentemente, tienen algunos problemillas (¿recordáis aquello del #barbarplot?). Básicamente, cuando estas figuras están recogiendo un estadístico como la media o la mediana, nos están privando de conocer los detalles de la distribución de los datos, que puede ser muy importante para interpretar el resultado. Y además, tampoco nos dicen nada acerca de la precisión de la medida. Vamos, que contienen únicamente un resumen muy básico de los datos.

Una manera de enriquecer las figuras de barras es añadirle unas barras de error (realmente, no siempre se le llama “barra de error”, pero vamos a dejarlo por ahora). La barra de error nos va a marcar un intervalo alrededor del estadístico que está recogiendo el gráfico (usualmente la media), para que lo utilicemos en nuestra interpretación (*). Por ejemplo, si miráis las siguientes dos gráficas correspondientes a dos experimentos, ¿cuál os parece que ha encontrado la diferencia más clara entre los dos grupos? ¿cuál creéis que ha logrado mayor precisión en la medida? Aunque no os estoy dando de momento información básica sobre las barras de error, diríamos que el experimento de la izquierda ha sido más preciso y ha encontrado diferencias más evidentes entre los grupos, porque los intervalos marcados por las barras de error son menores. ¿Verdad?
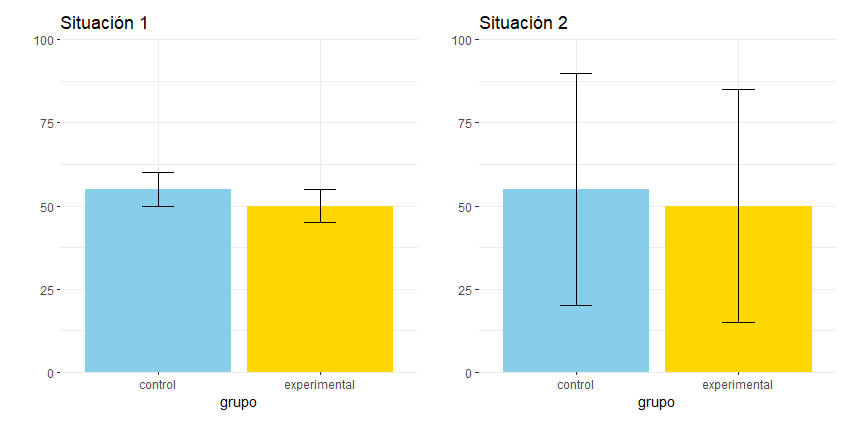
Bueno, pues aunque esta interpretación ha sido sencilla, realmente el trabajo con las barras de error puede ser bastante más complicado, y es de lo que vamos a hablar en el post de hoy.
¿Qué tipo de barras de error empleamos?
Si estás elaborando un gráfico de barras como los de este post, una de las preguntas que tienes que hacerte es qué estadístico debería recoger la barra de error. Y es que hay al menos tres opciones muy extendidas (que te ofrecen en casi cualquier paquete estadístico), y cada una se interpreta de manera diferente: desviación típica (en inglés, standard deviation, SD), error típico de la media (standard error of the mean, SE o SEM), e intervalo de confianza (IC). Además para tomar esta decisión, también es importante saber cuál es el objetivo del gráfico: informar acerca de los datos de la muestra (descripción) o ayudar en el contraste de hipótesis (inferencia).
Paso a paso. Vamos a empezar asumiendo que tu objetivo al hacer la figura es puramente descriptivo: quieres representar tus datos, y simplemente dar toda la información necesaria para que esa información sobre la muestra se comprenda bien. ¿Qué opciones tenemos?
Opción 1. Barras de error con desviación típica (Standard Deviation, SD)
Si la media o la mediana son estadísticos de centralidad (nos dicen en qué valores está centrada la distribución de los datos), la desviación típica es un estadístico de dispersión (nos dice en qué medida los datos se alejan de ese centro de la distribución). Una barra de error que contiene la desviación típica nos está diciendo, por lo tanto, cómo de dispersos están los datos alrededor de la media muestral.
No soy aficionado a poner ecuaciones, pero en este caso, vamos a hacer una excepción. La desviación típica de la muestra (SD) se calcula así:

Si examináis esta ecuación, su estructura os recordará a la de la media aritmética: en el numerador sumamos una serie de elementos, y luego lo dividimos por el total de elementos (n). Y es que, en realidad, la desviación típica no es más que un promedio. En concreto, es el promedio de las diferencias entre cada dato (xi) con respecto a la media muestral. Tal vez ahora se entiende por qué este estadístico sirve para medir la dispersión de los datos. Cuanto más alejados están, en promedio, los datos de la media muestral, mayor es la desviación típica.
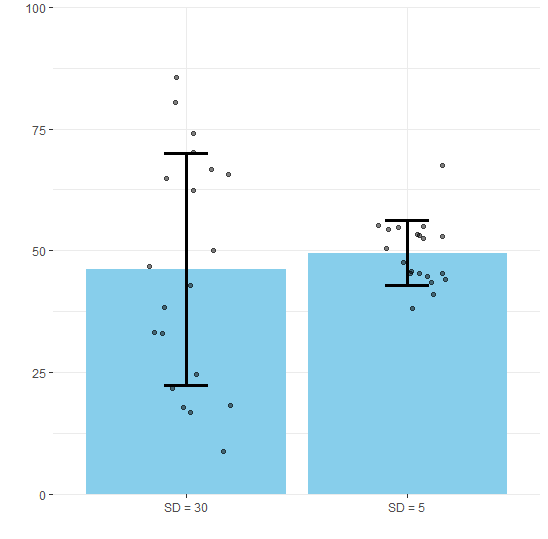
Una vez calculada, podemos usar la desviación típica en nuestra figura: las barras de error cubren el intervalo de dos desviaciones típicas, una por encima y otra por debajo de la media. Aquí tenéis un ejemplo de cómo quedarían dos barras de error con distribuciones más o menos dispersas (SD = 30 y SD = 5). He sobreimpuesto los datos reales a la figura en forma de puntos, para que apreciéis en qué consiste esa dispersión. Cada punto es un dato: ¿notáis cómo cambia la distribución alrededor de la media?
Opción 2. Barras de error con error típico de la media (Standard Error of the Mean, SEM)
Si la desviación típica mide la dispersión en los datos, con el error típico de la media (SEM) vamos a expresar una idea un poco diferente. Sabemos (porque lo hemos visto en el blog, aquí) que cada vez que repetimos un estudio, el resultado va a ser un poquito diferente, debido al llamado error de muestreo. Si tu medida es buena (tu muestra es grande, tus instrumentos precisos), entonces no va a haber demasiada variación entre muestreo y muestreo, sino que las medidas serán bastante consistentes. Pues bien, el SEM nos va a aproximar cómo de precisa o consistente es la estimación de la media poblacional a partir de la media muestral.
La fórmula para calcular el error típico de la media (SEM) sería la siguiente:
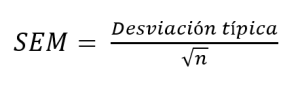
O sea, que si los datos están muy dispersos (desviación típica grande) o si la n es muy pequeña, tendríamos una SEM grande, es decir, estimaciones poco precisas de la media poblacional.
Entonces, cuando veáis una figura con el error típico de la media en las barras de error, tenéis que comprender que nos están transmitiendo algo acerca de la calidad del estudio: cuanto más pequeño el intervalo que cubre la barra de error, más precisión.
Opción 3. Barras de error con intervalos de confianza (CI)
Sin embargo, la mayoría de las veces el objetivo de nuestro estudio no se reduce a estimar un parámetro poblacional como la media. Muy a menudo queremos poner a prueba hipótesis: ¿funciona este tratamiento? ¿hay diferencia entre estos dos grupos? Es decir, nuestro objetivo, más que descriptivo, es inferencial. Para esos casos puede ser recomendable que nuestras barras de error contengan el intervalo de confianza (recuerda lo que era, y cómo interpretarlo, en este post).
El cálculo del intervalo de confianza es algo más complejo, aunque aún es sencillo como para hacerlo a mano, y de nuevo serviría como una medida de la precisión de nuestro estudio. Cuando el intervalo es muy grande, indica que el estudio ha sido poco informativo.
La ventaja del intervalo de confianza es que podemos escoger un nivel de confianza (generalmente, la costumbre es usar el 95%). La interpretación, aunque un poco engañosa, es directa: si repitiéramos el estudio 100 veces, 95 de los intervalos de confianza contendrán la media poblacional (esto ya lo hemos visto, recuerda este post).
Imaginad que estáis viendo un gráfico con los resultados de un experimento: ¿cómo saber si la diferencia entre dos grupos es significativa? Realmente, deberíamos hacer un test en condiciones (en este caso podría ser apropiada una prueba t), y calcular un p-valor. Si el p-valor es menor de 0.05, el resultado es significativo y concluimos que las diferencias son lo bastante grandes como para no atribuirlas al azar (recuerda cómo se interpreta un p-valor en este post previo).
Pero, más allá de hacer el test pertinente, la figura también puede ayudarnos en el contraste de hipótesis gracias a los intervalos de confianza (**). Si los intervalos de confianza al 95% para las dos medias no se solapan el uno con el otro, podemos decir que la diferencia entre esas dos medias es significativa al nivel p = 0.05.
¿Y si hay un poco de solapamiento entre los intervalos? ¿Diríamos entonces que la diferencia no es significativa? No necesariamente, y aquí es donde hace falta un ojo entrenado. Si el solapamiento es menor de la cuarta parte del del intervalo (o sea, la mitad de uno de sus brazos), entonces la diferencia todavía puede ser significativa, aunque esta regla solo vale para muestras mayores de n = 10 (Cumming et al., 2007) y para contrastes entre grupos independientes (***). La siguiente figura está tomada de ese artículo, y representa visualmente esta idea:
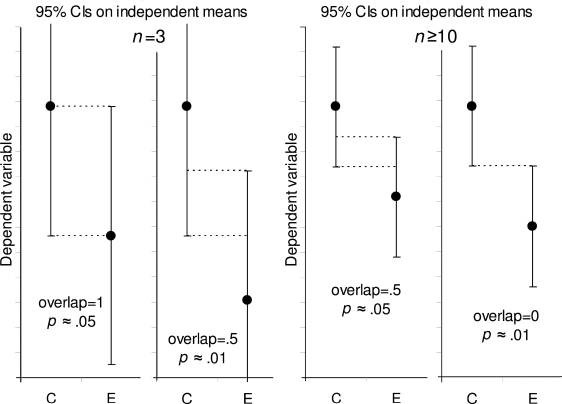
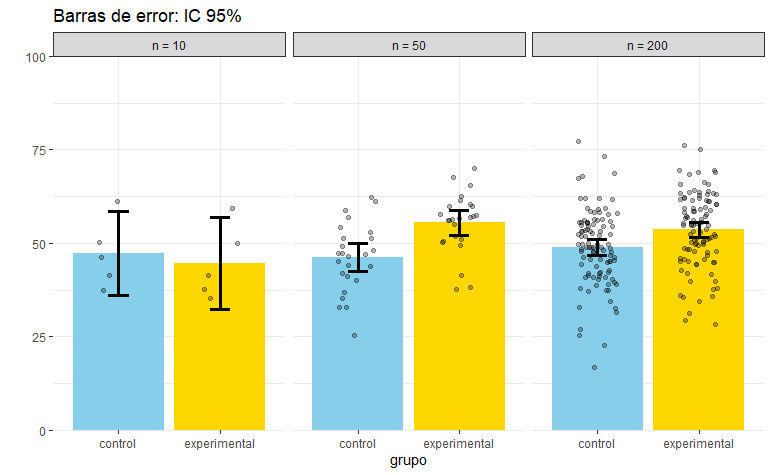
A continuación, os enseño un ejemplo con datos simulados. He extraído tres muestras de distinto tamaño a partir de dos poblaciones (experimentales y controles). En la muestra de la izquierda (n = 10, es decir, 5 participantes por grupo), los intervalos de confianza están muy solapados, lo que indica que esa diferencia no es significativa. No lo es, de hecho, si hacemos el test correspondiente, t(8) = 0.43, p = 0.68. Sin embargo, al aumentar la muestra podemos incrementar la potencia, es decir, la probabilidad de observar el efecto buscado si es que este existe. Como podéis ver, en la muestra de la derecha (la más grande) los intervalos se han vuelto más estrechos y apenas se solapan, indicando que la diferencia es significativa. Así lo corrobora el test: t(198) = 3.35, p = 0.001.
En cualquier caso, esta comparación visual no debería reemplazar al test propiamente dicho, que tiene en cuenta otras consideraciones, y en ocasiones nos puede llevar a conclusiones diferentes. Es simplemente una ayuda para que el gráfico pueda contar una historia. En el próximo punto veremos cómo podemos exprimir el potencial de los intervalos de confianza con otra visualización diferente.
Mientras tanto, quiero que veáis una cosa. Hemos comentado antes que error típico de la media (SEM), intervalo de confianza (CI) y desviación típica (SD) tienen significados diferentes, y ahora estamos en situación de comprobarlo.
En la siguiente simulación he generado tres muestras a partir de la misma población. Las tres muestras difieren en su tamaño: pequeño (n= 5), mediano (n=25), y grande (n=100). Ahora, he representado las medias de cada muestra con las tres opciones para las barrar de error que hemos comentado en el post: desviación típica (SD), error típico (SEM) e intervalo de confianza al 95% IC).

¿Notáis algo raro cuando nos movemos de una muestra pequeña (izquierda) a otra más grande (derecha)? Si os fijáis bien, veréis cómo las barras que contienen el error típico y el intervalo de confianza (SEM y CI) se hacen más estrechas cuando aumentamos la muestra. ¿Qué significa esto? Pues que estos dos estadísticos, aunque tengan interpretaciones diferentes, nos informan acerca de la precisión en la estimación (en este caso, de la media poblacional). Cuanto mayor es la muestra, mayor precisión, y por lo tanto intervalo más estrecho.
Sin embargo, los intervalos construidos con la desviación típica permanecen bastante insensibles al aumento del tamaño muestral. ¿Por qué? Porque simplemente indican en qué medida los datos están dispersos, y esto es algo que no tiene por qué correlacionar con el tamaño muestral.
Opción 4. Tamaño del efecto e intervalo de confianza
Por último, vamos a comentar una opción bastante diferente, pero que tiene otras ventajas. Imaginemos que el objetivo del gráfico no es simplemente representar los datos, sino comunicar la presencia (y magnitud) de un efecto estadístico, de forma que nos ayude en el contraste de hipótesis. Es decir, el propósito del mismo no es meramente descriptivo, sino inferencial.
Antes hemos comentado cómo pueden usarse los intervalos de confianza al 95% para intuir decisiones sobre la significación, siempre que se cumplan algunos supuestos. Ya os avisé de que este examen visual no debe reemplazar al análisis estadístico, porque ambas estrategias (examen gráfico y test) están trabajando sobre informaciones diferentes. En concreto, el examen visual trabajaba con la precisión de las estimaciones de las medias, mientras que el test, con su p-valor, está haciendo algo distinto: está cuantificando la magnitud de la diferencia, y diciéndonos si es esperable por azar.
¿Cómo podríamos hacer un gráfico que transmitiese esta información? La respuesta nos la da Geoff Cumming (2013), con su famosa propuesta de “The New Statistics” (aunque de nueva tiene poco). Lo primero que hay que hacer es calcular el tamaño del efecto observado. Puedes repasar este post anterior donde se explica qué es el tamaño del efecto. En el caso de dos grupos independientes, el tamaño del efecto estandarizado (con un estadístico llamado d de Cohen) se obtiene al restar las dos medias y dividir el resultado por la desviación típica de ambos grupos (en realidad, hay varias fórmulas ligeramente diferentes para distintas situaciones). Este tamaño del efecto observado es una estimación del tamaño del efecto “real”, el que existe en la población. Como todas las estimaciones, contiene un margen de error, así que nos gustaría expresar esta incertidumbre por medio de alguna guía visual, como un intervalo de confianza. Es exactamente el punto donde habíamos empezado el post de hoy.
Entonces, necesitamos construir un intervalo de confianza alrededor del tamaño del efecto observado que nos diga cómo de precisa es la estimación. Esto tiene un poco más de complicación, pero numerosos paquetes estadísticos nos simplifican el trabajo. El resultado sería algo como lo que sigue:

Quizá os recuerde este tipo de figura a las que solemos encontrar en los meta-análisis (forest plots). En general la interpretación es similar. Fijaos en que en vez de representar las medias muestrales y sus intervalos, estamos presentando directamente la diferencia entre cada par de medias (estandarizada), y el intervalo de esa diferencia.
Usando los datos simulados de antes, estoy representando los tamaños del efecto en tres muestras: pequeña, mediana y grande. Si os fijáis, los tres intervalos contienen el valor real del tamaño del efecto en la población (d = 0.30). No es extraño, porque si están correctamente elaborados, el 95% de los intervalos contendrán ese valor. Además, los intervalos varían en su amplitud.
La primera muestra (a la izquierda) ha producido un tamaño del efecto cuyo intervalo de confianza es muy ancho debido a la poca precisión de las muestras pequeñas. El intervalo que he representado, [-1.54, 0.97], incluye el cero. Esto sí lo podemos interpretar como un efecto no significativo, p > 0.05. Siempre que el intervalo no capture el cero, podremos decir que el efecto no es significativo.
Sin embargo, los intervalos calculados para las muestras de tamaño mediano [0.46, 1.73] y grande [0.19, 0.76] no incluyen el cero, así que están produciendo resultados significativos, como corroboramos al hacer los test pertinentes. Es decir, al presentar la información de esta manera, el examen visual nos permite sacar conclusiones sobre nuestras hipótesis: si hemos detectado el efecto o no.
Más aún: existe otro uso (menos conocido) de estos intervalos, y es el de evaluar la potencia del estudio, aunque sea de manera aproximada y a posteriori. Imaginad que nuestro estudio fuera el de la muestra pequeña (a la izquierda). Suele ser peliagudo interpretar un resultado no significativo, ya que no sabemos si (a) realmente el efecto que buscamos no existe, o si por el contrario (b) el efecto sí existe, pero no lo hemos detectado porque el estudio era poco potente. ¿Y ahora qué hacemos? Aunque no es la solución perfecta, sí puede ser informativo elaborar un gráfico como el de arriba. Si lo hacemos, comprobamos cómo el intervalo de confianza al 95% contiene un rango enorme de valores: desde efectos muy grandes (d = 0.97) hasta efectos gigantescos en la otra dirección (d = -1.54). En definitiva, esto sugiere que, independientemente del resultado que hayamos encontrado y del p-valor, el estudio ha sido poco informativo. Habría que plantearse repetirlo con una muestra más grande. Por lo general, este es un uso de los intervalos de confianza que no veo a menudo, y que puede ser muy útil en ciertas situaciones. Mucho mejor que otras opciones como las que comenta en este post Daniel Lakens.
Conclusiones
Espero que en este post hayamos aprendido algunas cosas. La primera, que los gráficos de barras, cuando representan estadísticos de centralidad como la media, deberían ir acompañados de barras de error. En segundo lugar, hay varias formas de obtener barras de error y cada una tiene una interpretación diferente. Un gráfico con barras de error que no especifica qué está representando acaba siendo inútil. Si haces un gráfico de barras, tendrás que escoger el estadístico más apropiado para cada situación (generalmente, los intervalos de confianza al 95% son la opción más útil).
Por último, si tu interés es mayormente inferencial (comunicar si un resultado es estadísticamente significativo o no, o si los datos van en línea con una hipótesis dada), entonces puede ser recomendable presentar un gráfico con una medida del tamaño del efecto observado junto con su intervalo de confianza. No sólo estás comunicando de manera efectiva la decisión con respecto al contraste de hipótesis, sino que puedes hacerte una idea de cómo de potente o informativo ha sido el estudio.
Notas
(*) Nota: De todas formas, incluso usando las barras de error correctamente, los gráficos de barras siguen teniendo problemas. En este link lo explican muy bien.
(**) Nota: Hay que andarse con un poco de cuidado, porque los intervalos de confianza, en según qué situaciones, podrían no ser simétricos (es decir, centrados en la media).
(***) Nota: los intervalos construidos con el error típico de la media (SEM) también se pueden utilizar en el contraste de hipótesis, aunque es un poco más difícil de leer hasta que te acostumbras. Por ejemplo, para que un resultado sea significativo, necesitas que los intervalos SEM estén completamente separados y haya entre ellos un hueco de como mínimo la extensión de medio intervalo.
Referencias
- Cumming, G., Fidler, F., & Vaux, D. L. (2007). Error bars in experimental biology. The Journal of cell biology, 177(1), 7–11.
- Cumming, G. (2013). The New Statistics: Why and How. Psychological Science, 25(1), 7-29.

Hola, qué aplicación usas para hacer estos gráficos??
LikeLike
Utilizo el paquete ggplot para R.
LikeLike
has compartido el código por algún medio?
LikeLike
Hola, quería agradecer tú labor por este post. Llevo varios días intentado comprender algunos conceptos y no lo he conseguido hasta que he encontrado esta página. Me ha resultado de gran ayuda para mi TFG. Gracias!
LikeLike
Hola, muy interesante! Sería posible conseguir el código de R con el que creaste los gráficos? Un saludo.
LikeLike
Estaba buscando en internet cómo entender mejor las notas de presentación en los colegios particulares pagados chilenos. Di con esta calculadora que me explicó perfectamente cuánto necesitaba para quedar eximido del examen final anual hoy. Ingresé mis notas del primer y segundo semestre con sus porcentajes y el resultado fue completamente preciso y claro. Me ahorró una conversación incómoda con mi apoderado y pude planear mi estudio con mucha más claridad ese año escolar. Una herramienta muy útil y gratuita para cualquier estudiante chileno que quiera entender su situación académica real: http://calculadoradenotas.cl/
LikeLike