
Volvemos con nuestro curso de estadesteca mal, repasando todas las prácticas incorrectas y los conceptos equivocados que plagan la estadística en psicología. Porque ya lo sabes, si a menudo piensas que estás metiendo la pata cuando haces o interpretas un análisis estadístico, esta serie de posts es para ti.
En el post de hoy vamos a hablar de un concepto que ya ha ido saliendo en entregas anteriores, el famoso p-hacking. Vamos a definir el concepto, usando algunos ejemplos, y vamos a visualizarlo mediante simulaciones en R.
No todos los resultados son iguales
Lo primero que tenemos que recordar es que cuando hacemos un estudio, el resultado puede ser significativo (p < 0.05) o no significativo (p > 0.05).
Si el resultado es significativo, tenemos dos opciones:
- O bien es un verdadero positivo, y por lo tanto estamos rechazando la hipótesis nula (la de que no hay efecto) correctamente.
- O bien es un falso positivo, y mi conclusión de que el efecto que estoy observando no se debe al azar es errónea.
Ya sabéis que la probabilidad de encontrar un resultado significativo cuando el efecto existe realmente (verdadero positivo) depende de la potencia, porque lo hemos hablado en posts anteriores (aquí y aquí). Si somos cuidadosos diseñando nuestro estudio, podríamos alcanzar por ejemplo una potencia del 80%. O sea, que si el efecto es real, lo detectaré (resultado positivo) en el 80% de los casos.
La otra situación es más peliaguda. En el caso del falso positivo, el resultado ha sido significativo “por casualidad”. Este tipo de error, el falso positivo, o error Tipo 1 para los amigos, es el que generalmente queremos mantener muy a raya, ya que es particularmente problemático (lo conocimos en este post anterior). Si, por ejemplo, afirmo que una medicina puede tratar una enfermedad y resulta que me equivocaba, estaré poniendo en riesgo las vidas de miles. Por eso fijamos el umbral de significación en p = 0.05, para que el falso positivo, en principio, nunca suba del 5%. …Hoy vamos a ver cómo se puede incrementar esta tasa de error de la manera más tonta.
Pero bueno, como no hay manera de diferenciar un falso positivo de un verdadero positivo, cuando tu estudio es significativo, date por satisfecho/a: ya puedes publicarlo. Enhorabuena.
Por su parte, si el resultado no es significativo, p > 0.05, deberíamos concluir que no podemos descartar que el efecto observado se deba al azar. Como antes, este resultado también puede ser:
- Un verdadero negativo: es decir, realmente no existe el efecto que estaba buscando.
- Un falso negativo: el efecto existe, pero mi estudio no ha sido capaz de detectarlo. Generalmente esto sucede cuando la potencia es insuficiente (repasad el concepto aquí).
Como veis, hay cierta asimetría en esta situación. Cuando el resultado es significativo, nos ponemos contentos porque podemos afirmar que hemos “encontrado algo”, y corremos a publicarlo. Cuando el resultado no es significativo, por el contrario, siempre tendremos la incertidumbre de cómo interpretarlo: ¿es un verdadero negativo, o simplemente me ha faltado potencia? Y además, debido al conocido como “sesgo de publicación” (que os cuento en este post), si el resultado no es significativo es muy difícil que lo publique en ninguna revista. Si no hay publicación, no hay beca, no hay financiación, no hay trabajo. Y qué duro es acer la cencia (Cientefico, 2017).

Empeñados en encontrar una diferencia significativa
En esta situación, no es raro que hayamos desarrollado hábitos que, de una manera u otra, consiguen que un resultado no significativo se convierta en significativo. Ojo, me refiero a prácticas que no constituyen en sí un fraude o una manipulación deliberada de los casos, o al menos no en todos los casos. Pueden ser técnicas muy inocentes y sutiles que aplicamos de manera incluso automática.
Estas prácticas se conocen como p-hacking: “torturar” los datos de distintas maneras hasta que p se vuelve menor de 0.05 (Ioannidis, 2005, Simmons et al., 2011). Las distintas prácticas de p-hacking son tan extendidas y tienen un aspecto tan inocente que os van a resultar familiares. Algunas de ellas son:
- Añadir más participantes a la muestra si vemos que p está cerquita de la significación.
- Excluir outliers o casos extraños (repasad este post sobre los outliers, si queréis).
- Introducir una variable moderadora o una covariable que no estaba prevista. Las clásicas son edad y género.
- Probar a analizar un subconjunto de los datos originales: por ejemplo, sólo las mujeres, o sólo las personas de menos de 50 años, o sólo quienes hayan puntuado en el cuestionario por debajo de un umbral…
- Cambiar de técnica de análisis. Por ejemplo, si tu modelo de regresión con la edad como variable predictora no acaba de funcionar, podrías cambiarlo por una prueba t en la que comparas jóvenes vs. mayores, tras aplicar un punto de corte arbitrario.
En definitiva, se trata de tener la flexibilidad suficiente para ir probando y, al final, escoger el análisis que más nos conviene para presentar un resultado significativo.
Pero vamos a ver: ¿Quién no ha echado un ojo a los datos una mañana y ha decidido que va a meter unos pocos participantes más de los previstos? ¿Quién no ha probado a introducir en el modelo una covariable para “limpiar los resultados”? Esto lo hemos hecho todos. Sólo ahora empezamos a entender que estas prácticas tan extendidas pueden suponer un problema severo (Head et al., 2015).
¿Cómo de severo es el problema? Pues veréis, generalmente, estás técnicas no aparecen de forma aislada, sino que se usan una tras otra, hasta conseguir un resultado significativo. La consecuencia es que el error Tipo 1, la probabilidad de obtener un falso positivo, se incrementa notablemente. Por ejemplo, simplemente combinando algunas de estas técnicas, podemos llegar a un % de falsos positivos ¡de más del 60%! (Simmons et al., 2011) ¿Cómo te quedas?
En el resto del post, vamos a intentar entender cómo el p-hacking puede distorsionar los resultados, mediante algunas simulaciones en R que van a representar una de estas prácticas más inocentes.
Simulando el p-hacking con R
Imaginemos el siguiente escenario. Dicen que escuchar música clásica mejora la inteligencia de los bebés (el “efecto Mozart”, Campbell, 1997), así que ¿por qué no funcionaría el mismo principio en adultos? Además, vamos a imaginar que mi teoría dice que este efecto es acumulativo, y es más potente cuantas más notas musicales haya captado mi oído.
Por lo tanto, inspirándonos en nuestra película de cabecera, “La Naranja Mecánica”, hemos creado un método de administración de música clásica “express”. Este método consiste en, simplemente, ponerse unos auriculares y escuchar en bucle las obras completas de Mozart a una velocidad 1000 veces más rápida de la normal. A esta velocidad los violines suenan como una ametralladora de explosiones de neutrones, pero bueno, sigue siendo Mozart. La idea es que, a lo largo de una sesión de dos horas, la exposición a música clásica habrá sido de tal calibre que tendremos que ver ese efecto en la inteligencia.
Así que vamos a probar el procedimiento con un experimento: a la mitad de los participantes, al azar, les tocará exponerse a la música clásica, mientras que a la otra mitad, que hará de control, le pondremos un popurrí de disco de los 70 y trap, también a toda pastilla. Al acabar la sesión, todos harán una prueba de inteligencia, para que podamos comparar los dos grupos.
¿Tiene sentido el experimento? No tenéis que decir que sí, porque da un poco igual. El caso es que, como las sesiones son un poco largas, cada día puedo testar nada más que unos pocos participantes, 3 ó 4. Y como soy un impaciente, al final de cada día voy a mirar qué pinta tienen los datos. ¿Qué es lo que descubriré?
Comenzamos con el código de R que va a reproducir este escenario. Vamos a empezar especificando los parámetros de la simulación. Por ejemplo, al fijar las medias poblacionales de los dos grupos con el mismo valor, 50, estamos diciendo que el efecto que está buscando el experimento no existe en la población (o sea, que el método de tortura auditiva no funciona). Vamos a asumir que el primer día que miro los datos tengo 10 participantes, 5 en cada grupo, y que a partir de ahí hago el experimento a 4 participantes nuevos al día (2 en cada grupo).
Copiad este código en la consola de R y ejecutadlo.
######
parámetros de la simulación:
######
grupo1.n <- 5 #La N de cada grupo el primer día
grupo2.n <- 5
Upperlimit <- 100 #Límites superior e inferior de la variable que estoy midiendo (CI).
Lowerlimit <- 0
grupo1.mean <- 50 #La media poblacional de CI en cada grupo
grupo2.mean <- 50
grupo1.sd <- 10 #Desviación típica poblacional del CI en cada grupo
grupo2.sd <- 10
RealD <- (grupo1.mean-grupo2.mean) / sqrt((grupo1.sd^2 + grupo2.sd^2)/2) #Este es el tamaño del efecto “real”, en la población.
nAdded <- 2 #Incremento de n en cada vuelta
nReps <- 30 #Número de veces que vas a p-hackear
Ahora necesitamos hacer las funciones que forman la simulación. Para ello, simplemente ejecutad este código:
#Función que hace las simulaciones...
runSims <- function(){
grupo1.data <<- round(rtruncnorm(n=grupo1.n, a=Lowerlimit, b=Upperlimit, mean=grupo1.mean, sd=grupo1.sd),0)
grupo2.data <<- round(rtruncnorm(n=grupo2.n, a=Lowerlimit, b=Upperlimit, mean=grupo2.mean, sd=grupo2.sd),0)
ttest <- t.test(grupo1.data, grupo2.data)
sims <<- data.frame(
sample = 0,
meanG1 = mean(grupo1.data),
meanG2 = mean(grupo2.data),
sdG1 = sd(grupo1.data),
sdG2 = sd(grupo2.data),
n = length(grupo1.data)+length(grupo2.data),
t = as.numeric(ttest$statistic),
d = (mean(grupo1.data)-mean(grupo2.data))/
(sqrt(
((grupo1.n-1)*var(grupo1.data)+(grupo2.n-1)*var(grupo2.data))/(grupo1.n+grupo2.n-2)
)),
p = round(ttest$p.value, 8),
sig = ifelse(ttest$p.value<0.05, "yes", "no")
)
}
#Función para hacer p-hack...
pHack <- function(){
for(i in 1:nReps){
grupo1.data <<- c(grupo1.data, round(rtruncnorm(n=nAdded, a=Lowerlimit, b=Upperlimit, mean=grupo1.mean, sd=grupo1.sd), 0))
grupo2.data <<- c(grupo2.data, round(rtruncnorm(n=nAdded, a=Lowerlimit, b=Upperlimit, mean=grupo2.mean, sd=grupo2.sd), 0))
ttest <- t.test(grupo1.data, grupo2.data)
simsNew <- data.frame(
sample = i,
meanG1 = mean(grupo1.data),
meanG2 = mean(grupo2.data),
sdG1 = sd(grupo1.data),
sdG2 = sd(grupo2.data),
n = length(grupo1.data)+length(grupo2.data),
t = as.numeric(ttest$statistic),
d = (mean(grupo1.data)-mean(grupo2.data))/
(sqrt(
((grupo1.n-1)*var(grupo1.data)+(grupo2.n-1)*var(grupo2.data))/(grupo1.n+grupo2.n-2)
)),
p = round(ttest$p.value, 8),
sig = ifelse(ttest$p.value<0.05, "yes", "no")
)
sims <<- rbind(sims, simsNew)
}
}
Ya estamos preparados. Vamos a ver qué tal se nos ha dado el primer día de trabajo en el laboratorio. Para ello, simplemente teclead en la consola runSims(). El resultado de mi experimento está guardado en la variable sims, y en mi caso tiene este aspecto*.
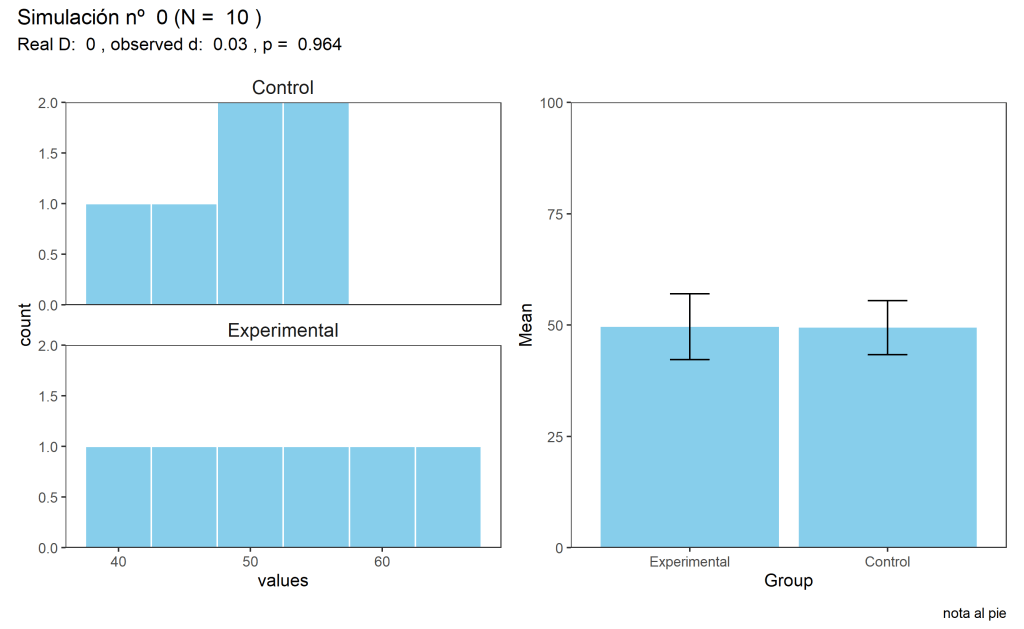
sims[1,]
sample meanG1 meanG2 sdG1 sdG2 n t d p sig
0 49.60 49.40 7.40 6.07 10 0.05 0.03 0.96 no
¡Qué decepción! Tras haberme pegado un curro de pasar 10 participantes, la cosa no pinta bien. Las medias muestrales son muy parecidas (49.60 vs. 49.40), lo cual indica que el procedimiento express no funciona. La diferencia no es significativa, p = 0.96.
Pero recordad lo que dijimos antes. Nunca podemos estar seguros de si un resultado negativo es un *falso* negativo. Igual es simplemente que me falta potencia, ya que tengo muy poquitos sujetos todavía. Voy a volver al trabajo, a ver qué sucede mañana. …Y aquí tendría la simulación correspondiente al segundo día, con una N=14):
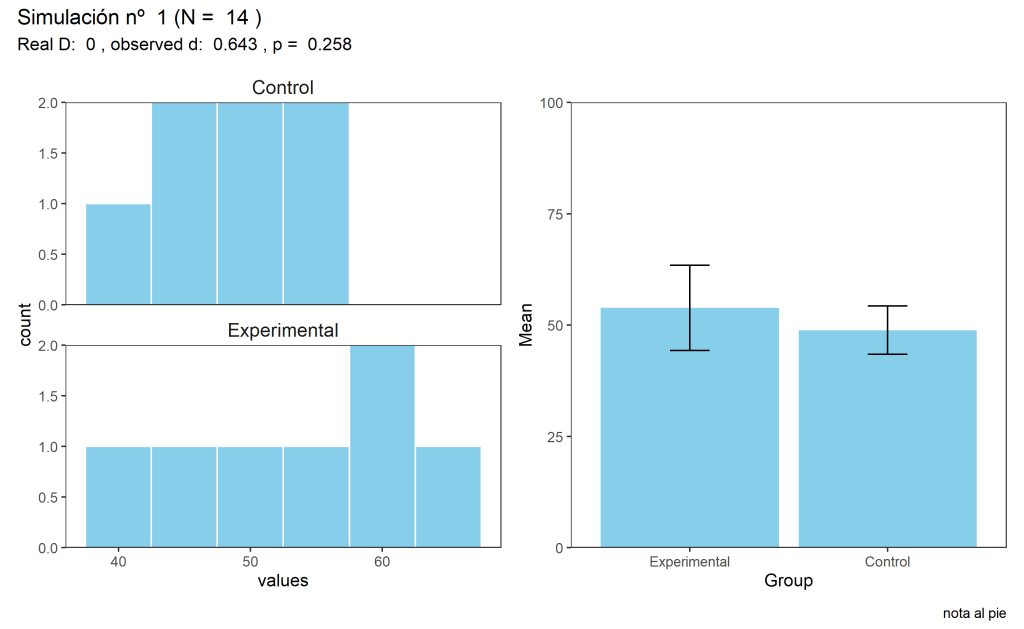
sims[2,]
sample meanG1 meanG2 sdG1 sdG2 n t d p sig
1 53.86 48.86 9.56 5.43 14 1.20 0.64 0.26 no
Todavía nada significativo, p = 0.26, pero oye, quien quiere creer acaba viendo al fantasma: ¿pues no está ligeramente más alta la media del grupo experimental? Son datos “prometedores”. ¡Merece la pena insistir!
En eso que sigo dejándome las pestañas con el experimento, y llega el tercer día, cuando me encuentro con esto:

sims[3,]
sample meanG1 meanG2 sdG1 sdG2 n t d p sig
2 54.44 44.78 8.80 10.08 18 2.17 1.021 0.046 yes
¡¡¡Sí!!! ¡Lo sabía! Era cuestión de insistir, el que la sigue la consigue. Ahora que tengo una muestra más grande, de 18 participantes, mi resultado es significativo: p = 0.046. ¡Ya puedo invitar a todo el laboratorio a una cena, e ir escribiendo el paper para contar el resultado.

PARA. EL. CARRO.
Vamos a ver, Fernando, ¿es que no te acuerdas de todo lo que hemos hablado sobre el falso positivo? ¿Cómo sabemos que este resultado no es uno de esos que salen por azar?
Pensémoslo un poco. Hasta llegar al tercer día en el que descorchamos el champán, ¿cuántos p-valores hemos calculado? Uno por día, o sea, tres veces. Bueno, pues resulta que los p-valores tienen sus manías, y una de las reglas que hay que seguir para interpretarlos es que sólo hay que calcularlos una vez. Si cambio algo, si echo o incluyo a un participante, si meto una variable más… estoy distorsionando el significado de ese p-valor, inflando la tasa de falso positivo (error tipo 1) por encima del 5%.
En este ejemplo (tan habitual por otro lado), el problema está en lo que se llama reclutamiento con parada opcional (“optional stopping rule”). En vez de fijar un tamaño muestral desde el principio, simplemente voy recogiendo datos, y me detengo sólo cuando el resultado concuerda con mis expectativas (cuando es significativo).
Este procedimiento en sí está condenado a producir un resultado positivo, tarde o temprano. Siempre que el resultado no es significativo al final del día, lo que hago es meter unos pocos sujetos más y darle otra oportunidad. Así, podría pasarme mucho tiempo, muchos días, y acabar encontrando que cualquier conjunto de datos aleatorio va a dar una p < 0.05.
Para visualizar mejor dónde estaba el engaño, vamos a representar el “viaje” que han hecho los p-valores a lo largo de los días que ha durado mi experimento (aquí represento un total de 30 días):

Si me hubiera detenido en el día 3, o en el 5, estaría convencido de que el estudio ha funcionado. Pero como he continuado recogiendo muestra hasta los treinta días, puedo ver claramente que aquello fue un espejismo.
Podríamos creer que los p-valores son educados y se comportan de forma predecible, pero ya veis que no. Bajo la hipótesis nula, todos los valores de p son igual de probables, y con muestras pequeñas se comportan de forma más bien errática: al principio no encontramos un resultado significativo, hacia el tercer día por pura casualidad los p-valores son más pequeños… pero si sigo recogiendo muestra, ya veis cómo hacia el día 9 vuelven a subir.
A la derecha, como propina, tenemos el mismo trayecto, pero ahora con la estimación del tamaño del efecto, la d de Cohen. Dado que el efecto real es 0, todos esos valores que vemos ahí son sobrestimaciones, a veces muy grandes, del efecto real. Conforme añadimos muestra y se contiene el error de muestreo, la d observada en cada día se va acercando al valor real.
¿Qué es lo que habría que hacer para evitar esta forma sutil de p-hacking? Idealmente, hay que especificar el tamaño muestral a priori, antes de recoger los datos. Y nunca ampliar la muestra una vez que ya la he analizado.
Conclusión
Estamos empezando a entender que podemos alterar totalmente las conclusiones y los resultados de un estudio, de maneras muy inocentes y casi sin darnos cuenta. Sólo con introducir unos pocos participantes más puedo estar inflando la tasa de falso positivo significativamente. Próximamente seguiremos reflexionando sobre otras formas de p-hacking, y sobre sus consecuencias.
Referencias
- Campbell, D. (1997). The Mozart Effect: Tapping the Power of Music to Heal the Body, Strengthen the Mind, and Unlock the Creative Spirit. New York: Avon Books
- Cientefico, El. (2017). La cencia no se ace sola, ahi que acerla. Joyitas del Tuiter.
- Head, M.L., Holman, L., Lanfear, R., Kahn, A.T., Jennions, M.D. (2015). The Extent and Consequences of P-Hacking in Science. PLoS Biology, 13(3), e1002106.
- Ioannidis, J.P. (2005). Why most published research findings are false. PLoS Medicine, 2(8), e124.
- Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant. Psychological Science, 22(11), 1359–1366.
*NOTA: como siempre que hacemos simulaciones, cada vez que ejecutemos el código el resultado cambiará, porque los números se han generado aleatoriamente. Si quieres comprobarlo, ejecuta otra vez el código. Y otra más.
