
Hola de nuevo. Últimamente no me da la vida para actualizar el blog, pero tenía muchas ganas de retomarlo para hablar de algo que nos ha pasado a todas las personas que por algún motivo u otro trabajamos en investigación. Seguro que una de las siguientes situaciones os es familiar:
Situación A: Por fin has diseñado tu estudio. Lo has tenido todo en cuenta: selección de los mejores instrumentos, control de variables… Todo pinta bien. Sin embargo, ahora tienes que planear cómo vas a llevarlo a cabo. Y esto implica, entre otras cosas, decidir el tamaño de tu muestra. Claro, una muestra grande siempre es preferible, pero a menudo no es posible por motivos prácticos. ¿Bastará con 20 participantes? ¿Quizá necesites algunos más? Si el estudio no sale significativo, no podrías descartar que ha sido por la falta de muestra. Entonces, ¿merecería la pena esforzarte para llegar a los 200 participantes, o será demasiado? ¿¿Cómo vas a tomar esta decisión??
Situación B: Acaba de llegarte la carta de decisión de una revista científica. El editor te invita a reenviar tu manuscrito, siempre que respondas a los comentarios de los revisores, especialmente ese Revisor 2 tan pesado. Resulta que el Revisor 2 te pide que justifiques el tamaño muestral de tu estudio. Claro, podrías contestarle la verdad, que no tenías ninguna justificación a priori para el tamaño muestral, que únicamente reclutaste participantes hasta que te parecieron “suficientes”, a ojo. Pero no es eso lo que te pide el revisor. Te está pidiendo que hagas un “análisis de potencia a priori” (a priori power analysis). ¿Qué es eso? No tienes ni idea de cómo contestar y has entrado en pánico. ¡HALLUDA!
En este post vamos a hablar de análisis de potencia, y vamos a aprender cómo salir de estas dos situaciones tan comunes y, en ocasiones, angustiosas.
Refrescando conceptos
Antes de empezar, conviene recordar algunos conceptos básicos que ya hemos tratado en este blog: tamaño muestral, tamaño del efecto y potencia estadística.
El tamaño muestral (N) es, simplemente, la cantidad de puntos de datos que reúnes para tu estudio. Por ejemplo, si estás haciendo una encuesta y cada pregunta se la haces una sola vez a cada participante, tu tamaño muestral es el número de respuestas contestadas, o sea, el número de participantes que han respondido.
El tamaño del efecto es la magnitud del efecto, es decir, de la diferencia (si estás comparando grupos o variables), o de la asociación entre dos variables. Por ejemplo, si vas a comparar un grupo experimental con un grupo control, un tamaño del efecto grande significa que los dos grupos son muy diferentes en la variable estudiada. Conviene distinguir entre el tamaño del efecto “real” o poblacional (que hace referencia a la población y por lo tanto es desconocido, y lo asumimos estable), y el tamaño del efecto “observado” o muestral (que es la diferencia o la asociación obtenida en tu estudio concreto, y por lo tanto puede variar si lo repites, debido a las fluctuaciones del error de muestreo).
Por último, la potencia estadística es la probabilidad de obtener un resultado significativo (p< 0.05) en un estudio o conjunto de estudios, asumiendo que el efecto poblacional existe, o sea, asumiendo que es mayor de cero. Cuanta más potencia, más probabilidad de obtener un resultado significativo. Si te dicen que un estudio tiene una potencia de, por ejemplo, 0.80, esto quiere decir que, siempre que el efecto exista, lo veremos el 80% de las veces que repitamos la medición (un 80% de “verdaderos positivos” frente a un 20% de “falsos negativos”). Un estudio de baja potencia (por ejemplo, de 0.20), por su parte, sólo produce resultado significativo el 20% del tiempo, y por lo tanto es poco eficiente (nada menos que el 80% de los resultados obtenidos son falsos negativos). (*)
Como hemos visto anteriormente, los tres conceptos están conectados (ver post anterior). Cuanto más grande es la muestra, o cuanto mayor es el tamaño del efecto, mayor potencia tenemos para verlo. Una vez que se comprende bien esto, la estadística cobra nuevo sentido, y evitamos desastres como el de utilizar muestras ridículamente pequeñas como para detectar el efecto con una probabilidad aceptable (ver este otro post sobre cómo insistir en hacer estudios de baja potencia puede sesgar la literatura).
Ahora que ya están las ideas claras y frescas en nuestras cabezas, vamos a pensar posibles soluciones a las situaciones que hemos presentado antes. Os recuerdo el dilema: ¿Cómo decidir el tamaño muestral para mi estudio (Situación A)?, o ¿Cómo justificarlo, si es que ya está hecho (Situación B)?
Opción 1. Decidir el tamaño muestral improvisando sobre la marcha (MAL).
Estoy convencido de que todos y todas hemos caído aquí alguna vez. Una estrategia tentadora, sobre todo cuando eres un impaciente o tus recursos son limitados, es la de ir recogiendo la muestra y, de vez en cuando, echando un vistazo a los datos para ver “cómo van”. Si, por ejemplo, tengo N=50 y el efecto no está ni se le espera (imagínate que calculamos el p-valor y es de 0.89, muy lejos de la significación), quizá me desanime y decida cancelar la recogida de datos. Ahora bien, si con la misma N=50 el p-valor está justito por encima del umbral (p = 0.061), seguro que hago un esfuerzo y le echo unos pocos participantes más.
Quizá esto te parezca una práctica inofensiva, pero en realidad es una forma más de hacerse trampas al solitario. Como vimos en un post anterior, cuando la muestra es pequeña, los estadísticos que calculamos a partir de ella fluctúan mucho al meter un dato más o menos, y esto se aplica también al p-valor. Así, no es raro obtener un resultado significativo totalmente espurio que se desvanece al incrementar la muestra. O dicho de otra manera: si sigues este procedimiento de calcular el p-valor y continuar con la recogida de datos cuando es mayor de 0.05, al final está garantizado que vas a obtener un resultado significativo, ¡aunque sea por puro azar! Os recuerdo esta figura (del post anterior) que lo ilustra: si cada día introducimos dos datos nuevos, y cada día calculamos el p-valor, “el viaje” que este va haciendo hasta estabilizarse puede ser de infarto.

De hecho, es justamente por este motivo por el que el revisor de la Situación B te ha pedido que justifiques tu tamaño muestral. En teoría, si calculamos un p-valor tenemos que seguir unas reglas. Y entre estas reglas hay una muy básica que dice que el tamaño muestral se decide antes de recoger los datos, no sobre la marcha, en función de los resultados obtenidos.
Pues bien, lección aprendida. No usaremos la opción 1.
Opción 2. Decidir el tamaño muestral “a ojo”.
La segunda opción es también muy popular, y menos maligna que la anterior, aunque también tiene sus peligros. No es raro que a veces decidamos el tamaño muestral en función de lo que nos parece “razonable”. Por ejemplo: ¿Cuál es la N de estudios similares que se han publicado ya? También hay quien usa reglas de andar por casa, como “tiene que haber veinte sujetos por celda, mínimo” (esta la he escuchado yo infinidad de veces).
El problema con esta aproximación es que, al no basarse en un argumento razonado y detallado, corre el riesgo de simplemente repetir como un zombi los errores del pasado: “Si a Fulanito le publicaron su estudio con N=25, a mí me tiene que funcionar con el mismo tamaño muestral”, o “Este efecto no existe porque he hecho tres experimentos con N=20 y en ninguno de ellos ha salido el resultado significativo”. Ambas conclusiones son erróneas: puede ser simplemente que los estudios estén muy faltos de potencia dado el tamaño del efecto que estás buscando, y de ahí el resultado no significativo.
Y es que no hay que olvidar que, como hemos dicho, tamaño del efecto, potencia y tamaño muestral son tres conceptos conectados. Así, no tiene mucho sentido decidir el tamaño muestral sin pensar en cuál es el efecto que estoy buscando, o qué probabilidad de detectarlo deseo asegurar.
Moraleja: no hay un tamaño muestral “apropiado” que sirva para todas las situaciones ni momentos. Dependerá, entre otras cosas, del efecto que quieras buscar, y también de cuestiones prácticas. Así que la opción 2 también hay que descartarla.
Opción 3. Lo que te pide el revisor (y también está MAL casi siempre): análisis de potencia “a priori”.
Y llegamos a la opción estrella, que me he encontrado numerosas veces en las cartas de los revisores o como recomendación de las propias revistas, y hasta en algunas guías de buenas prácticas. Es lo que llaman el análisis de potencia a priori. ¿En qué consiste y por qué está mal casi siempre que se aplica?
El análisis de potencia a priori es un protocolo para decidir el tamaño muestral que, a diferencia de los anteriores, sí se basa en la información correcta. Es decir, dependerá del efecto que estés buscando y de cuánto quieras arriesgarte a tener un estudio fallido.
Entonces, lo que deberías hacer según este protocolo es:
–Paso 1. Examina la literatura para estimar el tamaño del efecto más probable para este fenómeno. Por ejemplo, puedes buscar un meta-análisis donde informen del tamaño del efecto, o bien simplemente promediar los efectos que vas encontrando sobre el tema. Imagina que así llegas a la conclusión de que el tamaño del efecto probable para tu fenómeno es d = 0.81. O sea, un efecto muy grande.
–Paso 2. Decidimos un nivel de potencia que sea aceptable para nosotros. Generalmente, por convención, se suele fijar al 80% o 90%. Esto significa que si repetimos el estudio 100 veces, el efecto será significativo en 80 ó 90 de estos intentos, que no está nada mal. Si me conformase con una potencia del 50%, ¡hacer el estudio sería como lanzar una moneda al aire! Mejor no bajar del 80%.
–Paso 3. Conocidos los dos valores anteriores, estima la N requerida. Hemos dicho que potencia, tamaño muestral (N) y tamaño del efecto están conectados. Necesitarás mayor N cuanta más potencia quieras conseguir y menor sea el efecto que quieras observar. Por lo tanto, si asumimos que el efecto “real” (poblacional) coincide con nuestra estimación (d = 0.81), podemos calcular cuánta muestra (N) haría falta para obtener el resultado significativo con una probabilidad que hayamos fijado como aceptable (por ejemplo, del 80%).
Hacer los números no es complicado si usas la ayuda del software (como por ejemplo JASP, Jamovi, o el paquete pwr para R). Con este último método, sería tan fácil como teclear esto en vuestra terminal de R:
library(pwr) #Primero cargamos el paquete pwr.
pwr.t.test(power = 0.80, d = 0.81, sig.level = 0.05)
Y obtendríamos este resultado inmediato:
Two-sample t test power calculation
n = 24.9236
d = 0.81
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group
El cálculo me indica que necesito una muestra de 25 personas por grupo (N = 50) para detectar ese efecto de d = 0.81 con una probabilidad del 80%. O sea, que ya tengo una justificación adecuada para la muestra de mi experimento. ¡Ya puedo empezar el reclutamiento!
En realidad la lógica de este análisis no está mal, y en principio no tiene nada de malo hacerlo. Lo que pasa es que a menudo debemos aplicarla en un entorno real donde los investigadores e investigadoras no estamos siguiendo las reglas del juego, y por lo tanto aplicar el protocolo nos conducirá al error. Vamos a explicar por qué.
El primer problema de esta técnica es que, generalmente, la aplicamos cuando no debemos. Por ejemplo, en la Situación B descrita arriba. Y es que se llama análisis “a priori” porque se realiza, supuestamente, antes de recoger los datos. …Pero la realidad es que a menudo lo hacemos cuando nos lo pide el revisor, es decir, una vez recogida la muestra y analizados los datos. O sea, mal. Lo que el revisor quiere que le digas es que tu estudio (ya realizado) tenía la capacidad de detectar el efecto (estimado a partir de estudios previos). Pero si los datos ya están recogidos, lo único que puedes determinar es si tu muestra era lo bastante grande o no comparada con el cálculo que has hecho en el Paso 3. Eso es muy poco útil.
Pero hay más pegas. El problema está fundamentalmente en el Paso 1. Estamos dando por sentado que el efecto observado y reportado en la literatura nos da una estimación fiable, no sesgada, del efecto “real” en la población. Esto no es así. Como hemos visto en otros posts, el llamado “sesgo de publicación” hace que pasen a la literatura únicamente los resultados significativos, que son justo los que sobrestiman sistemáticamente el tamaño del efecto. Es decir, si te vas a la literatura publicada, verás efectos grandes como d = 0.81, d = 1.20…, que son exageraciones del efecto real, seguramente mucho más modesto. Los efectos pequeños como d = 0.05 no son significativos con muestras pequeñas, y por eso no se publican. Además, cuanto menor sea la muestra de los estudios, más probabilidad de que la sobrestimación sea muy grande. No en vano los efectos detectados en estudios de replicación con muestras enormes son generalmente más bajos que los estudios originales que intentan replicar (Camerer et al., 2018). ¡Ojo! Este sesgo puede afectar también a los meta-análisis, salvo que pongan algún tipo de medida para contrarrestarlo (mira este post donde lo explico).
Tomar como base para hacer la estimación del efecto poblacional (Paso 1) un “estudio piloto” puede ser una estrategia algo mejor. Un estudio piloto es, por lo general, muy similar al estudio definitivo que planeas realizar, pero con una muestra algo más pequeña, y tiene el objetivo de testar tus instrumentos de medida. Al menos te estarás basando en un dato que no ha pasado el filtro del sesgo de publicación. Sin embargo, tampoco es la mejor opción (Albers & Lakens, 2018), porque seguirás usando el efecto observado en tu estudio (en este caso, el piloto) como estimación del efecto poblacional, a pesar de que esta estimación puede ser muy deficiente, sobre todo con muestras demasiado pequeñas (y generalmente, los pilotos tienen muestras pequeñas). Es decir, seguirás confundiendo, en cierta medida, estadístico (muestra) y parámetro (población).
Una variante del proceso implica no trabajar con una estimación del tamaño del efecto en el Paso 1, sino con el “efecto más pequeño que sea de tu interés”. O sea: imagina que trabajas en el ámbito clínico, y tus motivaciones son prácticas. Un tratamiento que funcione, pero que suponga una mejora minúscula, inapreciable en la vida real, seguramente no merece la pena. Así, podrías por ejemplo decidir que no te interesa ningún efecto menor de d=0.40. Fijarías ese valor en el Paso 1, y decidirías un tamaño muestral que te permita ver efectos de ese tamaño (o mayor) con la probabilidad que decidas. En este caso, el análisis a priori estaría bien empleado, pero sigue presente el problema de decidir efectos son interesantes y qué efectos podemos ignorar.
En resumen, el análisis de potencia a priori es una herramienta que puede funcionar y proporcionar información útil… si la usamos cuando procede, es decir, antes de recoger los datos. Por desgracia, los revisores siempre la piden cuando los datos ya están analizados, y esto nos conduce al desastre.
Opción 4 (LA QUE DEBES PROBAR). Análisis de sensibilidad.
Con el tiempo, el análisis de potencia a priori ha acabado desaconsejándose, al menos como se usa habitualmente (es decir, mal). Quizá en un mundo perfecto, sin sesgo de publicación ni p-hacking, podríamos usarlo, siempre antes de recoger los datos, pero mientras tanto hay que pensar alternativas. Sin cambiar nada realmente esencial con respecto al anterior, el análisis de sensibilidad puede ser una buena opción para la mayoría de los casos cuando estés en la situación B.
Si has intentado hacer un análisis a priori de manera honesta, te habrás dado cuenta de lo enormemente difícil que es observar efectos pequeños. Por ejemplo, para ver una diferencia de d = 0.20 (un efecto que se considera “pequeño”) entre dos grupos con una potencia del 80%, necesitas nada menos que ¡786 participantes!
pwr.t.test(power=0.8, d = 0.2, sig.level = 0.05)
Two-sample t test power calculation
n = 393.4057
d = 0.2
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group

Realmente, esto es una cura de humildad. Parece que estamos condenados a estudiar efectos grandes que requieran menos medios, o bien a seguir jugando a la lotería con cada estudio (con potencias muy bajas para ver esos efectos). No podemos invertir miles de participantes en cada estudio que se nos ocurra, ¿verdad? ¿Habría alguna forma de tener en cuenta los aspectos prácticos y económicos en todo esto?
Pues bien, vamos a hacer un análisis de sensibilidad. Así es cómo deberíamos obrar, por lo menos si estuviéramos en la Situación B descrita más arriba:
-Paso 1. Vamos a fijar el tamaño muestral (N). Si estás en la Situación B, el estudio ya está hecho, así que la N es conocida. Si estás en la situación A, por lo menos puedes tener una idea acerca de qué cantidad de datos es factible recopilar. O sea, puedes decidir qué tamaño muestral te puedes permitir dados tus recursos económicos y temporales. Y es que no todo el mundo investiga en una universidad de la Ivy League ni tiene capacidad para recoger cien mil datos para su trabajo de fin de grado. Vamos a suponer que puedo permitirme recoger una N de 100 participantes. Hoy en día, con los procedimientos online, es un tamaño factible.
-Paso 2. Decide qué potencia quieres alcanzar. Es decir, cuánto estás dispuesto a arriesgarte a que el experimento produzca un “falso negativo”. Generalmente, si queremos hacer las cosas bien, fijaremos un nivel de potencia alto, como 80% ó 90%. Cualquier cosa por debajo de ahí ya es demasiado arriesgado.
–Paso 3. Calcula cuál es el tamaño del efecto más pequeño que puedes ver con su muestra, al nivel de potencia que has fijado. Como los tres conceptos están relacionados, una vez fijada la N y el nivel de potencia deseado, sabemos cuál es el efecto más pequeño detectable con tu experimento. Piensa en ello como si estuvieras usando una red para pescar. Los peces más pequeños que los agujeros de la red podrán escapar con cierta facilidad. El análisis de sensibilidad te dice qué tamaño tienen los peces más pequeños que puedes capturar con un nivel dado de seguridad (el 80% o el 90% de las veces).
Usando el paquete pwr, puedes hacer un análisis de sensibilidad en una línea:
pwr.t.test(power=0.8, n = 50, sig.level = 0.05)
Two-sample t test power calculation
n = 50
d = 0.565858
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group
Pues bien, si haces (o ya has hecho) tu estudio con N = 100 (o sea, 50 personas en cada grupo), tienes una probabilidad del 80% de ver un efecto d = 0.57 o mayor. Esto podría ser aceptable si piensas que el efecto que estás buscando es relativamente grande. Pero si sospechas que el efecto es pequeño, el análisis te está diciendo: “busca una red con agujeros más pequeños, porque se te van a escapar casi todos los peces menores de ese tamaño”.
El análisis de sensibilidad tiene más sentido antes de realizar el estudio (Situación A), pero, a diferencia del análisis a priori, puede usarse una vez recogida la muestra (Situación B), y por eso creo que puede ser una opción para contestar al revisor 2. Sin duda mucho mejor que hacer un “análisis a priori” que no es “a priori” de verdad, ¿no?

A veces, como complemento al análisis de sensibilidad, se pueden utilizar las llamadas “curvas de sensibilidad” o “curvas de potencia”. Es fácil calcularlas a partir de la información que proporciona el paquete pwr o con software como G*Power, y nos sirven para determinar cómo de potente puede ser un estudio en distintos escenarios.
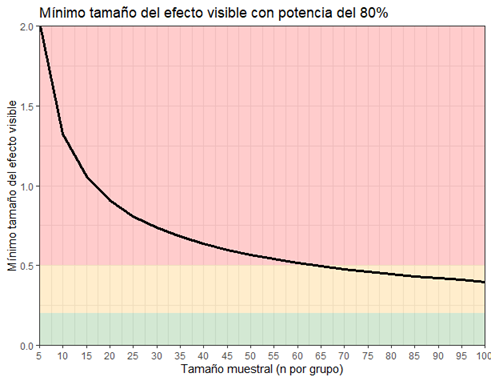
Esta sería la curva de sensibilidad que nos muestra el efecto más pequeño que podemos detectar con una potencia del 80% y diversos tamaños muestrales (desde 5 hasta 100 sujetos por grupo). Como veis, con 5 sujetos por grupo sólo pescamos los peces más grandes, o sea, efectos gigantescos de d=2.0 o más. Pero con 60 sujetos por grupo ya es posible detectar efectos medianos (d=0.50) la mayoría de las veces.
Otra forma en la que se puede presentar la misma información es la curva de potencia. Imaginemos que no sé muy bien qué tamaño tiene el efecto que busco. Podría ser grande (d>0.80), mediano (d=0.50), o pequeño (d<0.20), según las convenciones habituales. Así que voy a simular los tres escenarios, para ver con qué probabilidad podría detectar cada uno de estos tres efectos con mi muestra.
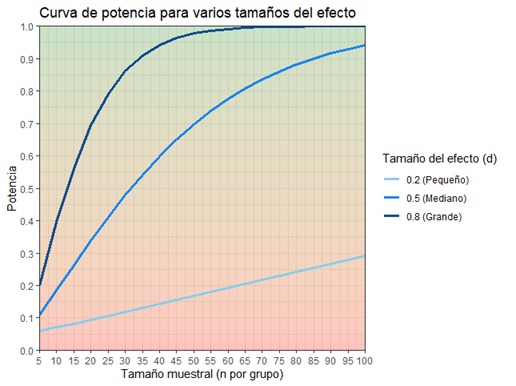
Como veis, la interpretación es la misma. Si mi muestra es pequeña (pongamos que recluto 10 personas por grupo), entonces tengo un 40% de probabilidad de detectar efectos grandes (d=0.8), un 20% de probabilidad de detectar efectos medianos (d=0.50), y nada más que un 7% de probabilidad de detectar efectos pequeños (d=0.20).
Estas figuras me pueden servir para tomar decisiones que involucran toda la información necesaria, además de aspectos prácticos: si, por ejemplo, me es posible reclutar 100 participantes, pero la ganancia en términos de potencia no compensa, quizá me arriesgue a reclutar 80 y reserve los recursos para otro fin. Mirando la curva puedo ver cuánto gano y cuánto pierdo por estas decisiones.
Conclusiones
¡Me ha quedado un post largo y no hemos hecho más que rascar la superficie!
Evidentemente hay más opciones por explorar para dar respuesta al atribulado investigador que se encuentre en la Situación A o en la Situación B. Por ejemplo, en la primera situación (antes de recoger los datos), podríamos emplear un plan de muestreo secuencial (Lakens, 2017), fijar un objetivo de precisión (Rothman & Greenland, 2019), o aprovechar la acumulación de evidencia que permiten los Bayes Factors (Schonbrodt et al., 2015). Por su parte, una vez recogida la muestra (Situación B), también tenemos opciones para contestar al revisor, como simplemente dibujar un intervalo de confianza alrededor del efecto observado en la muestra, de forma que describes cómo de informativo ha sido tu estudio.
En definitiva, todo un mundo de posibilidades, que no se agota en las prácticas más habituales que hemos empleado casi todos los investigadores (las Opciones 1, 2 y 3 que hemos descrito).
(*) Vamos a suponer para este post que el umbral de significación es p = 0.05, como es habitual en Psicología.
