En un post anterior estuvimos definiendo qué es un intervalo de confianza, y adelantamos que va a ser una herramienta útil en el contexto del análisis de datos. Vamos a profundizar un poco en este tema, aprovechándonos de una genial visualización interactiva realizada por Kristoffer Magnusson, que tenéis en este enlace:
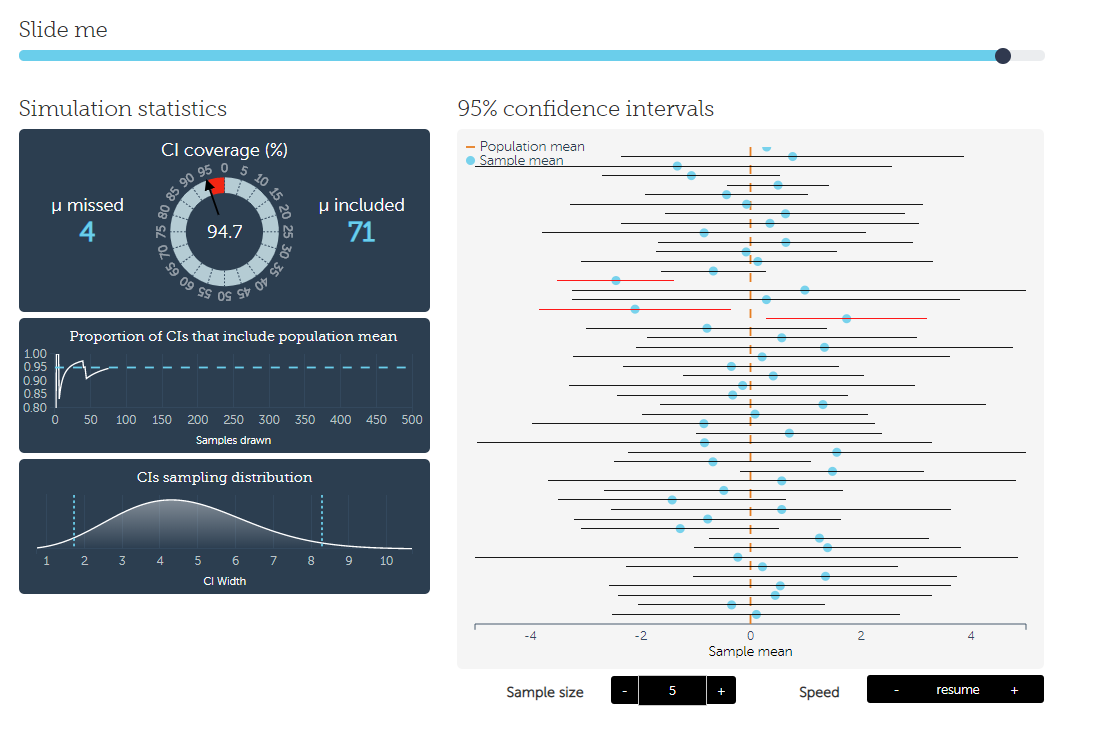
Esta visualización está basada en la misma idea que la simulación del otro día: Es un proceso de muestreo aleatorio, aunque esta vez lo han implementado en una web interactiva, de modo que podemos juguetear con los valores y ver cómo cambian los intervalos.
En esencia, aquí tenemos una media poblacional que se representa con esa línea naranja vertical. Podéis imaginar que es cualquier cosa, por ejemplo, el porcentaje real de estudiantes que detesta la estadística, o el número promedio de horas que la gente pasa viendo series cada semana. En cualquier caso, este es el parámetro de la población que, en nuestra práctica científica, desconocemos, y que nos gustaría estimar con nuestro estudio.
Desde que la cargamos, la web va a ponerse a simular en tiempo real cientos de muestras a partir de esa población. Las vemos moviéndose hipnóticamente por la pantalla. Para cada muestra, la web nos calcula su media muestral (el punto azul) e intervalo de confianza. Podemos ver fácilmente cómo las medias obtenidas en cada muestra son un poco diferentes, y casi nunca coinciden perfectamente con la media poblacional. Gracias al post anterior, sabemos que esto se debe al error de muestreo, que introduce este ruido aleatorio en la medida.
En cuanto a los intervalos de confianza, estos van a contener dentro de sus límites el valor real de la población casi todo el tiempo (de hecho, el 95% de las veces, si no tocamos nada en la simulación). Cuando el intervalo no contiene a la media, aparece resaltado en color rojo. Además, el panel izquierdo de la simulación nos lleva la cuenta del número de intervalos que capturan la media real, para que comprobéis que a la larga va a coincidir con el nivel de confianza (en el ejemplo de la imagen de abajo, el porcentaje real de intervalos que incluyen la media real es de 94.7%, muy cerca del objetivo de confianza deseado, 95%):
Ahora que hemos repasado los elementos de esta visualización, podemos empezar a jugar un poco con los parámetros de la simulación para ver cómo afecta esto a las estimaciones. Así que ve a la web, trastea un poco, y cuando te hayas cansado vuelve aquí para seguir leyendo.
¿Ya estás de vuelta? Seguimos.
Por defecto, en esta simulación los intervalos de confianza están fijados al nivel del 95%, que es lo habitual en ciencias como la psicología, pero podemos cambiarlo a otros niveles, como el 99% o el 90%, que se usan en otras situaciones. Si fijamos un valor de confianza elevado, el intervalo se volverá más amplio. Si por el contrario fijamos un valor más pequeño, como por ejemplo un 10%, o un 20%, el intervalo se acortará. ¿Por qué?
El nivel de confianza representa el porcentaje de estos intervalos que, a largo plazo, acabarán conteniendo el valor del parámetro. Es decir, si los intervalos de confianza están calculados al nivel del 95%, el 95% de ellos contendrán el valor real de la media poblacional. Si nos volvemos más liberales y fijamos una confianza del 90%, los intervalos serán más pequeños y sólo el 90% de ellos contendrán el valor de la media poblacional. De hecho podéis comprobar que esto es así mirando el panel izquierdo en la simulación (ese 94.7% de la imagen de arriba se aproxima mucho al nivel de confianza, al menos cuando hemos generado un número muy grande de muestras). Aquí se puede entender el sentido de la palabra “confianza” en este contexto frecuentista: si repito el proceso de muestreo aleatorio un número infinito de veces, puedo estar seguro de que el 95% (o el 90%, o el nivel que escoja) de esas muestras va a tener un intervalo de confianza que contiene a la media poblacional. Sí, lo sé, el lenguaje se vuelve raro en cuanto lo toca un matemático.
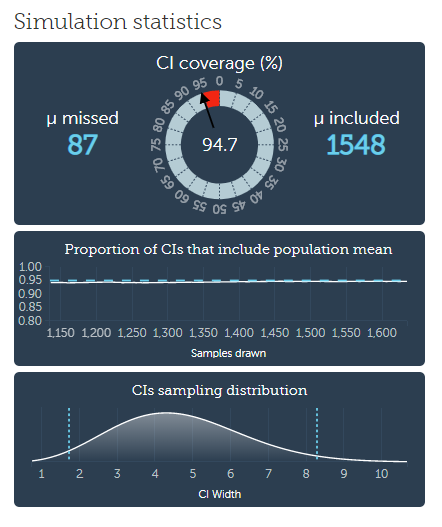
Otro parámetro que podemos alterar en esta simulación para ver qué ocurre es el del tamaño muestral. En el post anterior vimos cómo el número de datos de cada muestra (la n) afectaba a la calidad de la estimación. No es lo mismo tomar una decisión a partir de un estudio con muchos participantes que tomar de referencia un estudio sobre una muestra pequeña, ¿verdad? Y de nuevo el responsable de esto es el error de muestreo: su impacto, aunque aleatorio, será más relevante sobre las muestras pequeñas. Bien, probad ahora a hacer que las muestras sean más grandes, por ejemplo, de 100 participantes:

Como veis, a partir de ese momento (cuando he cambiado de n=5 a n=100), las medias muestrales han dejado de alejarse tanto de la media poblacional, y se han vuelto “menos bailonas”. También los intervalos de confianza se han vuelto más estrechos, lo cual se puede interpretar como un aumento de precisión en la medida. Aun así, a largo plazo, seguiremos teniendo la misma proporción de intervalos que no incluyen la media real (dependiendo del nivel de confianza que hayamos impuesto: si trabajamos al 95%, el 5% de los intervalos aparecerán en rojo porque no han capturado la media poblacional).
Cuidado, ¡los intervalos tienen trampa!
En ocasiones podéis leer interpretaciones del intervalo de confianza como un rango de valores “plausibles” para el parámetro poblacional. Por ejemplo, imaginad que hago un estudio para estimar la cantidad de horas semanales que pasa la gente en Netflix u otras plataformas, y obtengo una media muestral de 45 horas, con un intervalo entre 25 y 65 horas (un rango bastante amplio). Ya de entrada, podríamos descartar como “plausibles” algunos valores del intervalo: ¡probablemente nadie pase 65 horas delante de la televisión! Pero avancemos. Con estos datos, alguien podría afirmar que “hay una probabilidad del 95% de que el valor real de la media esté dentro de mi intervalo de confianza, es decir, entre 25 y 65”. ¿Os parece una buena conclusión?
De hecho, se trata de una interpretación bastante intuitiva del concepto, además de extendida (según Hoekstra et al., 2014, más del 50% de los estudiantes e investigadores la juzgan como válida). Pero en realidad la interpretación no es correcta, puesto que nos aleja de la estricta lógica frecuentista que subyace a la propia definición del intervalo. No perdamos de vista que el intervalo (como todo lo que calcule a partir de mi muestra) es siempre una estimación, y va a cambiar necesariamente si repito el estudio con una muestra nueva (debido, una vez más, al error de muestreo y otros factores).
Si en este ejemplo repito mi estudio, podría encontrarme con otro intervalo diferente, por ejemplo, 5-45, ó 58-98. No hay más que mirar de nuevo las simulaciones de la web para percatarse de cómo a partir de una misma población podemos extraer intervalos muy diferentes entre sí. Si queremos ser rigurosos, deberíamos abstenernos de hacer estas interpretaciones sobre un intervalo aislado, y nunca perder de vista el conjunto que nos ofrece la simulación que estamos viendo: cada muestra va a ser diferente, con una media diferente y un intervalo distinto, y sólo en el largo plazo estaremos seguros de que el 95% de los intervalos contiene el valor real.
Conclusiones
En primer lugar, la mejor manera de entender ciertos conceptos estadísticos es simularlos y visualizarlos. Recuerdo la de veces que, en clase, me hablaron de intervalos de confianza, ¡la de veces que los calculé! Y sólo cuando fui capaz de simularlos y observarlos en movimiento entendí realmente su utilidad… y por qué los interpretamos mal.
En segundo lugar, el error de muestreo (inevitable) nos va a generar incertidumbre en las estimaciones. No vale la pena resistirse, hay que aprender a asumirlo. Es normal, para eso está la estadística. Por otro lado, esto nos debería ayudar a entender que tenemos que ser críticos con los resultados de experimentos o estudios aislados. En vez de dar el dato por bueno, haría bien en echar un vistazo a la incertidumbre que lo acompaña (el intervalo de confianza, la n, y ya veremos más adelante el p-valor). Y en cualquier caso, interpretar un estudio aislado va a ser siempre complicado, pues el intervalo que hemos calculado no nos dice nada por sí solo (lo único que sabemos es que si calculamos otros 99, hasta tener 100, 95 de ellos van a contener la media real, y ni siquiera sabemos si el intervalo que tenemos delante es de ese díscolo 5% que no la contiene). Así que mejor repite ese estudio, a ser posible con una muestra grande, antes de sacar conclusiones definitivas.
Y por último, evitemos los malentendidos: los intervalos de confianza no son un concepto sencillo, a pesar de lo que parece, porque ofrecen interpretaciones intuitivas y fáciles que son, realmente, incorrectas. En este artículo (Hoekstra et al., 2014) detallan algunas de las interpretaciones erróneas más comunes, y podemos ver que hasta los que nos dedicamos a la investigación caemos en la trampa, así que está bien tenerlo en cuenta: no te confíes con los intervalos de confianza, que son traicioneros.
Referencias
Hoekstra, R., Morey, R. D., Rouder, J. N., & Wagenmakers, E. J. (2014). Robust misinterpretation of confidence intervals. Psychonomic Bulletin & Review, 21(5), 1157-1164.
