
Hay que ver cómo es la estadística y cómo somos capaces de hacer e interpretar análisis complejos… y a la vez que no nos entren en la mollera algunos conceptos básicos. Así de engañosa es. Uno de esos conceptos que se nos atragantan constantemente es el de los intervalos de confianza. ¡Madre mía, las vueltas que le habremos dado! Crees que lo tienes claro, y al cabo de un tiempo, venga otra vez a preguntar por lo mismo. Y venga a mirarlo en la Wikipedia. No hay manera. Vamos a ver si de una vez por todas dejamos asentado este concepto tan resbaladizo, o al menos lo vamos a intentar de una manera diferente, con visualizaciones y simulaciones. ¿Me acompañáis?
¿Qué es un intervalo de confianza?
Hemos hablado de los intervalos de confianza en este blog (aquí, y aquí), con el objetivo de ilustrar el error de muestreo. Pero creo que nunca nos hemos metido a fondo con el concepto, cómo se calcula y cómo se visualiza. Habrá que ponerse las pilas.
A menudo usamos el concepto de intervalo de confianza en el contexto de problemas de estimación. Ya sabéis: ahí fuera, en el mundo real, hay una población que se define con un parámetro (por ejemplo, la edad promedio de todos los jugadores de rugby del mundo, o el máximo kilometraje alcanzado por un Ford Fiesta en todo el país… lo que queráis). Lo que sucede es que las poblaciones son taaaan grandes que son inaccesibles. No es práctico encuestar a todos los jugadores de rugby del mundo, o mirar el cuentakilómetros de todos los automóviles de España. Por eso los parámetros tienen valor desconocido.
Así que en vez de estudiar directamente los parámetros, los vamos a estimar a través de una muestra. En la muestra sí podemos conocer los estadísticos como la media, porque son de menor tamaño y fácilmente calculables. De este modo, podría reclutar por ejemplo 100 jugadores de rugby, y asumir que (si el muestreo está bien hecho), el promedio calculado a partir de la muestra nos ofrecerá una buena estimación del parámetro poblacional.
Es decir, podemos entender la estimación y el muestreo como “viajes” de ida y vuelta entre la población (cuyos parámetros desconocemos) y la muestra (cuyos estadísticos sí conocemos).

Lo que ocurre es que las estimaciones no son perfectas, hay incertidumbre. Puede ser que el estadístico de mi muestra no coincida con el valor del parámetro de la población. O que diferentes muestras de la misma población tengan estadísticos diferentes… Entre otras fuentes de incertidumbre, tenemos ese maldito error de muestreo que os expliqué alguna vez). Así que necesitamos alguna herramienta para comunicar la incertidumbre, y ahí entran los intervalos de confianza.
Un intervalo de confianza viene definido por dos valores (límite inferior y límite superior) que nos indican la incertidumbre que ha rodeado al proceso de estimación. Pero, ¿cómo se interpreta?
La confusa interpretación de un intervalo de confianza
Imaginemos que la edad promedio en nuestra muestra de 100 jugadores de rugby es de 28.5 años. Ese es el valor del estadístico, y también va a ser nuestra estimación del valor del parámetro poblacional. Ahora bien, sabemos que probablemente no serán exactamente iguales, debido al error de muestreo entre otras cosas. Por eso calculamos un intervalo de confianza.
Los intervalos se pueden construir con diferentes niveles de confianza. Generalmente, en psicología usamos intervalos del 95%. Pero son habituales también intervalos del 90% o del 99%. Luego comprobaremos las implicaciones de esta decisión.
Imaginemos ahora que el intervalo de confianza al 95% en este ejemplo va de 25.5 a 31.5 años. ¿Cómo interpretamos este intervalo?
En primer lugar, hay que fijarse en su anchura (en este caso, cubre un total de 6 años). Cuanto más ancho sea el intervalo, mayor incertidumbre en la estimación. Por eso, un intervalo estrecho nos diría que podemos aproximar con bastante precisión el valor del parámetro.
En segundo lugar, podemos interpretar el intervalo como que “hay un 95% de probabilidad” de que el parámetro poblacional esté entre 25.5 y 31.5. Ahora bien, esta interpretación tiene un poco de trampa, o mejor dicho, aunque sea en principio correcta es compatible con algunos errores muy intuitivos y traicioneros. Realmente, hay un 95% de probabilidad de que un intervalo de confianza al 95% contenga la media poblacional. Pero claro, cada intervalo concreto (como el nuestro, 25.5 – 31.5) o bien la contiene, o bien no la contiene, así que ya no es una cuestión de “probabilidad”. Vaya lío. Es que, al ser un concepto de inspiración frecuentista, para entender el intervalo de confianza hay que imaginar experimentos repetidos indefinidamente.
Por eso las explicaciones habituales del intervalo de confianza suelen plantearse tal que así: Imagina que obtienes 100 muestras aleatorias de esa población, y por lo tanto ahora tienes 100 intervalos de confianza. De esos 100, 95 contienen el parámetro buscado, la media poblacional… ¡Pero no sabes si este intervalo en particular pertenece al 95% que sí contiene la media, o al 5% que no la contiene! Es decir, ese 95% de confianza va asignado al procedimiento de cálculo de los intervalos: simplemente te garantiza que, a largo plazo, aproximadamente el 95% de los intervalos que construyas van a contener el parámetro. ¿Se entiende mejor así?
¿Cómo se calcula un intervalo de confianza?
Para entender bien el concepto, tenemos que comprender en primer lugar la intuición que tiene detrás. No obstante, también nos puede ayudar el echar un vistazo a cómo se calcula. ¿Nos ponemos con ello?
Siguiendo con los ejemplos que estamos viendo, un intervalo de confianza para la media poblacional se calcularía de la siguiente manera: vamos a definir un intervalo alrededor de la media muestral (conocida), cuyo tamaño va a depender de (a) el tamaño muestral (cuanto más grande, más estrecho será el intervalo porque la precisión de la estimación mejorará), (b) la dispersión de la muestra (cuanto menos dispersa, más precisión y menos anchura del intervalo), y (c) el nivel de confianza requerido (generalmente, como hemos dicho, 95%). Así, calculamos los dos valores que definen el intervalo, que son sus límites superior e inferior.

En estas fórmulas, sd es la desviación típica de la muestra (standard deviation), y n su tamaño. La constante va a depender de nuestro nivel de confianza deseado. Por ejemplo, para un intervalo de confianza al 95% será 1.96. ¿De dónde sale este número tan extraño, 1.96? Pues bien, es el correspondiente al punto de corte que abarca el 95% central de una distribución normal estandarizada.
Fijaos en cómo la desviación típica está en el numerador de la fórmula (a mayor desviación, más ancho será el intervalo), mientras que la n está en el denominador (a mayor n, menor intervalo). Esto será importante.
Sé que este punto es el más abstracto, aunque tampoco importa mucho si no lo comprendéis del todo. Lo que le estamos diciendo a la fórmula es: imagina una distribución normal estándar, centrada en una media de 0 y con desviación típica 1, y toma el 95% central de la misma (es decir, “corta en -1.96 y +1.96”). Esto valdría para cualquier ejemplo donde asumamos una distribución normal, porque aquí no hay unidades de ningún tipo. Por eso ahora solo falta “traducirla” a las unidades propias de nuestra aplicación, es decir, indicarle cuál es la media y dispersión de nuestra muestra. Por eso multiplicamos ese punto de corte, 1.96 en este caso, por el error estándar de la muestra (desviación típica / raíz cuadrada de n).

Aplicando las fórmulas, podemos calcular el intervalo deseado. Por ejemplo, imagina que en tu muestra de 25 jugadores de rugby el promedio de edad es de 27.3 años, con desviación típica de 2.1. Usando las fórmulas anteriores para un intervalo de confianza al 95%, nos da el resultado siguiente:
Límite superior: 27.3 + 1.96 * (2.1/raíz(25)) = 27.3 + 0.82 = 28.12.
Límite inferior: 27.3 – 1.96 * (2.1/raíz(25)) = 27.3 – 0.82 = 26.48.
Generalmente no vamos a aplicar la fórmula a mano, sino que vamos a usar software que calcule los intervalos por nosotros. Ahora vamos a automatizar el cálculo para permitirnos jugar un poco con R y con los intervalos. Para ello, ve a R y copia el siguiente código:
CI <- function(media, desvt, n, conf = 0.95){
LInferior <- media - abs(qnorm((1-conf)/2))*(desvt/sqrt(n))
LSuperior <- media + abs(qnorm((1-conf)/2))*( desvt /sqrt(n))
return(c(LInferior, LSuperior))
}
Este código(*) genera una nueva función personalizada que nos permitirá calcular intervalos de confianza dados unos estadísticos muestrales (media, desviación típica y n).
Por ejemplo, hagamos una prueba con una muestra de 20 jugadores de rugby cuya media muestral para la variable edad es de 29.7 años y su desviación típica 4.2. Teclead en la consola de R:
CI(media = 29.7, desvt = 4.2, n = 20, conf = .95)
O simplemente (ya que el programa asume que el nivel de confianza es del 95% por defecto):
CI(29.7, 4.2, 20)
…Que devuelve este resultado:
[1] 27.8593 31.5407
Es decir, que mi estimación para la media de edad poblacional es 29.7, con un intervalo de confianza al 95% de [27.86, 31.54].
Hemos dicho que la anchura del intervalo va a depender de varios parámetros del estudio, en concreto del tamaño muestral (n) y de la desviación típica. Vamos, por tanto, a imaginar que hemos obtenido una muestra con idéntica media muestral, 29.7, pero una desviación típica más pequeña que antes, de sólo 0.8.
CI(media = 29.7, desvt = .8, n = 20, conf = .95)
[1] 29.34939 30.05061
Fijaos cómo se ha reducido la anchura del intervalo de confianza [29.35, 30.05], indicando que hemos mejorado mucho la precisión. La media no ha cambiado, así que ambos intervalos están centrados en torno al mismo valor, 29.7 años.
Vamos a hacer otra prueba modificando el otro parámetro que podía afectar a la precisión de la estimación, el tamaño muestral. Imaginemos que la media muestral sigue siendo de 29.7 años y la desviación típica es de 4.2 años, pero la n es mucho mayor, de 200 personas en vez de 20:
CI(media = 29.7, desvt = 4.2, n = 200, conf = .95)
[1] 29.11792 30.28208
El aumento de muestra también se traduce en mayor precisión, y por tanto en intervalos más estrechos [29.12, 30.28].
También podríamos hacer pruebas cambiando el nivel de confianza, simplemente asignando otro valor entre 0 y 1 al parámetro “conf” (prueba con valores como .90, .99…). Pero creo que lo habéis entendido ya a estas alturas, así que os dejo esa prueba a vosotros y vosotras.

Imagina que calculas 100 intervalos…
Llegamos a la parte interesante.
Por último, vamos a hacer algunas pruebas más para acabar de entender bien este resbaladizo concepto. Ya hemos dicho que, con frecuencia, cuando nos explican qué es un intervalo de confizanza, nos invitan a imaginar qué pasaría si obtenemos 100 muestras de la misma población y calculamos sus 100 intervalos de confianza. Pues bien, ¿sabeis qué? Que no hace falta que lo imagines. Porque vais a hacerlo.
Bueno, por suerte no vamos a calcular los 100 intervalos a mano. Para eso tenemos R 🙂
Copia y ejecuta esta función en R para automatizar el proceso:
generaIntervalos <- function(MediaPob = 0,
DesvTPob = 1,
n = 50,
numMuestras = 100
){
SampleNames <-c()
SamplesM <- c()
SamplesUpper <- c()
SamplesLower <- c()
for(i in 1:numMuestras){
CurrentSample <-
rnorm(n,
mean = MediaPob,
sd = DesvTPob)
SampleNames <- c(SampleNames, paste0("Muestra", i))
SamplesM <- c(SamplesM, mean(CurrentSample))
SamplesLower <- c(SamplesLower, CI(mean(CurrentSample), sd(CurrentSample),n)[1])
SamplesUpper <- c(SamplesUpper, CI(mean(CurrentSample), sd(CurrentSample), n)[2]) }
return(
data.frame(
Muestra = SampleNames,
Media = SamplesM,
LInferior = SamplesLower,
LSuperior = SamplesUpper
)
)
}
La nueva función generaIntervalos() sirve para producir cuantos intervalos queramos a partir de la misma población de partida, inmediatamente. Pruébala si quieres.
Empezaremos decidiendo unos parámetros poblacionales de partida: ¿cuál es la media poblacional real? ¿y su desviación típica? Generalmente estos parámetros son desconocidos (¡precisamente por eso hacemos estudios y muestreos!), pero como esto es una simulación, vamos a imaginar que los sabemos. También habrá que decidir el tamaño de cada muestra, y cuántas muestras queremos extraer. Por ejemplo, teclea:
generaIntervalos(MediaPob = 25,
DesvTPob = 14,
n = 20,
numMuestras = 100)
Así obtendrás nada menos que 100 muestras aleatorias de 20 participantes cada una, obtenidas de la misma población, y sabiendo que los parámetros poblacionales que definen a esa población son media 25 años, y desviación típica 14 años.
Para facilitarte la interpretación, os voy a poner el resultado en una figura:
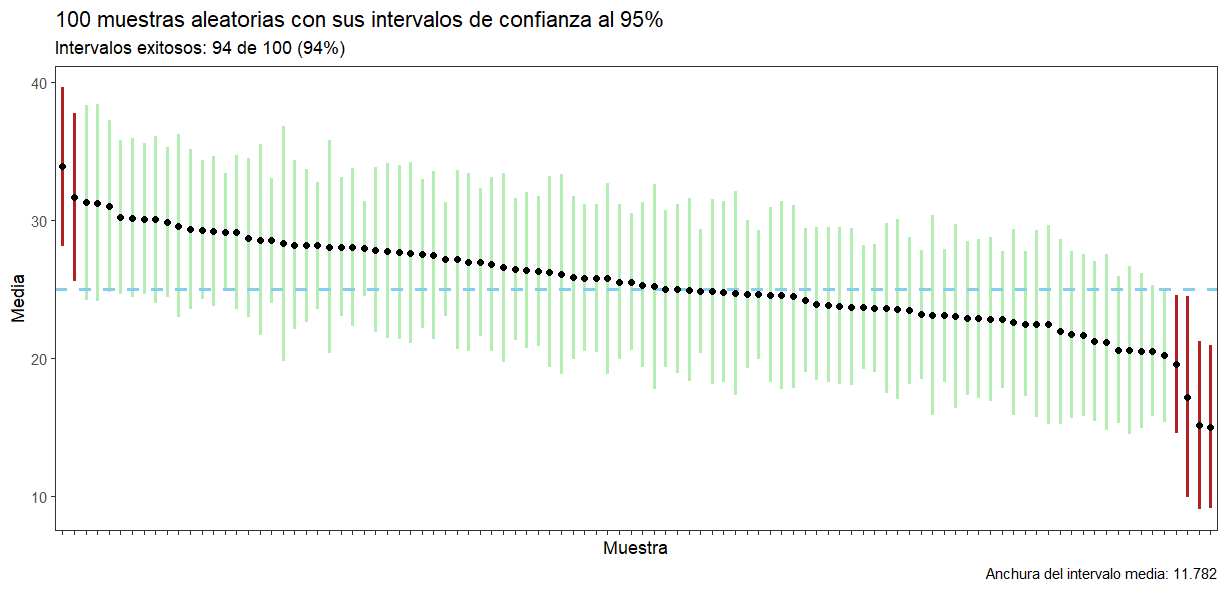
¿Qué vemos en esta simulación? Lo primero, dado que cada muestra es aleatoria, los estadísticos muestrales (media y desviación típica) van a fluctuar. Con ellos, como hemos dicho, cambian los intervalos de confianza al 95%. Unos van a ser más anchos y otros más estrechos, y también van a estar centrados en diferentes valores. ¡Cada vez que ejecutéis la simulación os van a salir resultados diferentes, como en la vida real cuando hacemos un estudio!
La cuestión es que, de estos 100 intervalos, 94 han capturado correctamente el valor poblacional para la media (que era 25 años, y está marcado con esa línea azul). Aunque a ti te salgan números diferentes, aproximadamente el 95% de los intervalos que calculemos contendrán la media poblacional, como habíamos prometido. Solo ahora, al haber hecho el esfuerzo de calcular esos 100 intervalos, podemos verlo con toda claridad. Si contemplamos cada uno de los intervalos de manera aislada, solo sabremos que este procedimiento produce intervalos exitosos (contienen el parámetro) el 95% del tiempo, pero NO SABREMOS SI UN INTERVALO EN CONCRETO LO CONTIENE O NO. ¿Se entiende ahora?
Por supuesto, podemos seguir jugando a cambiar parámetros en la simulación. ¿Y si nos da por reclutar muestras mayores? En vez de 20 participantes por muestra, vamos a reclutar diez veces más, 200:
generaIntervalos(MediaPob = 25,
DesvTPob = 14,
n = 200,
numMuestras = 100)

Como veis, hemos ganado en precisión porque ahora los intervalos son mucho más estrechos que antes. Sin embargo, no hemos cambiado el hecho de que el 95% de los intervalos (aproximadamente) van a contener el parámetro poblacional, ya que esta es una propiedad del procedimiento que hemos usado para calcularlos.
Ahora podrías seguir haciendo pruebas y jugando, que es como mejor se aprende, a cambiar detalles de la simulación. Puedes, por ejemplo, usar un nivel de confianza diferente (90%, 99%), o cambiar los parámetros poblacionales. A ver qué pasa.
Imagino que, si este post no os ha servido para afianzar lo que ya sabéis sobre los traicioneros intervalos de confianza, sí que os valrá al menos para que, la próxima vez que alguien os repita “Imagina que calculas 100 intervalos…” le respondáis: “No me hace falta imaginarlo, ya lo he hecho con R”. ¡Hasta la próxima, que espero que sea pronto!
(*) NOTA: el código obtiene el intervalo a través de una distribución normal. Cuando las muestras son pequeñas, conviene utilizar otra aproximación a través de la distribución t de Student. Así, habría que reemplazar la función qnorm(probabilidad) por qt(probabilidad, grados de libertad), siendo los grados de libertad n-1. Cuando la muestra es muy grande (es decir, los grados de libertad tienden a infinito), la distribución t se aproxima mucho a una distribución normal y los dos métodos producen idéntico resultado.
(**) NOTA 2: Cómo me habría gustado haceros una aplicación interactiva para este post. Lo he intentado gracias al paquete Shiny, pero como soy totalmente novato en ese tema y no me ha quedado redonda, lo dejaremos para otra ocasión. Sigo aprendiendo.
