Ya estoy aquí otra vez, dispuesto a revivir este blog. Y lo voy a hacer recuperando un debate que últimamente me he encontrado en mis respectivos entornos (el virtual, del salseo en Twitter y otras redes, y el profesional). Quizá os sea de ayuda este post para quienes tenéis entre manos algún tipo de análisis de datos (¿tu tesis doctoral? ¿tu TFM?) y estáis recibiendo mensajes un tanto contradictorios por parte de los “expertos” (tu director/a de tesis, la gente de los foros de estadística…). Vamos allá.
TL;DR: Por más que te digan lo contrario, necesitas teoría y conocimiento sobre tu tema de investigación para plantear e interpretar un análisis estadístico sin meter la gamba.
Imaginad esta situación que me he encontrado montones de veces, a ver si os suena. Una doctoranda ha trabajado duro recogiendo sus datos. Se ha currado los cuestionarios, el muestreo… Ahora tiene una tabla de datos enorme y aparecen algunas discrepancias con su director de tesis. Resulta que hay al menos dos maneras de analizar estos datos. Nuestra doctoranda propone un tipo de análisis que tiene en cuenta algunas posibles variables confundidas (entre allas el género, la edad y el nivel socioeconómico) y las controla. El director, por su parte, propone “simplificar” el análisis de cara al proceso de revisión, y dejar fuera del mismo las variables que no sean relevantes. El argumento del director es que el análisis es “más simple” y por lo tanto más sencillo de comprender. Además, el análisis sencillo nos permite dejar fuera nuestras opiniones subjetivas acerca de qué variables merece la pena controlar o no, y es más “objetivo” porque simplemente “deja hablar a los datos” (¿a que habéis oído esta frase más de una vez?). Y encima todo sale significativo <cheff kiss>. Nuestra doctoranda se rasca la cabeza y se preocupa un poco: pero, ¿cómo es posible que los dos análisis, tan diferentes en planteamiento, sean correctos? ¿Es que no debería haber una única manera correcta de analizar mis datos?
Y no es la única que se preocupa. Hace unas semanas, en Twitter, se popularizó este artículo (Breznau et al., 2022) en el que le envían el mismo set de datos a distintos equipos de investigación para que lo analicen, y encuentran una variabilidad enorme de modelos, técnicas de análisis y, por supuesto, resultados obtenidos. Mientras que algunos equipos llegaron a una conclusión, otros llegaron a la opuesta. Repito: están analizando los mismos datos.
La reacción del 90% de mi TL en Twitter: ¡el pánico! Es alarmante. Ya no podemos confiar en la cencia. Ni en la estadística. ¡Ven ya, meteorito!

Y… no, mira. Creo que esta es una mala interpretación de este resultado. No me refiero tanto al comentario de esta persona, que salvando lo de “scary”, que sí es un juicio de valor, no está sino describiendo el hallazgo, sino a la reacción bastante alarmista de muchos tuiteros, que algunos casi estaban proponiendo que la ciencia es toda una sarta de mentiras. Es que incluso en el paper mismo hablan de fuentes de variabilidad como “sesgos” (principalmente el sesgo de confirmación). Vamo a calmarno.
Por un lado, tengamos en cuenta que los datos suministrados en este estudio eran bastante ambiguos, que las hipótesis propuestas a los equipos de investigación eran muy vagas y permitían distintos enfoques… Pero es que aun así este resultado no tiene nada de sorprendente, e incluso, si me apuras, nada de malo.
Y es que al decidir usar un modelo estadístico u otro, o al decidir si vas a transformar tu variable dependiente… estás tomando decisiones que es lógico y deseable que afecten al resultado. ¡Pero si las tomas precisamente por eso! Porque crees que te ayudarán a capturar mejor la información que estás buscando. Son decisiones que, en mi opinión, simplemente hay que exponer y justificar con transparencia (lo cual, eso sí te lo admito, rara vez hacemos).

Pero es verdad que hay toda una corriente que aboga por reducir el impacto (si es que eso es posible) de estas decisiones, para reducir el sesgo que producen. Somos humanos, dicen, cometemos errores. Y somos “subjetivos”. Así que eliminemos o reduzcamos el factor humano de la ecuación. Así, el director de tesis de nuestro ejemplo propone “dejar hablar a los datos”, como si fueran una entidad con voluntad y capacidad de expresarse. Otros llevan esta idea al extremo y podrían, por ejemplo, usar algoritmos de machine learning para aprender automáticamente de tu set de datos: qué variables extraigo, qué variables tienen qué papel, qué combinación produce el mejor ajuste… Sin ir tan lejos, hay gente que propone que sólo los matemáticos o los estadísticos experimentados analicen los datos de los estudios, bajo la premisa de que ellos o ellas saben “cuál es la manera correcta” de analizar los datos, mientras que el experto o experta en el tema, que ha planeado el estudio y ha recogido los datos, no sabría tomar estas decisiones sin contaminar el resultado y por eso hay que dejarlo fuera.
De manera más general, Judea Pearl expone en su libro The Book of Why (Pearl & Mackenzie, 2018) algunos argumentos que van contra esta corriente que podríamos llamar “dirigida desde los datos” o (“data-driven”). De manera convincente, Pearl nos dice que lo llevamos claro si pretendemos analizar los datos sin tener una teoría acerca del proceso que los ha generado. Tu conocimiento previo del problema, de la situación de medida, etc., te va a ayudar a decidir qué tipo de modelo y de supuestos debes incluir en tu análisis. Y eso no te lo dicen los datos por sí solos.
Como en este blog somos amantes de R y de las simulaciones, vamos a simular unos cuantos datos para entender tres situaciones en las cuales nuestro conocimiento previo es *crucial* para no meter la pata. Se trata de la confusión de variables, la colisión de variables (lo siento, no sé cómo traducir “collider” 👉👈), y la mediación.
Caso 1. Confusión de variables
Vamos a poner un ejemplo tan simple que lo entienda cualquiera. Imagina que estás interesado/a en las habilidades lectoras de los niños y adolescentes, así que te vas a un colegio y les haces una prueba de habilidad lectora a todos los estudiantes de entre los 7 y los 17 años. Además, como eres un investigador/a concienzudo/a, vas a recoger un montón de otras variables, incluyendo parámetros físicos (estatura, peso, edad…).
Y entonces, bajo la premisa de que “es mejor dejar hablar a los datos”, decides explorar a lo loco ese archivo inmenso, y calculas una tabla TERRIBLE (como argumenté en otro post), gigantesca, con todas las correlaciones que resultan de cruzar entre sí todas las variables. Vamos, unos quinientos coeficientes de correlación, por lo menos. Y te llevas una sorpresa. Pues oye, ¿que no resulta que la talla del zapato correlaciona significativamente con la habilidad lectora? Ouch.
Claro, ante esta observación podríamos tomar dos posturas. La primera es interpretar esa correlación de forma causal, y pensar de qué manera podemos obligar a los niños pequeños a usar zapatos más grandes para así mejorar su habilidad lectora. La segunda, más sensata, es plantearnos que esto no tiene ningún sentido. ¿De dónde ha salido esta correlación, aparentemente espuria?
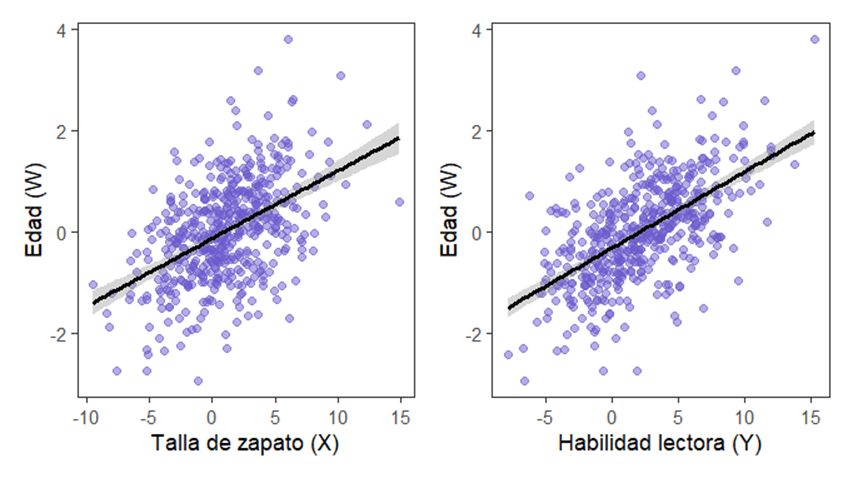
Pues lo que decía antes. Vamos a usar el selebro, y nuestro conocimiento previo sobre el mundo. ¿Por qué deberían correlacionar talla de zapato y lectura? Una posibilidad es que ambas variables sean en realidad consecuencia de una misma causa, la edad. Con la edad, los niños crecen y con ellos sus pies. También con la edad, y los años acumulados de experiencia escolar, mejoran sus habilidades lectoras. Como vemos en este gráfico (*):

En este caso, nuestra conclusión sería que probablemente la edad es una variable confundida que explica la correlación (seguramente espuria) entre talla de zapato y habilidad lectora. Esto quiere decir que mi análisis de correlación debería controlar esa variable confundida (edad) para revelar realmente la asociación entre las otras dos variables.
Vamos a empezar con las simulaciones, que me duermo. Para abrir boca, voy a generar tres variables a partir de una distribución normal. Según el modelo del gráfico, tanto X (talla) como Y (lectura) son consecuencias de una causa común, la variable confundida W (edad), así que las genero a las dos linealmente a partir de esta última, usando la ecuación clásica de un modelo de regresión con coeficientes que me invento sobre la marcha.
set.seed(200)
n <- 500 # Vamos a generar 500 datos…
W <- rnorm(n, 0, 1) # Variable confundida (edad)
X <- 1 + 1.5*W + rnorm(n, 0, 3) # Variable predictora (talla de zapato)
Y <- 2 + 2.1*W + rnorm(n, 0, 3) # Variable dependiente (habilidad lectora)
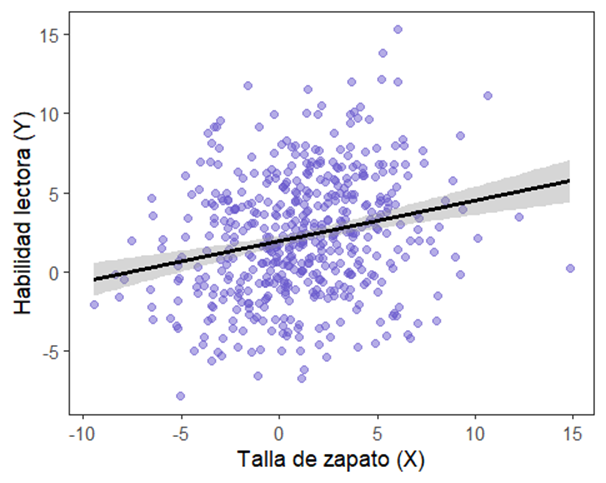
Podemos ver cómo X e Y correlacionan en mi set de datos, lo cual me había alarmado inicialmente:
summary(lm(Y~X))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.9333 0.1755 11.014 < 2e-16 ***
X 0.2553 0.0482 5.296 1.78e-07 ***
¿Lo veis? La talla de calzado correlaciona con la lectura, p < 0.05.
Pero claro, es que ambas correlacionan, cada una por su parte, con su causa común, la variable confundida W 🤔
Entonces, dado que hemos usado nuestro conocimiento previo para identificar una variable confundida en nuestros datos, lo que tenemos que hacer es controlar su efecto en nuestro análisis. ¿Cómo? Introduciendo esta variable (edad, W) en el modelo:
summary(lm(Y~X+W))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.24240 0.14601 15.358 <2e-16 ***
X -0.07884 0.04526 -1.742 0.0822 .
W 2.50843 0.16304 15.385 <2e-16 ***

Como veis, en este nuevo análisis que controla la edad ya no hay una relación significativa entre talla de zapato y habilidad lectora (<respira aliviado>). Y esta sería la interpretación correcta, eso sí, suponiendo que mi modelo de la figura de arriba (el gráfico que trata la edad como variable confundida) sea cierto.
Caso 2. Sesgo de colisión (“collider bias”)
Vamos con otro ejemplo clásico. Inteligencia y atractivo físico son dos atributos que pueden llevar al éxito a una persona. Podríamos pensar, en principio, que ambos atributos ocurren de manera bastante independiente (el ser más o menos inteligente no afecta al atractivo, así es la lotería de la genética, amigos). En cualquier caso, ambos atributos pueden producir el mismo resultado, que es el éxito en la vida: tanto las personas muy atractivas como las muy inteligentes tienen más papeletas para triunfar. Vamos a representarlo gráficamente:

Ahora bien, imagina que tomamos una muestra de actores y actrices de Hollywood que han triunfado en su carrera y conseguido muchos premios. Y para cada uno de estos sujetos obtenemos tanto un test de inteligencia como una puntuación de atractivo físico. Como mi agenda de estrellas de Hollywood para realizar estudios es algo escasa, mejor vamos a simular los datos. Así generamos tres variables, X (atractivo), Y (inteligencia) y Z (éxito):
set.seed(200)
X <- rnorm(n, 0, 3)
Y <- rnorm(n, 0, 3)
Z <- 1.6 + 1.2*X + 0.9*Y + rnorm(n, 0, 3) #collider
dataset <- data.frame(X, Y, Z)
Hemos dicho que queremos examinar participantes que ya han demostrado su éxito (son estrellas reconocidas), así que podemos seleccionar solo los valores más altos de Z (éxito). Esto lo hacemos en el siguiente paso, que elimina de nuestra matriz de datos todos los casos con valores de éxito negativos (los que no han conseguido premios, los que llevan tiempo sin protagonizar un taquillazo…).
conditionalZ <- dataset[!(dataset$Z<0)] # con esto elimino del data set todos los casos con éxito negativo.
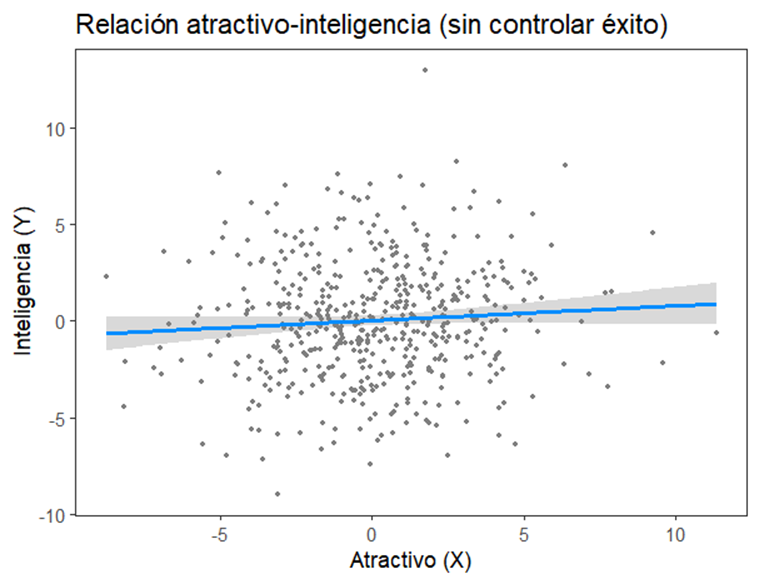
Y ahora, tras esta selección de datos, examinamos la correlación entre atractivo e inteligencia…
summary(lm(conditionalZ$Y~conditionalZ$X))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.1760 0.1810 6.498 3.15e-10 ***
conditionalZ$X -0.2049 0.0643 -3.186 0.00158 **
…Y entonces empiezan a no salirnos las cuentas. Porque analizando los datos compruebo, con estupor, que cuanto menos atractivo eres, más inteligente. ¿Veis cómo la correlación es negativa? Y el resultado es significativo, p < 0.05. ¿Cómo puede ser esto? ¿Habremos descubierto una nueva teoría genética? ¿Será verdad el cliché de que los empollones son feos, y los guaperas tontos del bote? Lo dudo. De nuevo no tiene sentido tomar en serio esta correlación.
Y es que, mirando la estructura que hemos dibujado arriba y que deriva de nuestro conocimiento previo del mundo, caemos en la cuenta de que Z es la consecuencia común de X e Y. En términos estadísticos, esta variable es un “colisionador” (¿veis cómo confluyen en el gráfico las flechas causales?) que puede interferir en nuestra inferencia sobre las otras dos variables.
El problema es que nuestra selección de casos hemos filtrado la muestra para quedarnos solo con las personas de mayor éxito, y por eso estamos distorsionando la relación observada entre las variables inteligencia y atractivo. Al eliminar los casos con valores más bajos de Z estamos también eliminando valores de las otras variables… pero de forma sistemática, introduciendo un sesgo.
Esto significa que, cuando hemos identificado una variable “de colisión” (“collider”), no debemos condicionar el análisis en esa variable. Es decir, no debemos seleccionar la muestra en función de Z, y *tampoco* intentar controlar Z metiéndola en el modelo. ¿Queréis comprobarlo? Pues venga, que hacer simulaciones es gratis. El siguiente análisis, con la muestra completa (es decir, sin eliminar los casos de menor éxito), está controlando el éxito al medir la relación atractivo-inteligencia:
summary(lm(Y~X+Z))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.83541 0.11661 -7.164 2.84e-12 ***
X -0.58339 0.05162 -11.302 < 2e-16 ***
Z 0.48519 0.02674 18.143 < 2e-16 ***
Y entonces sale a la luz esta relación atractivo-inteligencia, que es significativa (p < 0.05), que no sabemos cómo interpretar y que probablemente es un artefacto. Bueno, en este caso, como los datos son simulados, lo podemos confirmar: es un artefacto 😈.
Como veis, al controlar por Z aparece esa correlación espuria que no está presente cuando sacamos esa variable del modelo. Es una correlación engañosa, sin sentido. En este caso, el modelo correcto sería claramente este, el que examina la relación X-Y sin ningún otro predictor ni control (insisto, todo esto si damos por bueno el modelo de la figura de arriba, que trata a X y Z como causas independientes de Y).
summary(lm(Y~X))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.03366 0.13693 0.246 0.806
X 0.07607 0.04721 1.611 0.108
Moraleja: si identificas una variable de este tipo (un “collider”), no se te ocurra controlarla en el modelo estadístico, porque es un error.
Caso 3. Variables mediadoras
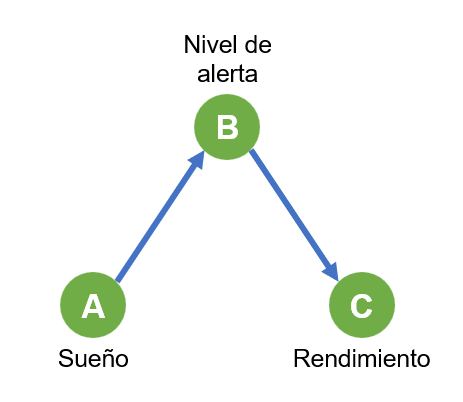
Y nos queda el tercer ejemplo en discordia. Sabemos que la calidad del sueño puede afectar al rendimiento en el trabajo. Los días que no has dormido bien son como un capítulo de The Walking Dead. Sin embargo, podríamos pensar que esta influencia no es directa, sino que hay otro factor relevante: el nivel de alerta. Porque claro, a veces puede que hayas descansado como un bebé, pero si no te has tomado el café en el desayuno es posible que tampoco des pie con bola, ¿no? Diríamos que la calidad del sueño es la causa distal del rendimiento, y el nivel de alerta es más proximal. Algo como esto:
Pues como somos cientefecos vamos a recoger unos cuantos datos. Medimos la calidad del sueño con un cuestionario, el nivel de alerta mediante una prueba conductual de atención, y el rendimiento laboral según una serie de indicadores que hemos elegido. Pues bien. Generemos esos datos:
set.seed(500)
A <- rnorm(n, 0, 3) # Calidad del sueño
B <- 0.7*A + rnorm(n, 0, 3) # Nivel de alerta
C <- 0.5*B + rnorm(n, 0, 3) # Rendimiento laboral
Según lo que hemos explicado, sería esperable que los días que peor hemos dormido tengamos un rendimiento más bajo, ¿no? Pues miremos los datos. Vamos a probar un modelo que examina el efecto de la calidad del sueño (A) sobre el rendimiento (C), controlando el nivel de alerta (B). Oh shit!
summary(lm(C~A+B))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.13893 0.12818 -1.084 0.279
A -0.05057 0.05117 -0.988 0.323
B 0.57940 0.04346 13.332 <2e-16 ***
Lo que nos sugiere el modelo es que el nivel de alerta afecta al rendimiento… Pero la calidad del sueño no lo hace (p = 0.323). ¿Cómo puede ser?
Entonces reparamos en un pequeño detalle, y lo tienes en la figura de arriba. Las tres variables forman una cadena, es decir, lo que estamos describiendo es un modelo mediacional (Kenny, 2021). Así que, para ver el efecto de A sobre C, no tenemos que condicionar en B, ni intentar controlar B. Tendríamos que sacar esa variable del modelo. Así:
summary(lm(C~A))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.23133 0.14898 -1.553 0.121
A 0.33969 0.04885 6.954 1.12e-11 ***
Ahora sí tiene sentido el resultado. Parece que la calidad del sueño afecta al rendimiento significativamente, p < 0.05. Y es el resultado que tiene sentido interpretar… pero insisto otra vez: ¡eso dando por bueno el modelo que hemos descrito en el gráfico que supone una estructura mediacional y no de otro tipo!
El drama
En todos estos casos, hemos podido hacer un análisis que nos lleva a conclusiones absurdas o poco útiles. No sé si podríamos decir que esos análisis de los ejemplos (controlar un mediador o un collider en el modelo, no controlar una confundida) son “incorrectos”, o simplemente lo que ocurre es que nos están dando una respuesta (probablemente válida) a una pregunta que ni nos interesa ni nos queríamos plantear. Así que como mínimo pueden producir errores y confusiones al interpretarlos. Pero, y aquí está el asunto clave, la única manera de determinar cuál es el análisis que nos interesa consiste en examinar muy bien la situación en la que se recogen los datos, tener al menos una teoría de cómo ha sido ese proceso… y entonces decidir qué factores deben incluirse en el modelo y cuáles no. Para ello, nos puede ayudar dibujar gráficos “causales” de nodos y flechas como los de este post (que se llaman DAG y se usan mucho en inferencia causal e inteligencia artificial).
Seguro que os estáis anticipando a lo que iba a decir: ¿esto no abre la puerta a la subjetividad? Pues mira, no sé si a la subjetividad, pero seguramente permite que haya diferencias de criterio. Un ejemplo famoso lo cita el propio Judea Pearl en su libro. Ronald Fisher, famoso estadístico, era además un aliado infalible de la industria tabaquera (Stolley, 1991).
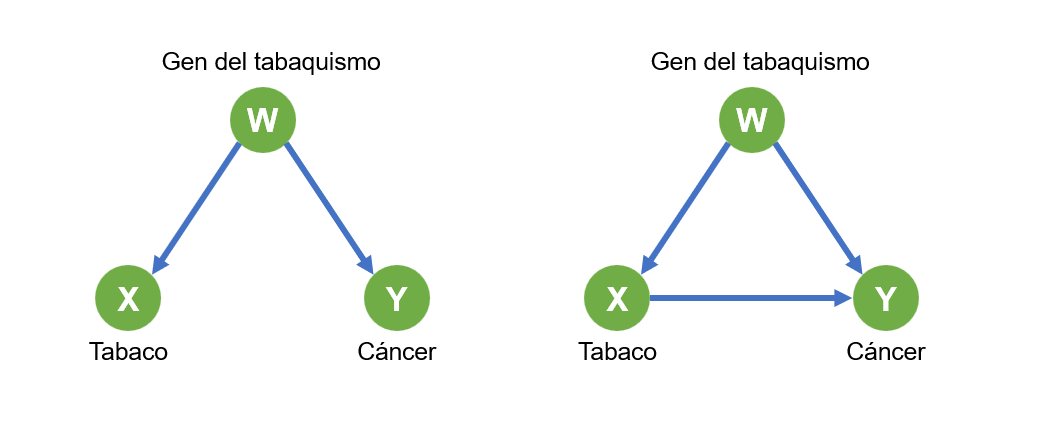
En 1950-1960, había ya una cantidad enorme de datos como para sospechar que fumar tabaco produce problemas de salud como el cáncer de pulmón. Sin embargo, algunos críticos de esta teoría, como el propio Fisher, se agarraban a un clavo ardiendo proponiendo, por ejemplo la existencia de un factor subyacente, “el gen del tabaquismo”, que produciría, por un lado, mayor tendencia a desarrollar el hábito de fumar, y por otro lado mayor peligro de tener un cáncer de pulmón. Usando los gráficos que tan útiles nos han resultado en este post, veríamos el modelo a la izquierda de la siguiente figura. Claro que los detractores de Fisher tenían otro modelo en mente: sí, quizá exista ese “gen del tabaco”, pero la relación entre fumar y cáncer de pulmón no es espuria, sino causal (modelo de la derecha). Así que distintos expertos parecen tener distintos modelos y por lo tanto realizan diferentes análisis.
Conclusiones
La moraleja de este post es que, más que llevarse las manos a la cabeza por que los analistas tengan cierto grado de libertad a la hora de proponer modelos o examinar los datos, habría que aceptarlo como algo no solo inevitable, sino como una necesidad: sencillamente no puedes decidir cuál es el modelo estadístico que más encaja con tu pregunta sin tener clara esa pregunta, y sin tener una idea de los procesos que generaron los datos.
Esto implica varias cosas:
- Que soy bastante escéptico (¡por ahora!) de las propuestas para usar algoritmos automáticos de inteligencia artificial para “sacar el mayor rendimiento de los datos”. Me parece que en algunos casos nos pueden inspirar ideas, a modo exploratorio, pero luego habría que hacer estudios bien diseñados para confirmarlas o refutarlas. No podemos interpretar los datos sin tener alguna “teoría” o pista que nos ayude a darles sentido. Ya digo: por ahora.
- Lo siento por el profesor y la doctoranda del ejemplo, pero no creo que haya una “única” manera correcta de analizar los datos en un estudio concreto. Dependerá de cuál sea la pregunta que nos queremos hacer, y también (¡anatema!) de las asunciones y supuestos y creencias que tengamos acerca del proceso que ha generado los datos. Si yo he leído mucho, y por eso lo tengo clarísimo, y sé que una determinada variable es probablemente una confundida, pues entonces tendré que controlarla en el modelo. La de veces que habremos hecho análisis totalmente absurdos e inútiles porque “lo ha pedido un revisor” que cuñadea y que no es ni siquiera experto en el campo. Cosas como controlar el género o la edad en un análisis cuando realmente no son variables confundidas.
- También soy limitadamente escéptico hacia algunas propuestas que se escuchan a veces sobre la necesidad o conveniencia de que expertos analistas (matemáticos, estadísticos) se encarguen del análisis de datos en los proyectos de investigación o las tesis, en vez de los propios investigadores. A ver, depende de qué rol tenga el analista en el proyecto, y también de su nivel de implicación, de si va a estar presente en todo el proceso, ya desde el diseño… Si el analista es meramente una especie de consultor al que le mandas los datos, los analiza y te devuelve in informe con las conclusiones, ¡ojo! Y es que, como estoy argumentando, quien hace la pregunta de investigación es quien decide el modelo que debe ponerse a prueba, y para eso hace falta conocimiento de dominio. Podría ser que el estadístico te esté dando una respuesta a una pregunta que no te interesa. Si tu tesis es de psicología, para plantear un buen análisis hay que ser experto o experta en ese tema. O transmitirle ese conocimiento al analista, claro, pero eso es probablemente mucho más difícil que traducir lo que los expertos ya sabemos de nuestro tema de investigación a una pregunta concreta que podamos formular en el análisis. Creo sinceramente que el mejor análisis para tu estudio solo lo puedes proponer tú, que eres quien sabe más del tema.
- No necesariamente estoy hablando de incorporar la subjetividad al análisis, ¡a pesar de que mucha gente lo interpreta así! (y de hecho es la crítica común en artículos como el que citamos arriba). Decisiones como clasificar una variable como mediadora o confundida se pueden basar en evidencia, en datos, en teoría… Que haya distintos modos de interpretar esa evidencia, o que le demos distintos pesos a piezas de evidencia que a veces son contradictorias, de forma que al final tengamos propuestas de análisis diferentes según quién lo está planteando, ¿se puede llamar subjetividad? Pues igual hay que perderle el “miedo” a esa palabra. Para mí es más importante que las decisiones estén bien justificadas y de forma transparente, para que se puedan debatir diferentes puntos de vista: “venga, arguméntame por qué crees que esta variable es mediadora y así justificas tu decisión de no controlarla”. Curiosamente, pocos artículos leo donde de verdad esto se lo tomen en serio y te expliquen con transparencia todas las decisiones que han tomado en el modelado.
- Sí que hay tradiciones o aproximaciones al modelado que incorporan todo esto. Por ejemplo la gente que diseña modelos generativos en la tradición Bayesiana hace exactamente lo que hemos explicado: piensan en la situación donde se recogieron los datos para modelarla al detalle, definen las variables que pueden afectar a esa situación y describen el proceso generativo de los datos mediante distribuciones de probabilidad. Claro, para hacer este trabajo de modelado hay que combinar el conocimiento estadístico con el conocimiento de tu tema de investigación. Nadie dijo que fuera fácil.
(*) Este tipo de gráficos se llaman DAGs (Directed Acyclic Graphs) y se usan un montón en inferencia causal.
Referencias
- Breznau, N., Rinke, E. M., Wuttke, A., Adem, M., Adriaans, J., Alvarez-Benjumea, A., Andersen, H. K., Auer, D., Azevedo, F., Bahnsen, O., Balzer, D., Bauer, G., Bauer, P. C., Baumann, M., Baute, S., Benoit, V., Bernauer, J., Berning, C., Berthold, A., … Nguyen, H. H. V. (2021). Observing Many Researchers Using the Same Data and Hypothesis Reveals a Hidden Universe of Uncertainty. MetaArXiv. https://doi.org/10.31222/osf.io/cd5j9
- Pearl, J., & Mackenzie, D. (2018). The Book of Why: The New Science of Cause and Effect. Basic Books.
- Stolley, P. D. (1991). When genius errs: R.A. Fisher and the lung cancer controversy. American Journal of Epidemiology, 133(5), 416-425; discussion 426-428. https://doi.org/10.1093/oxfordjournals.aje.a115904
